The Ultimate Chaos Testing Guide
Discover the safest ways to unleash controlled chaos to ensure your applications thrive under real-world unpredictability.
Join the DZone community and get the full member experience.
Join For FreeIntroduction
Ensuring system resilience and dependability has become a top goal in the quickly evolving field of software development. The complex interdependencies and unforeseen failure scenarios that occur in production contexts are frequently missed by standard testing techniques, despite their importance. Organizations can proactively identify vulnerabilities and fix them before they cause major disruptions by using the revolutionary approach that chaos testing provides.
Understanding the Chaos Testing Paradigm
A systematic and purposeful approach to evaluating fault tolerance is chaos testing, which is an integral part of Chaos engineering and involves purposefully introducing controlled failures into a system in order to observe and monitor how it behaves. By purposefully interfering with the system's regular operations, engineers are able to find elusive defects, delicate code pathways, and hidden dependencies that conventional testing techniques can miss. By accepting the unpredictable nature of real-world situations, chaos testing gives businesses important information about the weaknesses in their systems, allowing them to create stronger and more resilient solutions.
Origin and Evolution of Chaos Testing
When Netflix unveiled Chaos Monkey, a cutting-edge internal tool intended to improve system resilience, in the early 2010s, chaos testing got its start. In Netflix's production environment, Chaos Monkey randomly shuts down virtual machines and containers to mimic service outages and encourage the development of more resilient fail-proof techniques. Because of the tool's success, Netflix decided to make it open-source, which helped the industry as a whole embrace the concept of chaos engineering.
Major Principles Involved in Chaos Testing
Several fundamental ideas serve as a guide for chaos testing in order to maximize efficacy and reduce risk:
- Experimentation Driven by Hypotheses: Start with a well-defined hypothesis and precise objectives. Specify the system's behavior or resilience characteristics, such as resource management, load handling, or failure recovery, you want to assess.
- Begin with the basics: To learn the basic behavior of the system, start chaos testing with simple tests. As your expertise and confidence increase, move on to increasingly complicated situations.
- Employ Realistic Scenarios: Create chaos tests that are relevant to real-world production environments by reflecting real-world situations and possible failure modes.
- Controlled Conditions: To minimize the impact on end users and production environments, conduct chaos experiments under strict control using predetermined rollback procedures.
- Track System Metrics: Keep a close eye on metrics including network traffic, CPU/memory utilization, error rates, and response times. These observations aid in evaluating how well the system functions under pressure.
- Continuous Improvement: Increase system resilience by applying knowledge gained from chaos experiments. Utilize lessons learned to improve deployment and development procedures.
- Automation and Unpredictability: Use automated chaos testing techniques to create unpredictability so that the system's resilience to unforeseen failures may be thoroughly assessed.
- Simulate Real Failures: Create tests that mimic real-world problems, such as hardware breakdowns, traffic spikes, database failures, and network outages.
- Isolate Blast Radius: Limit the reach of chaos experiments to avoid causing extensive damage. Methods like feature flags and canary deployments reduce the danger to other system components.
- Document and Learn: Keep track of the results and observations from the chaotic test. Take advantage of both achievements and setbacks to strengthen system resilience and improve subsequent trials.
- Iterate and Enhance: Consider chaotic testing a continuous procedure. For increased robustness over time, improve system architecture, design, and operational procedures by incorporating insights from every test cycle.
Automated Chaos Testing Tools
Automated technologies are essential for injecting controlled randomization into trials and streamlining chaos testing. Among the most popular tools are the following:

- Chaos Monkey: The first chaos testing tool, Chaos Monkey simulates service interruptions and assesses system resilience by randomly ending virtual machines and containers.
- Kube-Monkey: Designed specifically for Kubernetes environments, Kube-Monkey functions by randomly ending pods inside a cluster, making it possible to evaluate the system's resilience to pod-level failures.
- VMware Mangle: An adaptable tool for chaos testing that can be used in a variety of deployment contexts to introduce a broad range of defects, including infrastructure failures.
- Litmus: It is a cloud-native chaos engineering platform for Kubernetes that facilitates the planning, carrying out, and evaluating of extensive chaotic experiments.
- Chaos Toolkit: It is a versatile command-line program for creating and executing chaos experiments which makes it simple to manage and modify tests by defining hypotheses using declarative JSON files.
Chaos Testing - The Methodology
A systematic method for introducing and safely assessing system faults is called chaos testing. The following steps are included in the standard methodology:
- Formulate a hypothesis by establishing precise goals for the chaotic test. Decide whatever system characteristics, such as scalability, fault tolerance, or resilience, you wish to assess.
- Determine Critical Scenarios: Choose crucial situations to test in a chaotic environment. These scenarios ought to mirror actual failure modes or stressors that the system may encounter during manufacturing.
- Experiment Design:Carefully plan the chaos experiment, taking into account possible hazards and putting safety measures in place such quick rollback mechanisms. Typical experiments consist of:
- Simulating packet loss or network latency.
- Introducing abrupt increases in traffic.
- Triggering the depletion of resources (such as the CPU, memory, or disc).
- Causing dependencies (such as databases or external services) to fail.
- Conducting the Experiment: Carry out the prearranged chaos experiment, monitoring the system's reaction and confirming the hypothesis. Automate the introduction of errors and disruptions by utilizing chaos engineering tools or frameworks.
- Measure and Monitor: Throughout the testing process, keep an eye on the system. Monitor important indicators such as network performance, CPU and memory utilization, error rates, and response times. Monitoring gives information on how the system behaves under pressure.
- Iterative Improvement: Examine experiment outcomes and apply the knowledge gained to improve the resilience of the system. Experiments should be repeated until the required degree of stability is reached.
- Document Learnings: Keep track of the findings, observations, and lessons you've learned during chaotic testing. To enhance comprehension of system behavior and direct future development and testing, share these insights with the group or company.
- Continuously Test: Make it a fundamental part of your development lifecycle. Seamlessly weave chaos experiments into your automated build, test, and release processes. Validate system improvements and proactively identify vulnerabilities to emerging threats.
Chaos Testing and Vulnerability Management
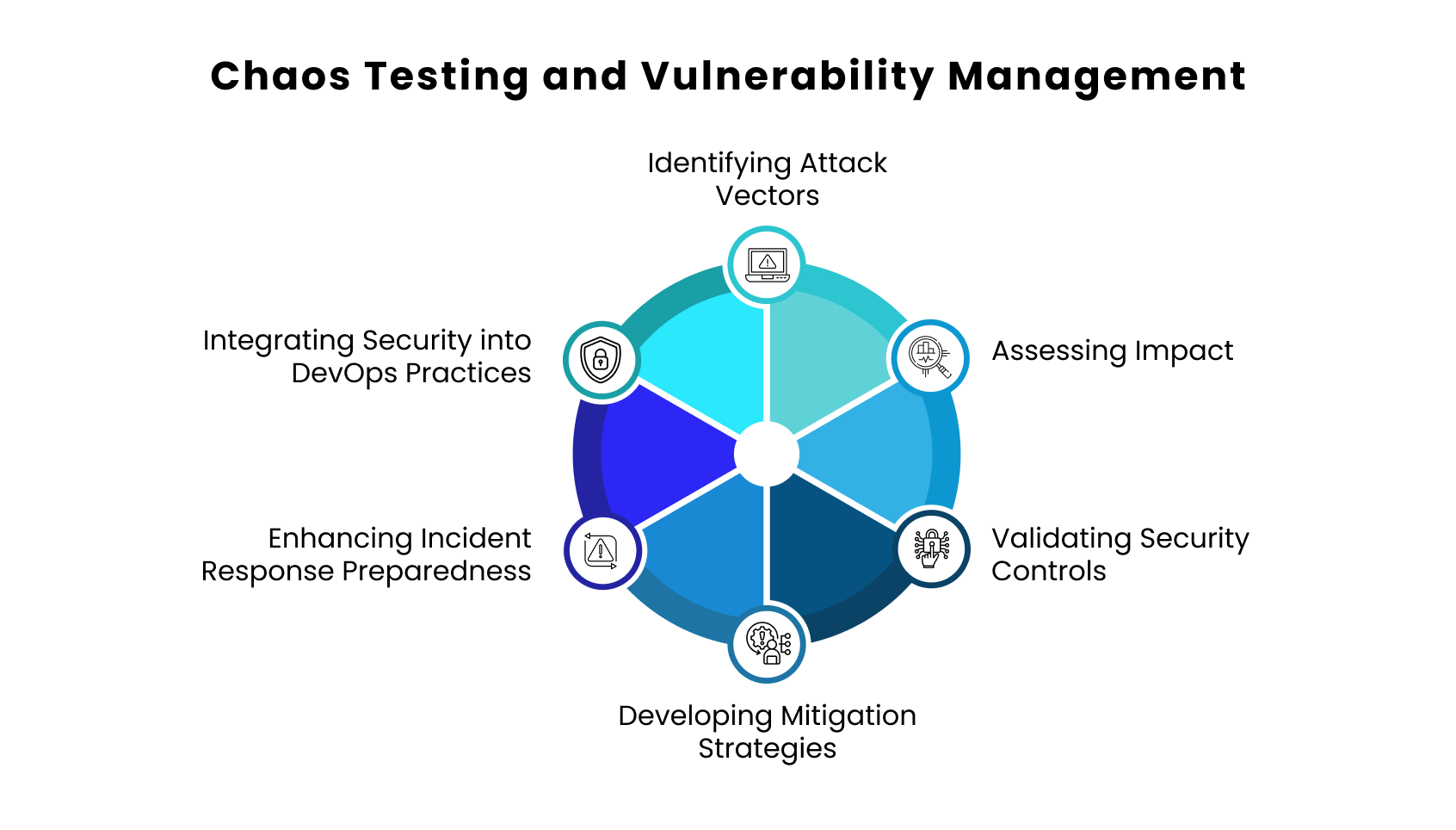
Chaos testing is a useful technique for managing vulnerabilities as well as enhancing system resilience. It contributes a lot to security by proactively detecting and fixing any possible security flaws. This is how it operates:
- Identifying Attack Vectors: Controlled scenarios that mimic possible weaknesses and attack vectors, including input manipulation or network outages, are introduced through chaos testing. By simulating scenarios that an attacker could exploit, these tests help security teams find vulnerabilities in the system.
- Impact Assessment: In a controlled environment, chaos testing assists organizations in determining the effects of successful exploits. Teams may prioritize remediation according to the severity and possible repercussions for system integrity, availability, and confidentiality by understanding how vulnerabilities appear during stress or failure scenarios.
- Verifying Security Controls: Chaotic testing verifies the efficacy of security mechanisms such as firewalls, intrusion detection systems (IDS), and access controls by simulating attack scenarios. Additionally, it evaluates how well monitoring systems identify and react to irregularities brought on by these simulated threats.
- Creating Mitigation Strategies: Robust mitigation strategies are developed using insights from chaos testing. Early vulnerability identification enables organizations to prioritize fixes, install patches, and modify configurations to bolster defenses, whether during development or current operations.
- Improving Incident Response Preparedness: By mimicking actual attack situations, chaos testing increases incident response readiness. It offers a platform for improving response protocols, confirming detection and escalation procedures, and educating teams on how to successfully handle security problems.
- Integrating Security in DevOps Procedures: Adding chaos testing to DevOps processes promotes a resilient and secure culture. It encourages cooperation between the development, operations, and security teams, guaranteeing that vulnerabilities are fully fixed and that security becomes a shared duty.
Limitations of Chaos Testing
Chaos testing is an effective technique for increasing system resilience, but it is not a foolproof solution for preventing all production incidents. It is not feasible to simulate every possible failure scenario. Nonetheless, chaos testing provides a wealth of information about a system's weaknesses, helping organizations better comprehend, evaluate, and handle real-world crises as they occur.
The Chaos Mindset: Addressing the Root Cause of Failure
Organizations are using chaos engineering increasingly to manage system complexity and boost resilience, according to Gartner's observations where 59% of organizations are presently using chaotic engineering, and another 33% are in the planning stage. Improving mean time to recovery (MTTR), addressing rising system complexity (68%), and identifying system vulnerabilities are the main drivers.
A fundamental change in the way software engineers approach system design and development is necessary for effective chaos testing, which goes beyond the use of tools and experiments. By actively anticipating possible failure modes and resolving them early in the development process, one can adopt a proactive mindset.
The Future of Chaos Testing
Chaos testing is positioned to be a key component in tackling the increasing complexity of contemporary systems and the increased threat of cyberattacks as the software industry develops. The need for proactive resilience and fault tolerance will only increase, making chaos testing essential to software security, innovation, and dependability.
Organizational approaches to system resilience have undergone a radical change as a result of chaos testing. Teams can find hidden vulnerabilities, strengthen systems, and get ready for unforeseen difficulties by purposefully introducing controlled failures. The ideas and techniques derived from chaos testing will influence software engineering and cybersecurity in the future as this methodology becomes more widely used, advancing the development of safe and robust digital systems.
Opinions expressed by DZone contributors are their own.
Comments