Top 5 Reasons Why Your Redis Instance Might Fail
Delve into common challenges affecting Redis instances. Discover the top 5 reasons for failures and explore strategies for ensuring consistent and optimal performance.
Join the DZone community and get the full member experience.
Join For FreeIf you’ve implemented a cache, message broker, or any other data use case that prioritizes speed, chances are you’ve used Redis. Redis has been the most popular in-memory data store for the past decade and for good reason; it’s built to handle these types of use cases. However, if you are operating a Redis instance, you should be aware of the most common points of failure, most of which are a result of its single-threaded design.
If your Redis instance completely fails, or just becomes temporarily unavailable, data loss is likely to occur, as new data can’t be written during these periods. If you're using Redis as a cache, the result will be poor user performance and potentially a temporary outage. However, if you’re using Redis as a primary datastore, then you could suffer partial data loss. Even worse, you could end up losing your entire dataset if the Redis issue affects its ability to take proper snapshots, or if the snapshots get corrupted.
In this article, we will explain the main reasons why your Redis instance might fail, and provide advice to avoid this. We'll also compare the reliability of Redis (OSS version) with Dragonfly, a source-available multi-threaded in-memory database with a modern architecture that was designed to avoid many of these issues.
The Main Reasons a Redis Instance Can Fail
Scalability Limitations in Redis’ Architecture
Redis is limited to a single thread, which causes bottlenecks and reduced performance during high workloads. Vertical scaling won’t get you far with Redis — there is nothing stopping you from provisioning 128 CPU cores, but Redis will only ever be able to make use of one of them. This means horizontal scaling is your only realistic option, which immediately makes matters more complicated — as you now have to deploy and maintain a distributed system.
Clustering will greatly increase the amount of work required to maintain your Redis deployment. If you get an unhealthy node, it can’t be easily replaced without downtime (and therefore data loss), unless you implement high availability practices. High availability means not only setting up more nodes to handle the extra load, but configuring each of these nodes to have one or more replicas — requiring even more infrastructure and maintenance resources beyond those required to just scale out.
As with many of Redis’ problems, this is due to its design. Redis originally made certain design trade-offs that made it an industry leader in both speed and latency. Since then, however, more powerful public cloud hosting has evolved, and consumer expectations have been raised — they want fast, highly-available applications — leading developers to demand more speed, lower latency, and higher reliability from their systems.
Running Out of Memory
Like all in-memory databases, Redis stores all its data in memory. This makes the data much faster to retrieve, but if your system runs out of memory you can suffer data loss. Redis is particularly vulnerable to running out of memory during the snapshotting phase.
Every time you back up your Redis data set, the snapshotting process is launched in the background. If Redis is trying to back up your data while it’s also under heavy write load, memory usage increases massively, and if you don’t have enough memory allocated to do both tasks at once, you risk bringing down your entire Redis instance.
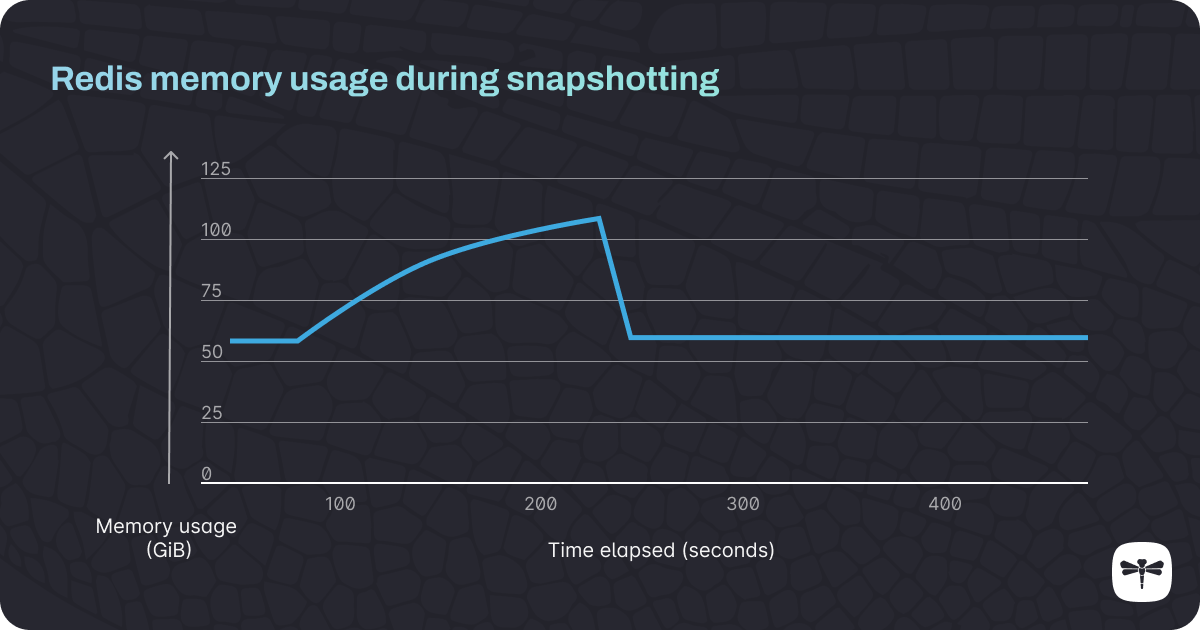
Figure 1: A Redis instance with 10 million keys is using 56 GiB of memory. The snapshotting process is initiated after 60 seconds, and the memory usage increases to double its original size (105 GiB), before dropping back to normal levels at 240 seconds, when the process completes.
The exact same issue can occur if you try to scale or upgrade your Redis instance during a period of heavy write load: if you don’t have enough memory allocated, you may run out, leading to a crash and/or data loss.
Lack of Consistency Between Redis Cluster Nodes
Redis doesn’t guarantee consistency — this is a tradeoff in order to achieve very low latency. Consistency means that the data between the master and replica nodes of a cluster are always in sync. The problem is that when data gets written to the master Redis node, it sends back a message to say that the write was successful before that write has been propagated to its replicas. So if something happens to the master node during this process, the replica gets promoted to master and the latest data write gets lost forever.
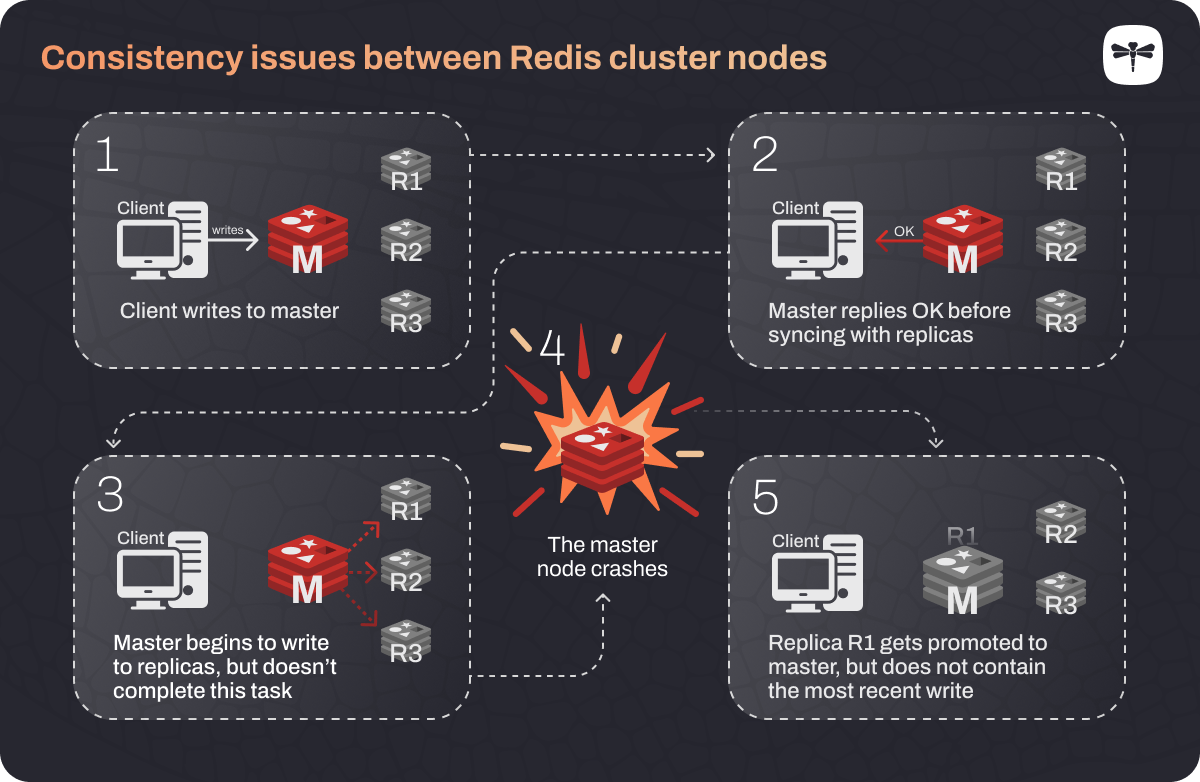
Figure 2
Another consistency issue is known as “split brain.” This happens if a network partition failure splits your Redis nodes across two partitions that lose communication with each other, with a master node ending up on one side and its replica on the other. The replica will then be promoted to master, and once this has happened, it’s possible for different data to be written to the two different master nodes, causing them to get out of sync.
Replication Loops
As your Redis database gets larger, it takes longer to copy data from master to replica when syncing the two. The master node has a replication buffer, and data is copied to this before it gets copied to the replica. This replication buffer is finite in size, so if your Redis database is large, the buffer can get completely filled up before the copying has finished. This means that while your master node gets the full update, your replica misses out on some of this data.
This is a much bigger problem than a replica simply missing a small amount of data: Redis relies on a check that the master and replica are in sync before proceeding to the next update step, and this issue means that the condition will never be met. Redis deals with this fact by restarting the entire replication process, which causes an infinite replication loop, making your instance unavailable.
Failure to Provision the Extra Memory that Redis Requires for Snapshotting
If your database is large, your master node will need a lot of additional memory to complete the snapshotting process. Redis often needs around three times the amount of memory than it normally uses just so that it can complete a snapshot successfully. To avoid running out of memory, your only solution is to over-provision your database server by a large amount. This is an expensive band-aid but it’s the only way that Redis can handle the memory-intensive snapshotting process.
Solving the Most Common Causes of Redis Failure: A Comparison Between Redis OSS and Dragonfly
You can use Dragonfly, in most scenarios, to act as a drop-in replacement for Redis due to its API compatibility. As you can see below, Dragonfly addresses many of the most common causes of Redis failure. It is designed to reduce operational complexity and improve reliability.
| Redis | Dragonfly |
|---|---|
| Single-threaded: leads to bottlenecks and performance issues. | Multi-threaded: faster and more reliable. |
| For larger Redis instances, horizontally scaling is really the only option to improve performance, meaning you will need to maintain a Redis cluster. | Can be vertically scaled, which is much simpler. |
| Memory overload: this happens because Redis needs to process database transactions as well as run background tasks such as snapshots on a single thread. | Memory spikes don’t happen during snapshotting: database transactions, and tasks like snapshotting, can all be spread across multiple threads and completed faster, so crashes are much less likely. |
| You have to over-provision your servers to deal with the increased memory usage that comes with snapshotting. | No need to over-provision your servers due to much more efficient use of the underlying hardware. |
Dragonfly scales vertically, allowing you to vertically scale to over 1TB in data and 4 million queries per second on one instance. When you require more capacity, you can resize your VM.
Redis touts its single-threaded architecture as a feature, not a bug, and argues that it still performs well when run as part of a cluster. But maintaining a cluster adds complexity to your deployments and makes them difficult to maintain, requiring constant re-tuning to perform optimally. While there are certainly sophisticated DevOps teams out there who have solved these Redis issues themselves through automation, we found it to be such a hassle that we decided to build an out-of-the-box solution for other developers.
More information is available at the Dragonfly project on GitHub.
Published at DZone with permission of Nick Gottlieb. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments