Is TOON a Boon for AI Communication, LLM Token Cost Economics?
Token costs are bottlenecking AI systems. Learn how TOON, a token-oriented format, cuts LLM costs and boosts efficiency at scale for high-volume pipelines.
Join the DZone community and get the full member experience.
Join For FreeModern AI systems are hitting a new kind of bottleneck. It is not CPU, memory, or network bandwidth. It is tokens.
With large language models (LLMs), every character sent and received is tokenized, processed, and billed. At a small scale, this cost is easy to ignore. At enterprise scale, it becomes a first‑order architectural concern. This shift is driving interest in formats designed specifically for AI communication, such as TOON (Token‑Oriented Object Notation).
In this article, I will try to explain the following:
- What problem TOON solves
- Where it fits
- Why it matters for engineers building high‑volume AI systems
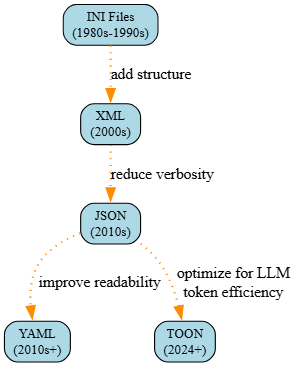
The Evolution: From INI to TOON
Data Formats Were Never Built for LLM Economics
Data serialization formats have always evolved to match system constraints.
- INI files worked for simple configuration, but did not scale.
- XML introduced structure and self‑description, enabling early web services...but at extreme verbosity cost.
- JSON reduced noise, improved readability, and became the default for APIs and microservices.
- YAML optimized for human readability and configuration, but added parsing complexity.
None of these formats was designed for systems where the cost of communication itself is measurable, recurring, and directly billed. LLMs changed that assumption.
TOON: Token-Oriented Object Notation is machine-efficient and schema-readable, not optimized for ad-hoc human inspection. It's intended for LLM input as a drop-in, lossless representation of your existing JSON.
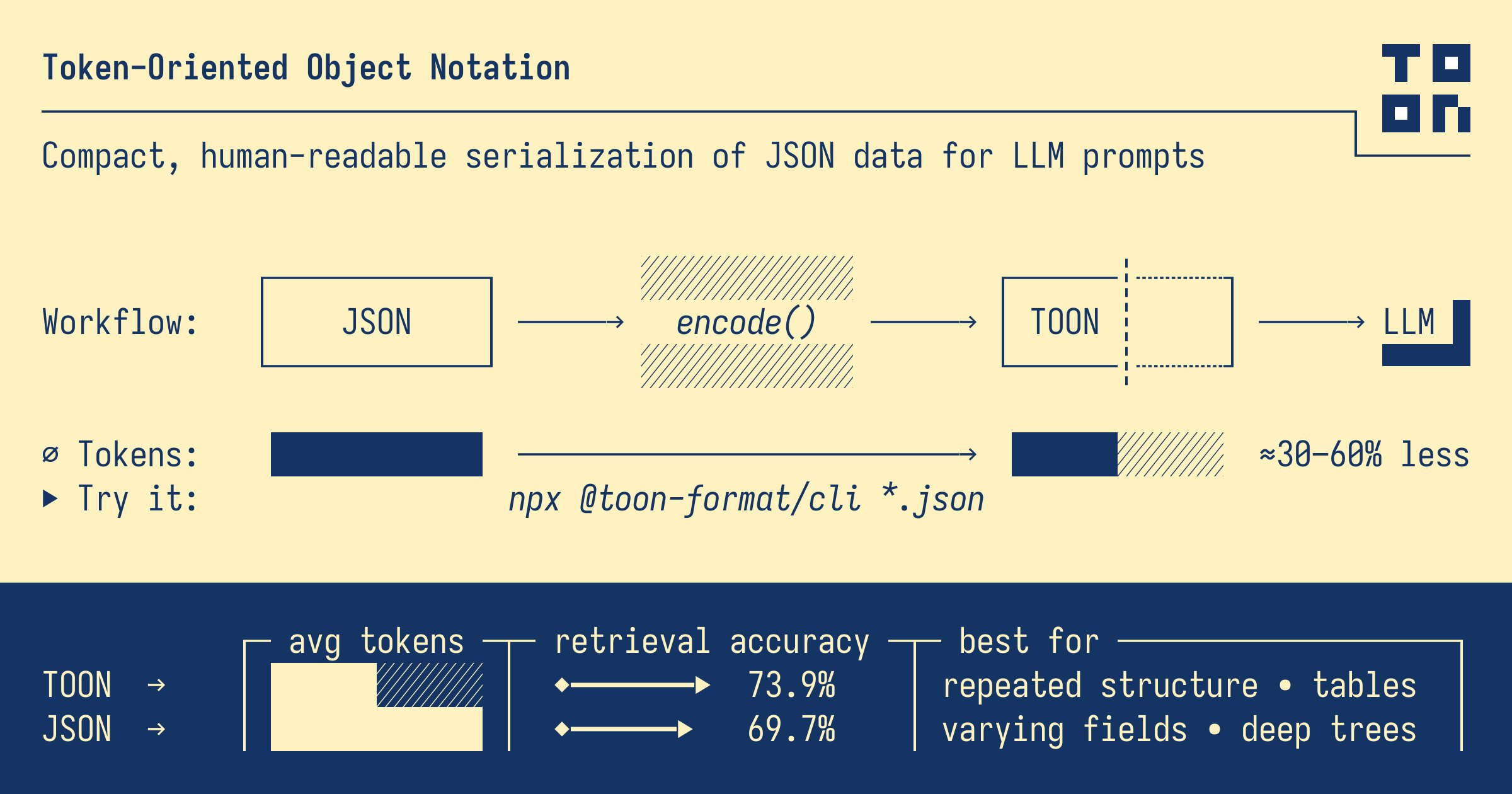
The LLM Token Crisis
The Token Cost Problem in LLM Architectures
LLMs charge by token count. Tokens are consumed not only by values, but by:
- Repeated field names
- Quotes and delimiters
- Structural syntax (braces, brackets, commas)
In JSON, this overhead is unavoidable.
For AI agents, orchestration layers, and multi‑step pipelines that exchange structured data repeatedly, this overhead compounds quickly. At scale, even small inefficiencies translate into meaningful operational costs.
Consider this practical example. A typical JSON response for an AI agent might look like:
{
"status":"success",
"user_id":12345,
"user_name":"Ram Ghadiyaram",
"transactions":[
{
"id":"txn_001",
"amount":150.00,
"currency":"USD",
"timestamp":"2024-12-15T10:30:00Z",
"category":"groceries",
"merchant":"whole_foods"
}
]
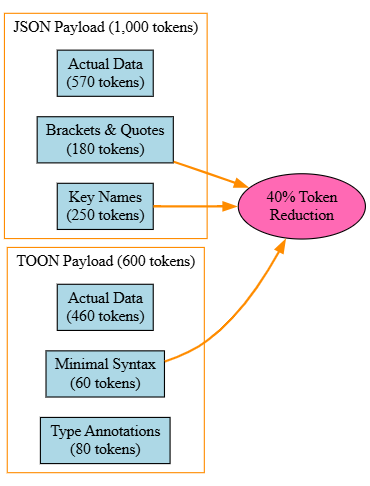
}This is readable and structured. It is also token-inefficient. Every key name repeats. Every bracket and quote takes space. For a system handling millions of LLM API calls daily, this overhead translates directly to six-figure monthly bills.
TOON reimagines this scenario by introducing a compact, schema-aware format that eliminates redundancy without sacrificing accessibility.
TOON vs. JSON
| Aspect | JSON | TOON | Winner | Practical Impact |
|---|---|---|---|---|
| Token Efficiency | Baseline | Often, 30–60% fewer tokens in schema-driven data | TOON | Lower LLM inference cost at scale |
| Parsing Speed | Mature, fast parsers | Comparable/context dependent or slightly faster in optimized pipelines | Context-dependent | Matters in real-time AI systems |
| Human Readability | High | Lower (schema-dependent) | JSON | JSON is better for debugging and manual inspection |
| Schema Definition | External or implicit | Schema-first design | TOON | Stronger structure for AI pipelines |
| Learning Curve | Minimal | Low to moderate | JSON | Faster onboarding for developers |
| Ecosystem Support | Universal | Emerging | JSON | JSON works everywhere today |
| Type Awareness | Weak | improved via context awareness | TOON | Better LLM interpretation of fields |
| Comments / Annotation | Not supported | Possible (implementation-dependent) | TOON | Enables inline metadata without breaking parsing |
| Public API Suitability | Excellent | Poor | JSON | JSON required for third-party integration |
| Polymorphic Data | Flexible | Less flexible | JSON | JSON handles variants better |
| Memory Footprint | Baseline | Can be significantly smaller | TOON | Useful for edge or high-volume systems |
| Standardization | Fully standardized | Evolving | JSON | JSON is stable and mature |
JSON remains the best default choice for most systems:
- Universal tooling and ecosystem support
- Minimal learning curve
- Excellent interoperability
- Strong handling of polymorphic data
TOON excels in a narrower, but increasingly important, domain:
- High‑volume LLM pipelines
- Agent‑to‑agent or agent‑to‑orchestrator communication
- Predictable, schema‑driven payloads
- Cost‑sensitive AI workloads
This is not a replacement. It is a specialization driven by new economic constraints.
How TOON Reduces Token Usage
TOON relies on context instead of repetition.
Once a schema is established, TOON transmits values in a fixed order rather than repeating keys for every object. Quotes and delimiters are omitted when unnecessary, and structure is implied rather than restated.
In practice, this leads to meaningful reductions:
- Simple objects: ~20 – 35% fewer tokens
- Repeated nested structures: ~40 – 55% fewer tokens
- Large arrays with stable schemas: up to ~65% fewer tokens
For systems making thousands or millions of LLM calls, this translates directly into lower inference cost, reduced latency, and more predictable spending.
A TOON representation of the same transaction data might appear as:
status,success
user_id,12345
user_name,Ram Ghadiyaram
transactions[1]{id,amount,currency,timestamp,category,merchant},
txn_001,150,USD,2024-12-15T10,30,00Z,groceries,whole_foodsThe example assumes a previously agreed schema defining field order and types.
Notice what has changed:
Type annotations replace repeated structural metadata. Quotes around simple strings disappear. Commas are implicit in certain contexts. Comments become first-class citizens without special syntax.
For more complex nested structures, TOON shines even brighter. Imagine an e-commerce system managing product catalogs with thousands of items. In JSON, each item duplication creates token waste. In TOON, once the schema is established, the compact notation dramatically reduces payload size.
Real-world example from an AI agent managing retail store inventory:
Inventory: {
warehouse: main_facility
items: [
Product: {
sku: SKU-001
qty: 450
price: 29.99
status: in_stock
}
Product: {
sku: SKU-002
qty: 0
price: 89.99
status: backorder
}
Product: {
sku: SKU-003
qty: 1200
price: 14.99
status: in_stock
}
]
last_updated: 2024-12-15T14:22:15Z
next_audit: 2024-12-20
}
For a system making 10,000 API calls daily, this compact representation translates to measurable savings, not just in tokens but in latency and infrastructure costs.
Data Flow: JSON to TOON Conversion
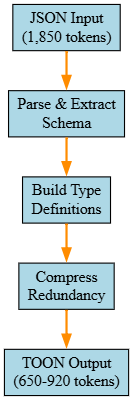
LLM Processing Pipeline With TOON

Performance and Operational Impact
Beyond token reduction, TOON can offer secondary benefits:
- Smaller serialized payloads
- Lower memory footprint
- Reduced bandwidth usage
- Potentially faster parsing due to reduced input size
Will Token‑Optimized Formats Become Standard?
JSON will remain dominant because it is widely supported and “good enough” for most use cases. That will not change soon.
However, generative AI introduces economic pressures that traditional systems never faced. When communication cost becomes visible and recurring, optimization moves from the margins to the core of system design.
TOON represents an early response to this shift. Whether it becomes a standard or remains a niche tool, the underlying idea is likely to persist.
In large‑scale AI systems, how efficiently systems communicate with LLMs is becoming as important as how fast they compute.
That is the real lesson behind TOON.
Multi-Layer Token Consumption Analysis
![Multi-layer token consumption analysis]() When to Use TOON and When Not To
When to Use TOON and When Not To
 When to Use TOON and When Not To
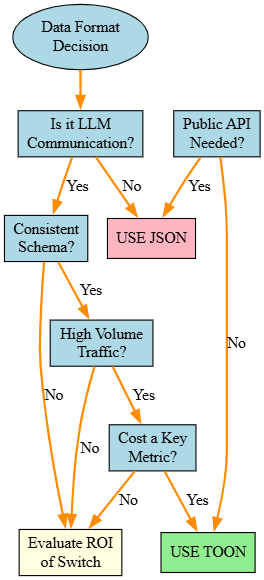
When to Use TOON and When Not To TOON represents a powerful optimization, but it is not a universal replacement.
Use TOON when:
- Building LLM-to-LLM or LLM-to-API communication systems where every token carries a direct cost
- Your data structures follow consistent, predictable schemas
- Processing high-volume, repetitive data exchanges (e-commerce orders, sensor readings, transaction logs)
- You control both sides of the communication protocol
- Token efficiency directly impacts your bottom line
Do NOT use TOON when:
- Building public-facing APIs that humans will interact with or debug
- You need maximum interoperability across diverse systems
- Simplicity and zero learning curve are priorities
- Your data structures are highly irregular or polymorphic
- Your current serialization overhead is not a meaningful cost driver
- You are working in environments where JSON support is mandatory
TOON is not positioned as a replacement for JSON in general computing. Rather, it is a specialized tool for the specific domain of AI communication, where token scarcity creates economic pressure for optimization.
Use Case Decision Tree
Performance Benchmarks and Real-World Case Studies
Early adopters report meaningful gains. The pattern emerges consistently. Systems with high-volume, structured communication benefit substantially from TOON adoption.
Parsing performance remains competitive with JSON. Parsing performance is comparable to JSON and may improve in optimized pipelines due to smaller payloads. Memory footprint for serialized data drops proportionally with size reduction, a meaningful benefit for edge AI deployments.
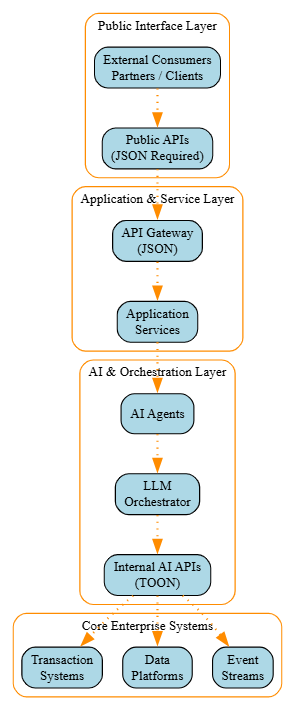
Enterprise Adoption Layers
![Enterprise adoption layers]() Will TOON Replace JSON for AI Workflows?
Will TOON Replace JSON for AI Workflows?
 Will TOON Replace JSON for AI Workflows?
Will TOON Replace JSON for AI Workflows?Probably not everywhere, but in some places, yes.
JSON is popular for good reasons. It works everywhere, is easy to understand, and has a huge ecosystem behind it. These strengths are not going away. JSON will continue to power public APIs, developer tools, and applications built for people.
However, generative AI changes the cost model. When every character sent to an LLM costs money and must be processed by a very large model, efficiency matters more than before. In these situations, TOON’s token savings become hard to ignore.
This is for specialization, not replacement. JSON remains the default format.
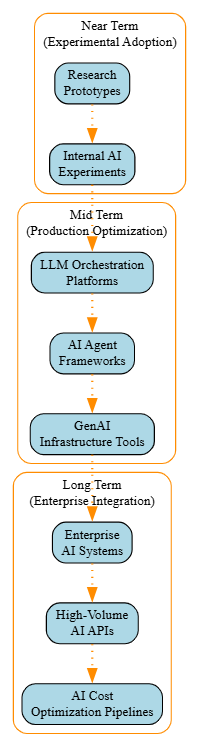
TOON finds its place in high-volume AI systems where cost and scale drive design decisions. Expect to see TOON adoption grow in:
- LLM orchestration platforms
- AI agent frameworks
- GenAI infrastructure tools
- High-volume AI APIs
- Enterprise AI systems where cost optimization drives architectural decisions
TOON Ecosystem Projected Growth
![TOON ecosystem projected growth]() Conclusion
Conclusion
 Conclusion
ConclusionTOON is more than a data format tweak. It reflects a shift caused by generative AI, where communication itself has a measurable cost. In traditional systems, data exchange was mostly free. With LLMs, every token sent or received is billed, making efficiency a core design concern.
As LLMs move into production systems, autonomous workflows, and critical infrastructure, token efficiency becomes part of everyday engineering decisions. Just as we moved from XML to JSON to reduce overhead, AI systems may adopt specialized formats like TOON to reduce cost and scale sustainably. Each format evolution reflects the constraints of its time, and token economics is the new constraint.
If you're interested in learning more, go to GitHub and experiment with it in your LLM workflows.
What's your perspective? Please let me know in the comments.
Opinions expressed by DZone contributors are their own.
Comments