Trying to Represent a Tree Structure Using Postgres
I'll be publishing a series of blog posts on the Postgres LTREE extension. I'll get started today by trying to insert a tree structure into a Postgres table using standard SQL.
Join the DZone community and get the full member experience.
Join For Freesuppose you had a hierarchical data structure in your application. how would you save it in a database? how would you represent a complex tree structure using flat rows and columns?
there are a few different, equally valid, options. in this series of blog posts, i'll take a close look at one option that postgres provides: the ltree extension . if you install and enable ltree on your postgres server, it will add powerful sql operators and functions that support tree operations.
but what are these new sql operators and how do you use them? and how does ltree actually work? what computer science does it use behind the scenes to enable fast tree operations?
i'll be publishing a series of blog posts on the postgres ltree extension. i'll get started today by trying to insert a tree structure into a postgres table using standard sql, and during the rest of the series, i'll take a close look at ltree: how to install it, how to use it, and how it works.
an example tree
my actual dataset was more complicated, of course, but for the sake of example, let's suppose i needed to save this tree in a postgres table:
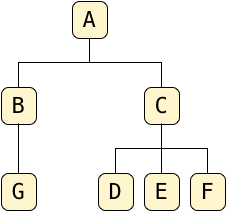
there are many different tree-like data structures in computer science, but this is probably the simplest: no cycles, no ordering of child nodes, and all the child nodes are accessible moving down from a single root. should be easy, right?
at first, i thought it would be. i started by creating a table with a
parent_id
foreign key column, like this:
create table tree(
id serial primary key,
letter char,
parent_id integer references tree (id)
);
the idea was that each row in my table represented a single node or element of the tree, and would identify its parent using the
parent_id
column. my single root node, a, had no parent, so i saved it first with a
null
parent id:
insert into tree (letter, parent_id) values ('a', null);
select * from tree;
id | letter | parent_id
----+--------+-----------
1 | a |
(1 row)and then i inserted each of its child nodes like this:
insert into tree (letter, parent_id) values ('b', 1);
insert into tree (letter, parent_id) values ('c', 1);
select * from tree;
id | letter | parent_id
----+--------+-----------
1 | a |
2 | b | 1
3 | c | 1
(3 rows)
because a has id=1, i set
parent_id
=1 for b and c. this is a simple example of the
adjacency list
algorithm: each row contains a list of its neighbors or adjacent rows. in this case, i was only recording each row's parent. and the table is
self-referencing
because it contains a foreign key (
parent_id
) referencing another column in the same table.
i continued to fill out my tree structure with a few more insert statements:
insert into tree (letter, parent_id) values ('d', 3);
insert into tree (letter, parent_id) values ('e', 3);
insert into tree (letter, parent_id) values ('f', 3);
insert into tree (letter, parent_id) values ('g', 2);
select * from tree;
id | letter | parent_id
----+--------+-----------
1 | a |
2 | b | 1
3 | c | 1
4 | d | 3
5 | e | 3
6 | f | 3
7 | g | 2
(7 rows)did my postgres tree work?
at first glance, my data structure worked well. i could easily find the parent of e:
select parent_id from tree where letter = 'e'
parent_id
-----------
3
(1 row)
select letter from tree where id = 3
letter
--------
c
(1 row)and the children of c like this:
select letter from tree where parent_id = 3
letter
--------
d
e
f
(3 rows)recursive tree operations
and it was also very easy to count how many children each node had; for example, this sql statement returns the number of children under a:
select count(*) from tree where parent_id = 1;
count
-------
2
(1 row)but what if i needed to know how many children a had, recursively? that is, what if i needed to count its children, grandchildren, great-grandchildren, etc.?
well, first i would have to find the direct children of a:
select id from tree where parent_id = 1;
id
----
2
3
(2 rows)then, to find the grandchildren, i would need to query for the children of the children, inserting the id values from the previous statement:
select id from tree where parent_id in (2, 3);
id
----
4
5
6
7
(4 rows)and then i would add the child count with the grandchild count: 2 + 4 = 6.
my example tree ends here, so i'm done. but this doesn't scale; suppose my tree had 10, 20, or 100 levels in it. i would have to execute repeated select statements, stepping down each level of the tree structure under the parent node:
select count(*) from tree where parent_id in (great-grandchild-ids);
select count(*) from tree where parent_id in (great-great-grandchild-ids);
select count(*) from tree where parent_id in (great-great-great-grandchild-ids);and so on.
in other words, i need to execute n -1 sql statements, where n is the number of levels in the tree under the parent node, each time inserting all of the ids returned by the previous query. and to find the total count, i would have to sum the number of ids returned by each query along the way. certainly not an efficient algorithm!
there must be a better way
my
parent_id
foreign key worked well for very simple tree operations, but not for more complex tasks, such as recursively counting nodes. if i set up my database schema differently, in a more thoughtful and complex way, can i avoid the repeated sql calls?
yes! there are a variety of options. one common solution is to use a nested set approach. in this design, each row contains a description of the set of other nodes that appear under it in the tree by saving the maximum and minimum id values of that subset of rows, the "nested set." using this scheme, querying children and grandchildren recursively becomes very easy. the drawback is that i would have to recalculate these values up and down the tree each time a new row was added.
another solution, path enumeration , involves using a column to save the path or position of each node in the tree. this can be a powerful solution, but recursive queries and other tree operations require special support to parse and manipulate these paths.
a completely different approach would be to use a graph-oriented database such as neo4j . these are database servers designed entirely around this problem: saving hierarchical data, or more generally networks of related data values.
but i didn't want to leave postgres behind; i already had a working, well-tested application. why start over from scratch just because i added a single tree structure to my app? why add new infrastructure and complexity to my overall system to support a single new data structure?
it turns out i didn't have to. postgres itself supports one of the two tree algorithms i mentioned above: path enumeration . bundled inside of the postgres source tree is an "extension" — an optional piece of c code you need compile, install, and enable — that supports tree sql operations using path enumeration. in my next post, i'll show you how to install and use the ltree postgres extension .
Published at DZone with permission of Pat Shaughnessy. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments