Transaction Isolation Levels For The Highest Possible Performance
Database transaction isolation levels let us get even better performance without rewriting our applications. See how they can be helpful and why we should care.
Join the DZone community and get the full member experience.
Join For FreeIt’s All About the Performance
SQL database cannot handle only one incoming connection at a time because it would be devastating for the performance of the system. We expect the database to accept many callers in parallel and execute their requests as fast as possible. It is rather clear how to do that when these callers ask for different data, i.e., the first caller reads from Table 1 while the second caller reads from Table 2. However, very often, different callers want to read from and write to the same table. How should we handle these queries? What should be the order of operations and the final result? This is where a transaction isolation level comes into play.
A transaction is a set of queries (like SELECT, INSERT, UPDATE, DELETE) sent to the database to execute, which should be completed as a unit of work. This means that they either need to be executed or none of them should be executed. It takes time to execute transactions. For instance, a single UPDATE statement may modify multiple rows. The database system needs to modify every row, and this takes time. While performing an update, another transaction may begin and try to read the rows that are currently being modified. The question we may ask here is — should the other transaction read new values of rows (despite not all of them being already updated), old values of rows (despite some of them being already updated), or maybe should it wait? And what if the first transaction needs to be canceled later for any reason? What should happen to the other transaction?
Transaction isolation levels control how we determine the data integrity between transactions. They decide how transactions should be executed when they should wait, and what anomalies are allowed to appear. We may want to allow for some anomalies to be theoretically possible to increase the performance of the system.
Read Phenomena
Depending on how we control concurrency in the database, different read phenomena may appear. The standard SQL 92 defines three read phenomena describing various issues that may happen when two transactions are executed concurrently with no transaction isolation in place.
We’ll use the following People table for the examples:
| id | name | salary |
|---|---|---|
| 1 | John | 150 |
| 2 | Jack | 200 |
Dirty Read
When two transactions access the same data, and we allow for reading values that are not yet committed, we may get a dirty read. Let’s say that we have two transactions doing the following:
| Transaction 1 | Transaction 2 |
|---|---|
| UPDATE People SET salary = 180 WHERE id = 1 | |
| SELECT salary FROM People WHERE id = 1 | |
| ROLLBACK |
Transaction 2 modifies the row with id = 1, then Transaction 1 reads the row and gets a value of 180, and Transaction 2 rolls things back. Effectively, Transaction 1 uses value that doesn’t exist in the database. What we would expect here is that Transaction 1 uses values that were successfully committed in the database at some point in time.
Repeatable Read
Repeatable read is a problem when a transaction reads the same thing twice and gets different results each time. Let’s say the transactions do the following:
| Transaction 1 | Transaction 2 |
|---|---|
| SELECT salary FROM People WHERE id = 1 | |
| UPDATE People SET salary = 180 WHERE id = 1 | |
| COMMIT | |
| SELECT salary FROM People WHERE id = 1 |
Transaction 1 reads a row and gets a value of 150. Transaction 2 modifies the same row. Then Transaction 1 reads the row again and gets a different value (180 this time).
What we would expect here is to read the same value twice.
Phantom Read
Phantom read is a case when a transaction looks for rows the same way twice but gets different results. Let’s take the following:
| Transaction 1 | Transaction 2 |
|---|---|
| SELECT * FROM People WHERE salary < 250 | |
| INSERT INTO People(id, name, salary) VALUES (3, Jacob, 120) | |
| COMMIT | |
| SELECT * FROM People WHERE salary < 250 |
Transaction 1 reads rows and finds two of them matching the conditions. Transaction 2 adds another row that matches the conditions used by Transaction 1. When Transaction 1 reads again, it gets a different set of rows. We would expect to get the same rows for both SELECT statements of Transaction 1.
Isolation Levels
SQL 92 standard defines various isolation levels that define which read phenomena can occur. There are four standard levels: READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ, and SERIALIZABLE.
READ UNCOMMITTED allows a transaction to read data that is not yet committed to the database. This allows for the highest performance, but it also leads to the most undesired read phenomena.
READ COMMITTED allows a transaction to read-only data that is committed. This avoids the issue of reading data that “later disappears” but doesn’t protect it from other read phenomena.
REPEATABLE READ level tries to avoid the issue of reading data twice and getting different results.
Finally, SERIALIZABLE tries to avoid all read phenomena.
The following table shows which phenomena are allowed:
| Level \ Phenomena | Dirty read | Repeatable read | Phantom |
|---|---|---|---|
| READ UNCOMMITTED | + | + | + |
| READ COMMITTED | - | + | + |
| REPEATABLE READ | - | - | + |
| SERIALIZABLE | - | - | - |
The isolation level is defined per transaction. For example, it’s allowed for one transaction to run with SERIALIZALBLE level, and for another to run with READ UNCOMMITTED.
How Does It Work Under the Hood?
The database needs to implement mechanisms guaranteeing the lack of specific read phenomena. There are generally two broad approaches to solving these: pessimistic locking and optimistic locking.
Pessimistic Locking
The first approach is called pessimistic locking. In this approach, we want to avoid issues by making sure a transaction doesn’t introduce problematic changes. We do that by locking specific parts of the database. When a given part is locked by one transaction, then another transaction cannot read or write data according to the transaction isolation level to avoid issues.
There are various levels of locks in the database: they can be stored on a row level, page level (which we can consider a group of rows for the purpose of this article), table level, and whole database level. There are also various types of locks: locks for reading, for writing, locks that can be shared between transactions or not, locks for intent, and so on. This article focuses on SQL databases in general, so that we won’t go into details of actual implementations.
Conceptually, to avoid a given read phenomenon, a transaction needs to lock specific parts of the database in a way that guarantees that other transactions will not introduce changes leading to a specific type of read phenomenon. For instance, to avoid dirty reads, we need to lock all modified or read rows so that other transactions cannot read or modify them.
There are multiple advantages of this approach. First, it allows for fine granularity in terms of what can be modified and which transactions can safely carry on. Second, it scales well and imposes low overhead when there are multiple transactions working on different data. Third, transactions don’t need to roll things back.
However, this can decrease the performance significantly. For instance, if two transactions want to read and modify data in the same table, and both of these transactions operate on a SERIALIZABLE level, then they’ll need to wait for each other to complete. Even if they touch different rows from the table.
Most database management systems use this way. For instance, MS SQL uses this for its four main isolation levels.
Optimistic Locking
Another approach is called optimistic locking. This approach is also known as snapshot isolation or Multiversion Concurrency Control (MVCC for short). Each entity in the table has an associated version number with it. When we modify a row, we also increase its row version so other transactions can observe that it changed.
When a transaction starts, it records the version number so it knows what the state of the rows is. When it reads from a table, it only extracts rows that were modified before the transaction was started. Next, when the transaction modifies the data and tries to commit them to the database, the database verifies row versions. If rows were modified in the meantime by some other transaction, the update is now rejected, and the transaction has to start from scratch.
This approach works well in a case when transactions touch different rows because then they can commit with no issues. This allows for better scaling and higher performance because transactions don’t need to take locks. However, when transactions often modify the same rows, some of the transactions will need to be rolled back often. This leads to performance degradation. Another disadvantage is the need to keep the row versions. This increases the complexity of the database system.
Various database management systems use this approach. For instance, Oracle or MS SQL with snapshots enabled.
Practical Considerations
While isolation levels seem to be well defined, there are various little details that affect how the database systems work under the hood. Let’s see some of them.
Isolation Levels Are Not Mandatory
While the SQL 92 standard defines multiple isolation levels, they are not mandatory. This means that all levels in a given database management system can be implemented as SERIALIZABLE. We use other isolation levels to increase the performance, but it’s not enforced in any way. This means that if we rely on a particular optimization happening in one database management system, the same optimization may not be used in another database management system. We shouldn’t rely on implementation details but stick to the standard instead.
Default Isolation Level Is Not Standardized
The default isolation level is configured per transaction. This is typically dictated by the library or connectivity technology you use to connect to the database. Depending on your default settings, you may operate on a different isolation level, and this may lead to different results or different performance. Typical libraries use SERIALIZABLE or READ COMMITTED level.
Problems With READ COMMITTED
While READ COMMITTED guarantees a transaction reads only committed data, it doesn’t guarantee that the data it reads is the latest one. It is possible that it reads a value that was committed at some point in the past but was overridden later on by another transaction.
There is another issue with the READ COMMITTED level. Due to how entities are stored under the hood, it is possible that a transaction reads a particular row twice or skips it. Let’s see why.
A typical database management system stores rows in a table in an ordered fashion, typically using the primary key of the table in a B-tree. This is because the primary key typically imposes a clustered index, which causes the data to be physically ordered on a disk. Let’s now assume that there are ten rows with IDs from 1 to 10. Let’s say our transaction read eight rows already, so rows with IDs from 1 to 8 inclusive. Now, if another transaction modifies the row with id = 2 and changes the id value to 11 (and commits), we’ll then continue scanning and find 11 rows in total. What’s more, we’ll read the row with id = 2, but the row doesn’t exist anymore!
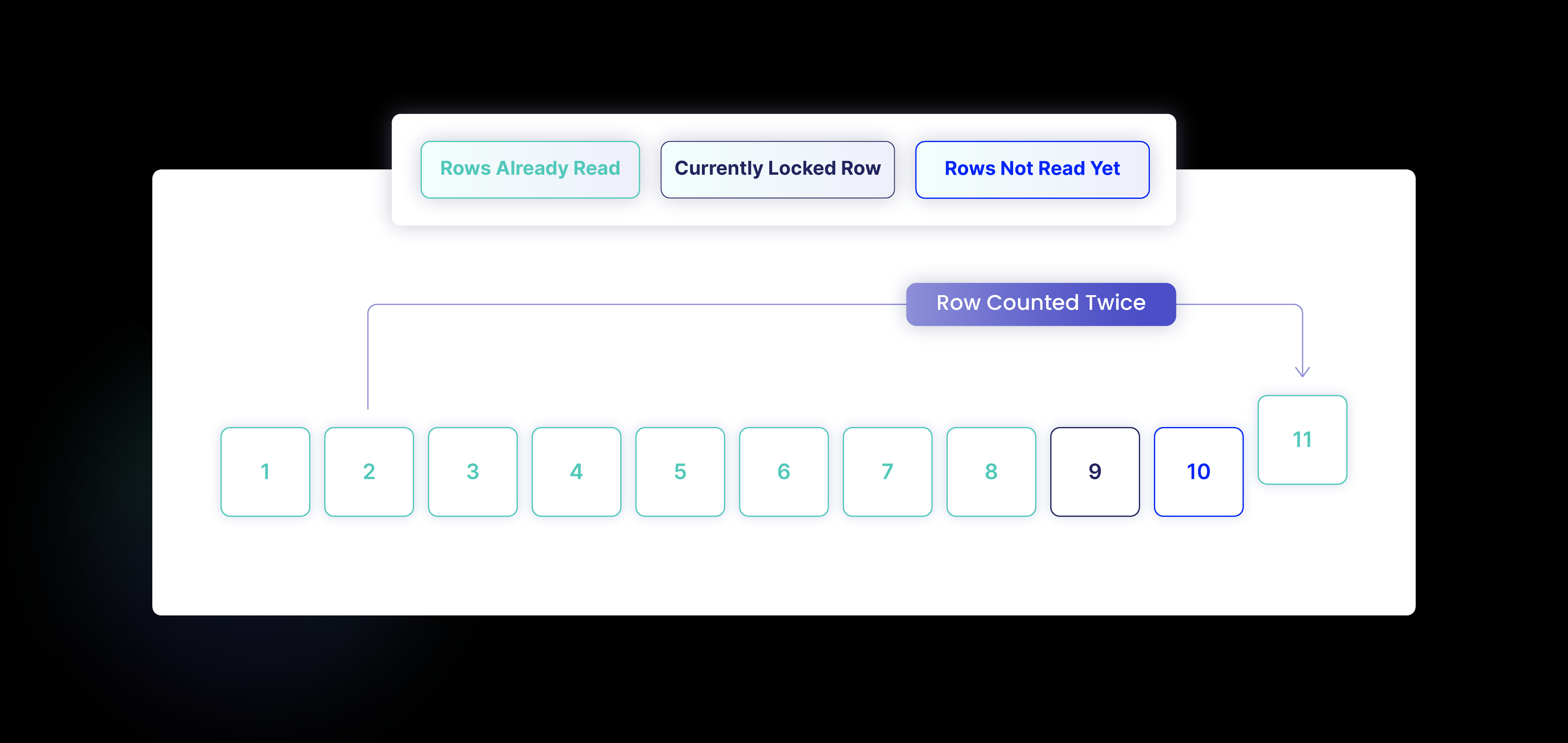
Based on the same idea, we can miss a row. Let’s say that we have 10 rows in total, and we already read rows from 1 to 4. Next, another transaction changes the row with id = 10 and sets its id to 3. We won’t find this row due to the ordering.
White and Black Marbles Problem
We mentioned two different ways of implementing locks. Pessimistic locking locks rows and disallows other transactions to modify them when they’re locked. Optimistic locking stores row versions and allows other transactions to move on as long as they work on the latest data.
There is another issue with the SERIALIZABLE level, when it’s implemented with optimistic locking, is known as the white and black marble problem. Let’s take the following Marbles table:
| id | color | row_version |
|---|---|---|
| 1 | black | 1 |
| 2 | white | 1 |
Let’s now say that we want to run two transactions. First tries to change all black stones into white. Another one tries to do the opposite — it tries to change all whites into blacks. We have the following:
| Transaction 1 | Transaction 2 |
|---|---|
| UPDATE Marbles SET color = 'white' WHERE color = 'black' | UPDATE Marbles SET color = 'black' WHERE color = 'white' |
Now, if we implement SERIALIZABLE with pessimistic locking, a typical implementation will lock the entire table. After running both of the transactions, we end with either two black stones (if first we execute Transaction 1 and then Transaction 2) or two white stones (if we execute Transaction 2 and then Transaction 1).
However, if we use optimistic locking, we’ll end up with the following:
| id | color | row_version |
|---|---|---|
| 1 | white | 2 |
| 2 | black | 2 |
Since both transactions touch different sets of rows, they can run in parallel. This leads to an unexpected result.
What To Do Now?
We learned how transaction isolation levels work. We can now use them to improve the performance. To do that, we need to understand what SQL queries are executed in the database and how they impact the performance. One of the easiest ways to do that is by using the Metis Observability dashboard:
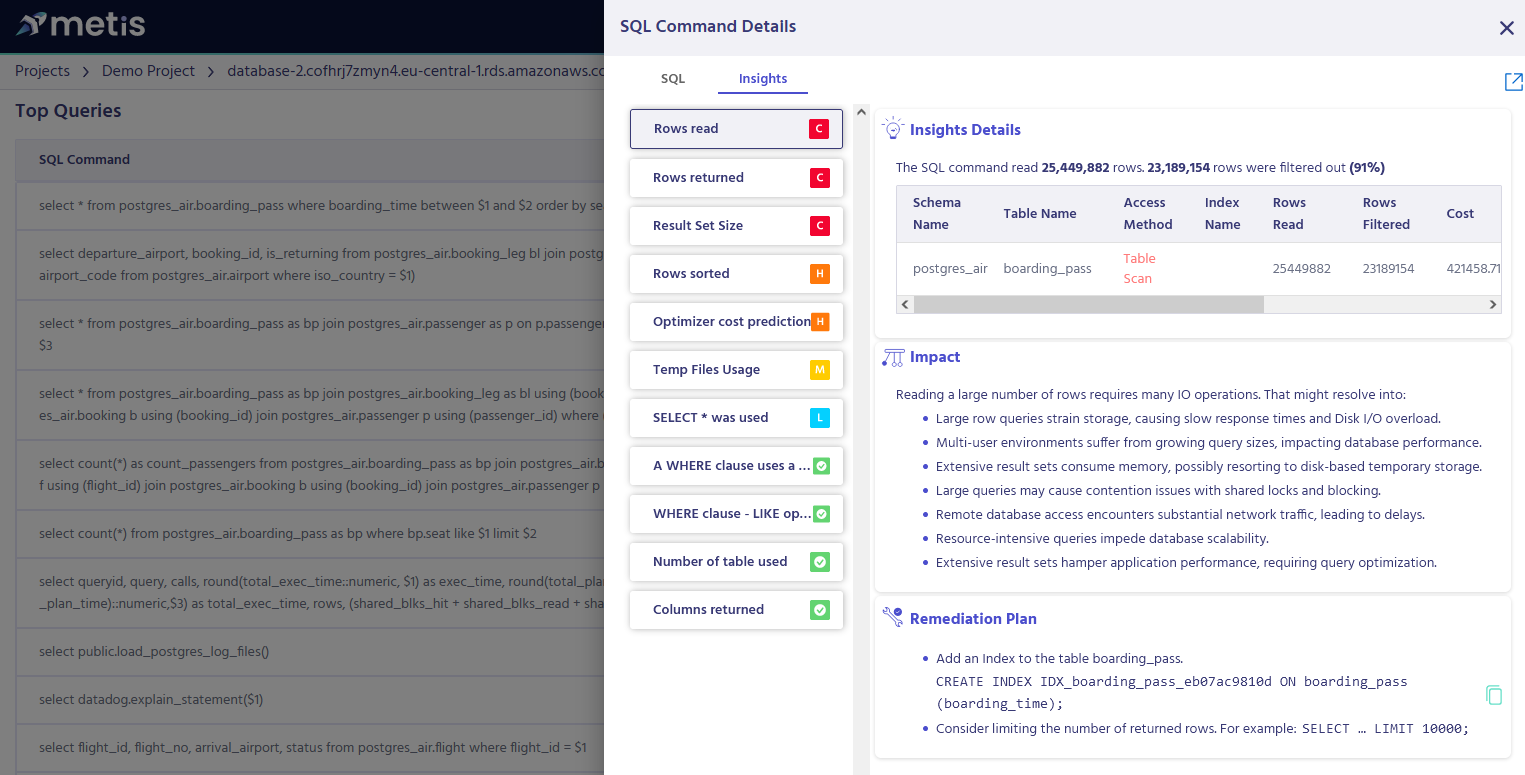
Metis dashboard can show you insights about all the queries that are executed and how to improve their performance by changing the database configuration. This way, we can see if we get the expected results and use the right isolation levels.
Summary
In this article, we have seen what transaction isolation levels are and how they allow for different read phenomena. We also learned how they are conceptually implemented by the database systems and how they can lead to unexpected results.
Published at DZone with permission of Adam Furmanek. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments