From Stream to Strategy: How TOON Enhances Real-Time Kafka Processing for AI
The TOON data format specifically targets the propagation of structured, validated, and semantically consistent data, thereby reducing ambiguity in real time.
Join the DZone community and get the full member experience.
Join For FreeAI agents now increasingly require real-time stream data processing as the environment involving the decision-making is dynamic, fast-changing, and event-driven. Unlike batch processing, which is how traditional data warehouses and BI tools work, real-time streaming enables AI agents to analyze events as they happen, responding instantly to fraud, system anomalies, customer behavior shifts, or operational changes.
In competitive and automated environments, a matter of seconds can make the difference between an accurate decision and one that is off by miles, a risk not many organizations are willing to take. Continuous data streams are also key to enabling AI agents to adjust and adapt to emerging patterns, observe trends in real time, and refine predictions on the fly rather than making decisions based on stale snapshots. As with other automation systems that rely on increasingly intelligent agents (usually AI/ML) over time, real-time stream processing ensures that AIs remain responsive and context-aware, enabling them to make timely, high-impact decisions.
What and Why the TOON Data Format Is Better for AI Agents
TOON stands for Token-Oriented Object Notation, a lightweight, line-oriented data format. It is too human-readable (more than binary formats), like JSON, but more compact and structured than raw text. TOON is built to be very simple to parse, where each line or “entry” begins with a token header (uppercase letters or digits), then uses pipe separators (|) for fields. Given the importance of streaming environments, it is optimized to be line-oriented, and we do not need to build a full in-memory parse tree (unlike JSON), which makes it suitable for low-memory contexts, embedded systems, or logs.
The TOON data format specifically targets the propagation of structured, validated, and semantically consistent data, reducing ambiguity during real-time decision-making for both AI agents in mind. AI agents rely on well-defined features, correctly typed data, and accurate metadata (like timestamps, event types, or correlation IDs) to yield precise outputs. TOON requires adherent deserialization and enforces schema discipline with version control, so incoming data stays predictable, no matter how the systems themselves evolve. This reduces preprocessing complexity, minimizes runtime errors, and avoids potential misinterpretation of features, which is a common risk.
Additionally, the traceability and model explainability that are critical in AI-driven environments are significantly improved due to TOON’s standardized organization of payload and contextual information. TOON enhances the reliability, performance, and scalability of AI agents operating in real-time systems by delivering clean, governed, and machine-friendly data. 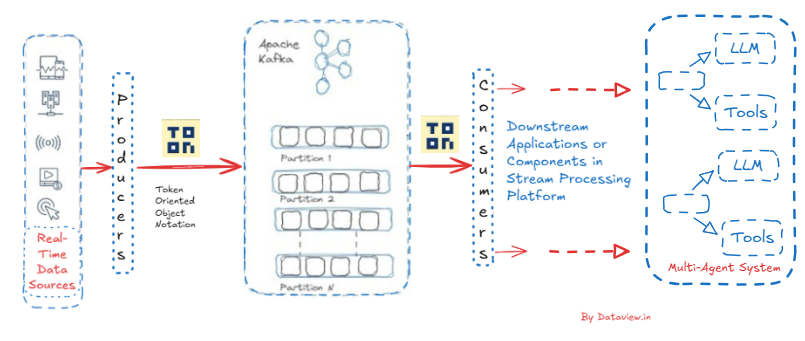
Where Apache Kafka Fits In
In a stream-processing platform where millions of events per second must be handled with low latency, ingestion systems such as Apache Kafka can be leveraged to provide continuous input (data/events) for AI agents that work with real-time data. Apache Kafka can serve as a scalable, reliable, and quick streaming backbone to ingest new fast-moving event streams into the AI agents so that they can deliver desirable decisions/choices.
Kafka’s distributed architecture ensures durability, horizontal scalability, and high throughput even under heavy loads. It uses a system where many AI models can use the same real-time data on their own. This lets different decisions happen at once, models be compared, and learning keep going without messing up systems further up the chain. By using the publish–subscribe model of Apache Kafka, multiple AI models can consume the same real-time data independently and eventually enable parallel decision-making, model comparison, and continuous learning without disrupting upstream systems.
Besides, Kafka's replay capabilities and message ordering within partitions enable AI agents to retrain, backtest, or recover from errors using saved streams from streaming databases. Kafka guarantees that AI-driven systems can respond quickly, learn continuously, and scale without interruption in dynamic, data-intensive contexts by acting as a robust event pipeline.
Why TOON in Apache Kafka
To build or develop such a platform or architecture where processed streaming data eventually feeds into AI systems like TensorFlow, etc, TOON provides several key advantages over JSON. Specially for large language models (LLMs), where JSON is considered to be heavyweight for data exchange because of thousands of tokens in quotes, braces, colons, and repeated keys. Using TOON, we can reduce 30–50% fewer tokens for uniform data sets, and it has less syntactic clutter, which makes it easier for LLMs. Besides, TOON can be nested, similar to JSON. Similar to JSON, TOON can have a simple object, an array of values, an array of objects, and an array of objects with nested fields. In case of an array of objects with nested fields, TOON can be excellently understandable, as well as much smaller than the JSON format. TOON is a token-efficient serialization format that is primarily designed for streaming, low-memory environments, and LLM contexts.
We can list down the following advantages of formatting Apache Kafka messages in TOON instead of plain JSON.
- JSON often mixes metadata and payload without enforced separation, but in TOON, we can clearly separate headers and business payload.
- TOON can support compact binary encoding that eventually reduces message size compared to verbose JSON.
- TOON specification follows semantic versioning to ensure compatibility.
- Better data validation as TOON enforces strict field validation rules.
- TOON declares the schema once, then provides just the values in a clean tabular format.
- Interoperability can be improved in Enterprise Systems because of a consistent structure across microservices.
- Because of stronger type safety in TOON, enforced data types reduce runtime errors.
Wrapping Up
TOON is a new data serialization format that is designed to reduce or minimize the number of tokens when exchanging structured data primarily with language models. Although primarily beneficial in LLM-specific pipelines, we can use it to ingest stream data into an Apache Kafka topic, as it’s a compact, token-efficient serialization format. TOON is not Kafka-native and still relatively young compared to JSON, Avro, or Protobuf.
As TOON is not widely supported yet, we may need to write custom serializers/deserializers while integrating with existing message producers and consumers for downstream applications or components across the entire stream processing platform. If we are especially concerned with efficient parsing and minimizing overhead, then TOON could be a very well-suited message payload format for Apache Kafka. Together, TOON and Kafka provide a powerful foundation for building responsive, resilient, and future-ready streaming solutions.
Thank you for reading! If you found this article valuable, please consider liking and sharing it.
Published at DZone with permission of Gautam Goswami. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments