Time Series Compression Algorithms and Their Applications
In this article, learn more about time series compression algorithms along with their role in real-world applications in different sectors.
Join the DZone community and get the full member experience.
Join For FreeThis is an article from DZone's 2022 Database Systems Trend Report.
For more:
Read the Report
Time series is present in our daily lives in multiple sectors of society, such as finance, healthcare, and energy management. Some of these domains require high data volume so that insights from analysis or forecasting the behavior of target variables can be obtained. Transferring and processing high data rates and volume across platforms with several users requires storage and computer power availability. Compression techniques are a powerful approach to avoid overwhelming systems. In what follows, time series compression algorithms will be discussed along with their role in real-world applications in different sectors.
What Is Time Series?
Time series is defined as a sequence of values of a quantity obtained at successive times, often with equally spaced intervals. We experience the use of timestamped data from when we monitor our exercises with a fitness app to when we track our pizza delivery traveling through the city all the way to our doorstep. Time series is relevant to problems when understanding the evolution of a variable over time is needed, such as understanding the time profile of a variable or forecasting their values.
Time series most commonly appear in the form of timestamped numerical data in a tabular format. Audio data itself is already represented as a time series, as it is defined in terms of frequencies. However, although time series are themselves a data type, they can also be combined with other data types in order to produce more complex entities, which contain an embedded temporal aspect such as:
- A sequence of images over time defines a video.
- A time series of coordinate pairs from geospatial data defines a tracking path.
Time series data requires specific techniques in order to obtain insights not only from the different patterns in data, but also among those over time. In a data science pipeline, these techniques are employed during the preprocessing, analysis, and modeling steps. The most common time series techniques are illustrated in Figure 1 below:
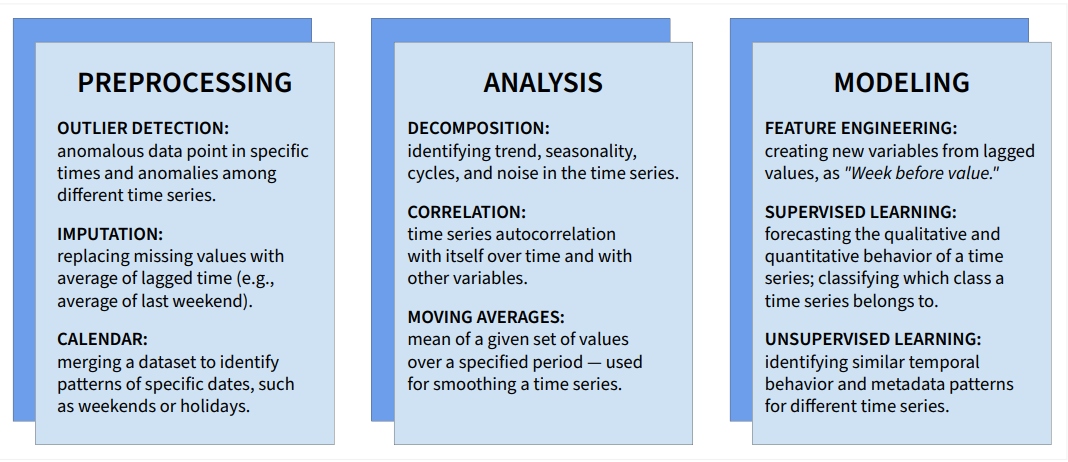
Figure 1: Time series methods
Data Compression
Data compression is the process of transforming data in order to reduce the number of bits necessary to represent it. This process is done via the alteration of the data through encoding or the rearrangement of its bits structure. Compression is a valuable technique utilized in scenarios where resources are crucial for storage, processing, and transmission of data. Two extremes of such scenarios are:
- Limited resources scenario, where the available storage and processing are limited by costs
- Big data scenario, where a high-frequency data influx requires efficient data management
The process of data compression involves encoding the data into a smaller format. In order to perform the reverse process, a decoder is needed to decompress the data, as illustrated in Figure 2:
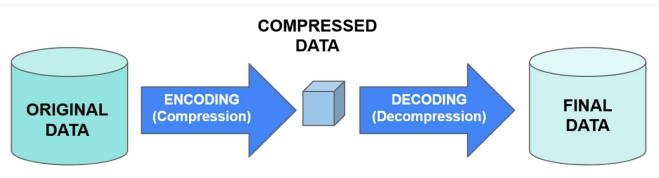
Figure 2: Data compression scheme
Compression expresses the same information present in the data in a smaller format with less bits. Since it searches for patterns in data that can be encoded, it is a computationally expensive procedure that may demand time and memory. State-of-the-art compression techniques are:
- Lossless compression identifies and removes data redundancyin a way that no information is lost in the process. The decoded data is restored exactly to its original state.
- Common uses: databases, emails, spreadsheets, documents, and source code
- Lossy compression identifies and permanently removes redundant data bits, not making it possible to recover the original data after decompression.
- Common uses: audio, images, graphics, videos, and scanned files
The trade-off between accuracy and compression, present in the attempt to preserve the data while still addressing the storage bound, is an often-encountered challenge in data compression. Lossless data compression can only shrink data to a certain extent, having Shannon’s information as a threshold. For high-frequency data, lossy compression is needed in order to perform an effective reduction in size.
Table 1:
|
ADVANTAGES AND DISADVANTAGES OF DATA COMPRESSION
|
|
|---|---|
| Advantages of Compression | Disadvantages of Compression |
| Reduction of file size and storage usage costs | Time-consuming for large data volume |
| Increase data reading/writing speed due to the reduction of memory gaps during disk storage | Algorithms need intensive processing from the system, which becomes costly for large data volume |
| Faster file transfer via the internet, requiring less computational resources | Quality of decompressed data may depend on level of compression |
| Algorithms can be used to approximate and/or predict the data, as well as identify noise | Requires a decoder program in order to decompress the files |
Compression Methods for Time Series
The rise of big data and use of smart devices reveal a demand for powerful compression techniques able to fulfill the processing needs of industries that rely on time series data. In the case of high frequencies (around 10kHz), even databases that specialize in time series data can get overloaded. Compression algorithms are widely explored due to their high-value returns. The quality of a compression technique is measured by its compression ratio (between compressed and original files), speed (measured in cycles per bite), and the accuracy of the restored data.
Time series compression algorithms take advantage of specific characteristics in time series produced by sensors — such as the fact that some time series segments often repeat themselves in the same or other related time series (redundancy), or the possibility to recover a time series via approximating it by functions or predicting them through neural network models. The state-of-the-art methods are listed below:
Table 2:
TIME SERIES COMPRESSION ALGORITHMS |
|||
|---|---|---|---|
| Algorithm | Description | Common Methods | Performance |
| Dictionary-based |
|
|
|
| Function approximation |
|
|
Suitable for smooth time series, low compression ratios, and high accuracy. |
| Sequential algorithms |
|
|
|
| Autoencoders |
|
Recurrent Neural Network Autoencoder (RNNA) methods consider a time-dependent neural network that has a lossy compression and a loss threshold parameter. | Accuracy and compression ratio depend strongly on the ability of the RNN of finding patterns in the training set. |
Time Series Applications
The compression algorithm to be chosen for a certain problem depends on the domain of the application and data in question. Applications of compression can be found in many sectors, with multimedia through the compression of images, video, and audio data being the most popular. In particular, time series compression is used in crucial industries. Time series use cases in different sectors and the highlights on compression in such applications are shown in Table 3. In all use cases, the advantages presented in Table 1 are also applicable.
Table 3:
| TIME SERIES USE CASES | ||||
|---|---|---|---|---|
| Medicine | Maintenance | Energy | Economics | |
| Use case | Monitoring of multiple life signals of patients integrated into a warning system to guarantee full time assistance. | Monitoring of industrial equipment and further automated report of equipment status, ensuring safety and efficient production. | Short-term forecast of energy consumption by smart meters. | Data collected at high frequencies reports the status of stock market statistics in real time. |
| Compression added value | Faster data processing for performing calculations, such as triggering warnings. | Easier and cheaper storage of large data volumes, making it affordable for manufacturing companies to adopt data-driven solutions. | Encoding algorithms help gather insights from the data, like noise and behavior, making more accurate forecasts. | Faster transmission of information through a large network, permitting users to make decisions in real-time. |
Conclusion
We live in the era of big data, where over 250 exabytes of data are produced every day, from which a large portion is present in the form of time series in a broad range of industries (note: 250 exabytes = 250×10 to the 18th power). Time series compression techniques are a powerful approach to efficiently collect, store, manipulate, and transfer data, which is crucial for database maintenance and the implementation of robust data management pipelines.
The great adoption of smart devices has also increased the need for compression techniques that are suitable for scenarios of low computational resources, as in IoT. This article presented both lossy and lossless techniques that are suitable for multiple time series profiles and applications scenarios and discussed the limitations and strengths of such methods.
This is an article from DZone's 2022 Database Systems Trend Report.
For more:
Read the Report
Opinions expressed by DZone contributors are their own.
Comments