Understanding Git
This article takes a deeper dive into Git. Developers familiar with Git basics will get an in-depth understanding of how Git works behind the scenes.
Join the DZone community and get the full member experience.
Join For FreeWhat Is Git?
Git is a distributed revision control system. This definition sounds complicated, so let's break it down and look at the individual parts. The definition can be broken down into two parts:
- Git is distributed.
- Git is a revision control system.
In this article, we'll elaborate on each of these characteristics of Git in order to understand how Git does what it does.
Revision Control System
A revision control system tracks content as it changes over time, which makes it a content tracker. Git tracks changes to contents by computing their SHA1 hash. If the hash of an object that Git is tracking has changed, Git treats it as a new object. To provide persistence, Git stores this map of SHA1 as a key and object as the value in a repository on the project's directory. So, at its very core, Git is essentially a persistent map. This is illustrated in the figure below.
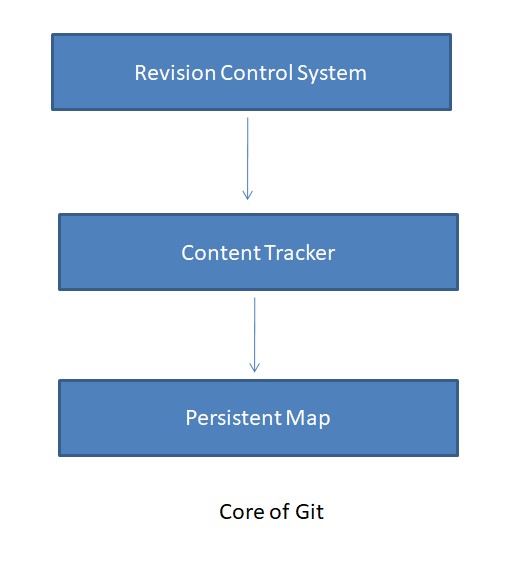
We'll start our journey from the core and explore Git layer-by-layer as we move outwards to understand the complete picture.
Persistent Map
In programming languages, a map is an interface that represents a collection of key-value pairs, where each key is associated with a unique value. Git computes the hash of an object that it stores in its repository.
git hash-object "Flash 9000"This returns the SHA1 of the string object having the content "Flash 9000".
The Git repository is instantiated with the following command. This creates a repository in a hidden folder named .git.
$ git init
Initialized empty Git repository in D:/git/test/.git/To store an object in its repository, we can pass '-w' flag.
$ echo "Flash 9000" | git hash-object --stdin -w
fc75e0215a2fcaeea1b949dab29c6014a2333399Every object in Git has its own SHA1. Git is a map where keys are SHA1 and values are the content. Persistence is provided with the flag (-w) in the repository. Notice how Git stored the object in its repository in .git folder.
$ ls -ltr .git/objects/fc/
total 1
-r--r--r-- 1 ragha 197121 27 Sep 13 16:01 75e0215a2fcaeea1b949dab29c6014a2333399Now that we understand the very core of Git, i.e., it is a persistent map, let's look at the next layer - content tracker, i.e., how Git tracks changes made to an object over time.
Content Tracker
We store content in files and directories. So, let's create a file and store some content that we want to track. We initialize a Git repository and store our content in the repository. Create a file with the content shown below. Add the file and commit it to the repository.
# create a file
$ touch storage_insights.txt
$ echo "Flash 9000" >> storage_insights.txt
$ git add .
$ git commit -m "First commit"
[master (root-commit) b7d1ea0] First commit
1 file changed, 1 insertion(+)
create mode 100644 storage_insights.txt
Let's check the .git folder to find out what objects Git created to track the single file we've in our repository.
$ ls -ltR .git/objects/
.git/objects/:
total 0
drwxr-xr-x 1 ragha 197121 0 Sep 13 16:57 b7/
drwxr-xr-x 1 ragha 197121 0 Sep 13 16:57 af/
drwxr-xr-x 1 ragha 197121 0 Sep 13 16:56 fc/
drwxr-xr-x 1 ragha 197121 0 Sep 13 16:50 info/
drwxr-xr-x 1 ragha 197121 0 Sep 13 16:50 pack/
.git/objects/b7:
total 1
-r--r--r-- 1 ragha 197121 137 Sep 13 16:57 d1ea0ff44167b0daa2b3016d3fced984618612
.git/objects/af:
total 1
-r--r--r-- 1 ragha 197121 65 Sep 13 16:57 ddf78df335c4a85c0e05ba3804fa1ab64fd4fd
.git/objects/fc:
total 1
-r--r--r-- 1 ragha 197121 27 Sep 13 16:56 75e0215a2fcaeea1b949dab29c6014a2333399
.git/objects/info:
total 0
.git/objects/pack:
total 0
Git created three objects with three SHA1. Let's check the kind of objects created and their contents. Git provides utility methods for this purpose. To fetch the content of an object, Git provides the utility method.
git cat-file -p <SHA1>There are different types of objects stored in the Git repository, Git provides the following method to find the type of an object.
git cat-file -t <SHA1>The types of three objects are shown below.
$ git cat-file -t b7d1ea0ff44167b0daa2b3016d3fced984618612
commit
$ git cat-file -t afddf78df335c4a85c0e05ba3804fa1ab64fd4fd
tree
$ git cat-file -t fc75e0215a2fcaeea1b949dab29c6014a2333399
blobLet's show their contents to understand better.
$ git cat-file -p b7d1ea0ff44167b0daa2b3016d3fced984618612
tree afddf78df335c4a85c0e05ba3804fa1ab64fd4fd
author Randhir Singh <[email protected]> 1694604421 +0530
committer Randhir Singh <[email protected]> 1694604421 +0530
First commit
$ git cat-file -p afddf78df335c4a85c0e05ba3804fa1ab64fd4fd
100644 blob fc75e0215a2fcaeea1b949dab29c6014a2333399 storage_insights.txt
$ git cat-file -p fc75e0215a2fcaeea1b949dab29c6014a2333399
Flash 9000
The first object is a commit that is created as a result of the git commit command. The commit object is pointing to a tree object that refers to the file that we created. The tree object points to a blob object that has the content that we put in the file.
Pictorially, the Git repository at this point can be depicted as shown below.
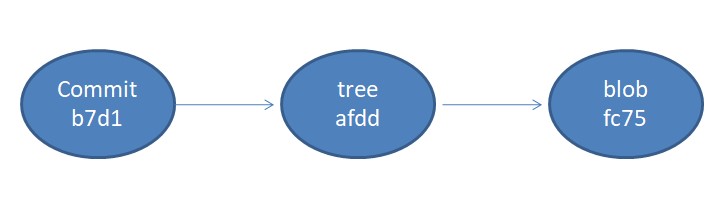
Let's modify the content and commit the updated file.
$ echo "Storwize" >> storage_insights.txt
$ git add .
$ git commit -m "Second commit"
[master b228401] Second commit
1 file changed, 1 insertion(+)How many objects are there in the Git repository now?
$ git count-objects
6 objects, 0 kilobytesLet's check the content of our Git repository.
$ ls -ltR .git/objects/
.git/objects/:
total 0
drwxr-xr-x 1 ragha 197121 0 Sep 13 17:21 b2/
drwxr-xr-x 1 ragha 197121 0 Sep 13 17:21 b1/
drwxr-xr-x 1 ragha 197121 0 Sep 13 17:20 b0/
drwxr-xr-x 1 ragha 197121 0 Sep 13 16:57 b7/
drwxr-xr-x 1 ragha 197121 0 Sep 13 16:57 af/
drwxr-xr-x 1 ragha 197121 0 Sep 13 16:56 fc/
drwxr-xr-x 1 ragha 197121 0 Sep 13 16:50 info/
drwxr-xr-x 1 ragha 197121 0 Sep 13 16:50 pack/
.git/objects/b2:
total 1
-r--r--r-- 1 ragha 197121 167 Sep 13 17:21 28401ce532180aa8fdffaa54731d9d2085f15d
.git/objects/b1:
total 1
-r--r--r-- 1 ragha 197121 65 Sep 13 17:21 f1a7abd35ad7178efe94a13ccf6de2868f68ce
.git/objects/b0:
total 1
-r--r--r-- 1 ragha 197121 36 Sep 13 17:20 0f271ba3e94459a48af1620ec9d2050df8e8f5
.git/objects/b7:
total 1
-r--r--r-- 1 ragha 197121 137 Sep 13 16:57 d1ea0ff44167b0daa2b3016d3fced984618612
.git/objects/af:
total 1
-r--r--r-- 1 ragha 197121 65 Sep 13 16:57 ddf78df335c4a85c0e05ba3804fa1ab64fd4fd
.git/objects/fc:
total 1
-r--r--r-- 1 ragha 197121 27 Sep 13 16:56 75e0215a2fcaeea1b949dab29c6014a2333399
.git/objects/info:
total 0
.git/objects/pack:
total 0Git created three new objects.
$ git cat-file -t b228401ce532180aa8fdffaa54731d9d2085f15d
commit
$ git cat-file -t b1f1a7abd35ad7178efe94a13ccf6de2868f68ce
tree
$ git cat-file -t b00f271ba3e94459a48af1620ec9d2050df8e8f5
blobLet's check their contents.
$ git cat-file -p b228401ce532180aa8fdffaa54731d9d2085f15d
tree b1f1a7abd35ad7178efe94a13ccf6de2868f68ce
parent b7d1ea0ff44167b0daa2b3016d3fced984618612
author Randhir Singh <[email protected]> 1694605866 +0530
committer Randhir Singh <[email protected]> 1694605866 +0530
Second commit
$ git cat-file -p b1f1a7abd35ad7178efe94a13ccf6de2868f68ce
100644 blob b00f271ba3e94459a48af1620ec9d2050df8e8f5 storage_insights.txt
$ git cat-file -p b00f271ba3e94459a48af1620ec9d2050df8e8f5
Flash 9000
Storwize
The new commit object now has a parent, which is the previous commit object. The new commit refers to the new tree object, which is the updated file, and the new tree refers to the new blob, which is the updated content. Pictorially, the situation at this point is shown below.
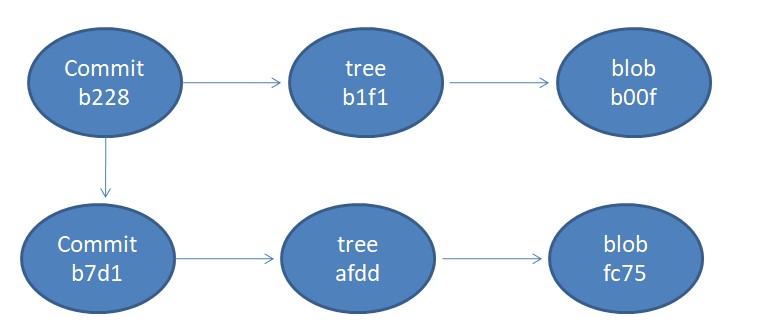
In a nutshell, the Git repository stores these objects, and the objects are linked with each other via pointers. The objects are immutable; each time they are modified, a new object is created, and references are updated. This is how Git tracks the content as it changes over time.
Now that we understand how Git tracks the content let's move on to the next layer and understand what makes Git a revision control system.
Revision Control System
Building upon the persistent map and the content tracker, Git is a revision control system that allows developers and teams to:
- Track changes made to files.
- Maintain a history of revisions, making it possible to revert to the previous version.
- Manage code branches and merge changes from different contributors.
In order to achieve these, Git provides some artifacts that make it a revision control system. We'll explain these one by one in this section.
Branches
Branches allow developers to experiment with different changes to their code without affecting the main codebase. This can help them to avoid introducing bugs into the main codebase. Branches can also be used to collaborate with other developers on the same project.
Just as Git stores various objects in its repository, branches are also stored there. Let's take a look.
$ cat .git/refs/heads/master
b228401ce532180aa8fdffaa54731d9d2085f15d
$ git cat-file -p b228401ce532180aa8fdffaa54731d9d2085f15d
tree b1f1a7abd35ad7178efe94a13ccf6de2868f68ce
parent b7d1ea0ff44167b0daa2b3016d3fced984618612
author Randhir Singh <[email protected]> 1694605866 +0530
committer Randhir Singh <[email protected]> 1694605866 +0530
Second commitThe branch is pointing to the second commit. A branch is just a reference to a commit. The master branch was created when we initialized the Git repository. To create a new branch, Git provides a method.
git branch <branchname>Notice another reference named HEAD. HEAD is a reference to a branch. HEAD changes as we switch branches. This is explained in the diagram below.

To change to a different branch.
$ git switch branch
Switched to branch 'branch'HEAD will now move to the branch branch. To check where the current HEAD is pointing to.
$ cat .git/HEAD
ref: refs/heads/branchAs we switch branches, files, and folders in the working area change. Git doesn't track them unless they are committed (i.e., available in the Git repository).
Merge
Next, let's look at the concept of merging. A merge in Git is the process of combining two or more branches into a single branch. This is typically done when you have finished working on a feature branch and want to integrate your changes into the main codebase.
To merge the changes from <branch> into the current branch.
git merge <branch>Let's see what happens if we merge a branch. We will add one commit to the branch branch and another commit to the branch master. When done, we'll merge the branch branch into the master branch.
$ git status
On branch branch
nothing to commit, working tree clean
$ echo "DS8000" >> storage_insights.txt
$ git add .
$ git commit -m "Added DS8000"
[branch aac6280] Added DS8000
1 file changed, 1 insertion(+)
Now, switch to the master branch and add some content to the file.
$ git switch master
Switched to branch 'master'
$ echo "XIV" >> storage_insights.txt
$ git add .
$ git commit -m "Added XIV"
[master d8a6319] Added XIV
1 file changed, 1 insertion(+)Merge the branch branch into the master branch. Since the same line of the file is modified in both branches, this will give rise to a conflict.
$ git merge branch
Auto-merging storage_insights.txt
CONFLICT (content): Merge conflict in storage_insights.txt
Automatic merge failed; fix conflicts and then commit the result.Resolve the conflict in the file and commit it. This will create another kind of Git object called merge commit.
$ git log --graph --decorate --oneline
* fcc8bae (HEAD -> master) Resolved merge conflict
|\
| * aac6280 (branch) Added DS8000
* | d8a6319 Added XIV
|/
* b228401 Second commit
* b7d1ea0 First commit
Let's examine the merge commit. It has two parents; one is the latest commit from the branch branch, and the other parent is the latest commit from the branch master.
$ git cat-file -p fcc8bae
tree 6031b0e96170c70d7ae4ad264840168c3fc0b1fa
parent d8a63194e4054fcd5c4289b5c0488514691c6beb
parent aac6280973f401bfe7a7d5a6904794b9133bac6c
author Randhir Singh <[email protected]> 1694609622 +0530
committer Randhir Singh <[email protected]> 1694609622 +0530
Resolved merge conflict
Pictorially, the Git repository at this point in time looks like this.

Git creates a merge commit only if it is required. A fast-forward merge is a type of merge in Git that combines two branches without creating a new merge commit. This is only possible if the two branches have a linear history, meaning that the target branch is a direct descendant of the source branch.
Losing HEAD
Normally, the HEAD points to the branch that points to the latest commit. However, it is possible for the HEAD to not point to a branch. In that case, HEAD is said to be detached. A detached HEAD is a state where the HEAD pointer is not pointing to a branch but instead pointing to a specific commit. This can happen if we check out a commit instead of a branch.
$ git checkout b228401
Note: switching to 'b228401'.
You are in 'detached HEAD' state.
When you are in a detached HEAD state, Git will not be able to automatically track your changes. To get out of a detached HEAD state, you can do one of the following:
- Create a new branch and checkout to it.
- Merge the changes in the detached HEAD state into your current branch.
- Checkout to a different branch.
Git Object Model
This is a good time to review the Git object model, as we've covered all the main Git objects. A Git repository is a bunch of objects linked to each other in a graph. Branch references to a commit, and HEAD is a reference to a branch.
Objects are immutable, meaning that they cannot be changed once they are created. This makes them very efficient for storing data, as Git can simply compare the contents of two objects to determine if they are different. There are four main types of objects in the Git object model:
- Blobs: Blobs store the contents of files.
- Trees: Trees store the contents of directories.
- Commits: Commits store metadata about changes to files, such as the author, date, and commit message.
- Tags: Tags are used to mark specific commits as being important.
Objects are stored in the .git directory of your repository. When you make a change to a file and commit it, Git creates a new blob object to store the contents of the changed file and a new commit object to store metadata about the change.
Git maintains objects in the repository by following three rules:
- The current branch tracks new commits.
- When you move to another commit, Git updates your working directory.
- Unreachable objects are garbage collected.
Rebase
Rebase is a process of replaying a sequence of commits onto a new base commit. This means that Git creates new commits, one for each commit in the original sequence, and applies them to the new base commit.
To rebase a branch, you can use the git rebase command. For example, to rebase the branch branch onto the master branch, you would run the following command:
git rebase master branchLet's look at the history of the branch branch. Contrast this to the earlier scenario when we merged the branch branch into the master branch.
$ git log --graph --decorate --oneline
* d1f27ee (HEAD -> branch) Added DS8000
* d8a6319 (master) Added XIV
* b228401 Second commit
* b7d1ea0 First commitPictorially, the following diagram explains what happens when we rebased.

The choice between merge and rebase is to be made based on your preferences. Remember
- Merge preserves history
- Rebase refactor history
Tags
A tag is like a branch that doesn't move. To create a tag.
git tag releaseAn annotated tag has a message that can be displayed, while a tag without annotation is just a named pointer to a commit.
Where is the tag stored? In the Git repository, like other objects. It points to the commit when the tag was created.
$ cat .git/refs/tags/release
d8a63194e4054fcd5c4289b5c0488514691c6beb
$ git cat-file -p d8a63194e4054fcd5c4289b5c0488514691c6beb
tree e4e282cde76ffa017c2d837a6d39bd0259715e2a
parent b228401ce532180aa8fdffaa54731d9d2085f15d
author Randhir Singh <[email protected]> 1694609414 +0530
committer Randhir Singh <[email protected]> 1694609414 +0530
Added XIVWe've covered the major concepts behind a revision control system and how those concepts are used to achieve its objectives. This completes the part that explains how Git serves as a revision control system.
Next, let us discuss the "distributed" nature of Git.
Git Is a Distributed Version Control
Git, being a distributed version control, every developer has a complete copy of the repository. This is in contrast to centralized version control systems, where there is a single central repository that all developers must access.

When you clone a Git repository, you create a local copy of the entire project, including all files and the entire commit history. This local repository contains everything you need to work on the project independently, without needing a constant internet connection or access to a central server.
A remote repository can be cloned using.
git clone <remote>In our case, we have a Git repository created locally. We'll create a remote repository on GitHub and set the remote. The configured remote repository is stored in .git/config
$ git remote add origin https://github.com/Randhir123/test.git
$ git push -u origin master
Enumerating objects: 9, done.
Counting objects: 100% (9/9), done.
Delta compression using up to 8 threads
Compressing objects: 100% (3/3), done.
Writing objects: 100% (9/9), 744 bytes | 372.00 KiB/s, done.
Total 9 (delta 0), reused 0 (delta 0), pack-reused 0
To https://github.com/Randhir123/test.git
* [new branch] master -> master
branch 'master' set up to track 'origin/master'.
$ cat .git/config
[core]
repositoryformatversion = 0
filemode = false
bare = false
logallrefupdates = true
symlinks = false
ignorecase = true
[remote "origin"]
url = https://github.com/Randhir123/test.git
fetch = +refs/heads/*:refs/remotes/origin/*
[branch "master"]
remote = origin
merge = refs/heads/master
Like a local branch, a remote branch is just a reference to a commit.

$ git show-ref master
d8a63194e4054fcd5c4289b5c0488514691c6beb refs/heads/master
d8a63194e4054fcd5c4289b5c0488514691c6beb refs/remotes/origin/masterPushing
Commits on the local branches can be pushed to remote branches, as shown below.
$ echo "SVC" >> storage_insights.txt
$ git add .
$ git commit -m "Added SVC"
[master 7552e51] Added SVC
1 file changed, 1 insertion(+)
$ git push
Enumerating objects: 5, done.
Counting objects: 100% (5/5), done.
Writing objects: 100% (3/3), 291 bytes | 291.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0), pack-reused 0
To https://github.com/Randhir123/test.git
d8a6319..7552e51 master -> master
Pulling
Commits on the remote branches can be fetched using.
git fetchAnd merged to a branch using.
git merge origin/masterThese two steps can be done in a single step using.
git pullThis will fetch remote commits and merge them into the local branch with a single command.
We can configure multiple remotes to our repository. All the remotes can displayed using the command.
$ git remote -v
origin https://github.com/Randhir123/test.git (fetch)
origin https://github.com/Randhir123/test.git (push)Pull Request
A pull request (PR), often used in the context of Git and code collaboration platforms like GitHub, GitLab, and Bitbucket, is used for proposing and discussing changes to a codebase. Pull requests are typically created to merge or pull our changes to the upstream.
Summary
In this article, we described the layers that Git is made of. We started our journey of understanding Git from the core, which is the persistent map. Next, we looked at how Git builds upon the persistent map to track the content. The content tracker layer forms the basis of the revision control system. Finally, we looked at the distributed nature of Git, which makes it such a powerful revision control system.
Opinions expressed by DZone contributors are their own.
Comments