Git Behind the Curtain: What Happens When You Commit, Branch, and Merge
Keith Gregory discusses object management, branches, merges, SHA-1, Git, and more in this talk script. Read on to learn all you need to know!
Join the DZone community and get the full member experience.
Join For Freethis is the script for a talk that i gave at barcamp philly . the talk is a “live committing” exercise, and this post contains all the information needed to follow along, as well as some links to relevant source material and minus my pauses, typos, and attempts at humor.
object management
i think that the first thing to understand about git is that it's not strictly a source control system; it's more like a versioned filesystem that happens to be good at source control. traditionally, source control systems focused on the evolution of files. for example, rcs (and its successor cvs) maintain a separate file in the repository for each source file. these repository files hold the entire history of the file as a sequence of diffs that allow the tool to reconstruct any version. subversion applies the idea of diffs to the entire repository, allowing it to track files as they move between directories.
git takes a different approach. rather than constructing the state of the repository via diffs, it maintains snapshots of the repository and constructs diffs from those (if you don't believe this, read on). this allows very efficient comparisons between any two points in history but does consume more disk space. i think the key insight is not just that disk is cheap and programmer time expensive, but that real-world software projects don't have a lot of large files, and those files don't experience a lot of churn.
to see git in action, we'll create a temporary directory, initialize it as a repository, and create a couple of files. i should note here that i'm using
bash
on linux; if you're running windows you're on your own re commands. anything that starts with “
>
” is a command that i typed; anything else is the response from the system.
> mkdir /tmp/$$
> cd /tmp/$$
> git init
initialized empty git repository in /tmp/13914/.git/
> touch foo.txt
> mkdir bar
> touch bar/baz.txt
> git add *
> git commit -m "initial revision"
[master (root-commit) 37a649d] initial revision
2 files changed, 0 insertions(+), 0 deletions(-)
create mode 100644 bar/baz.txt
create mode 100644 foo.txt
running
git log
shows you this commit, identified by its sha-1 hash.
> git log
commit 37a649dd6dec75cd68a2c3dfb7fa2948a0d3426e
author: keith gregory
date: thu nov 3 09:20:29 2016 -0400
initial revision
what you might not realize is that a commit is a physical object in the git repository, and the sha-1 hash is actually the hash of its contents. git has several different types of objects, and each object is uniquely identified by the sha-1 hash of its contents. git stores these objects under the directory
.git/objects
, and the
find
command will help you explore this directory. here, i sort the results by timestamp and then filename, to simplify tracing the changes to the repository.
> find .git/objects -type f -ls | sort -k 10,11
13369623 4 -r--r--r-- 1 kgregory kgregory 82 nov 3 09:20 .git/objects/2d/2de60b0620e7ac574fa8050997a48efa469f5d
13369612 4 -r--r--r-- 1 kgregory kgregory 52 nov 3 09:20 .git/objects/34/707b133d819e3505b31c17fe67b1c6eacda817
13369637 4 -r--r--r-- 1 kgregory kgregory 137 nov 3 09:20 .git/objects/37/a649dd6dec75cd68a2c3dfb7fa2948a0d3426e
13369609 4 -r--r--r-- 1 kgregory kgregory 15 nov 3 09:20 .git/objects/e6/9de29bb2d1d6434b8b29ae775ad8c2e48c5391ok, one commit created four objects. to understand what they are, it helps to have a picture:
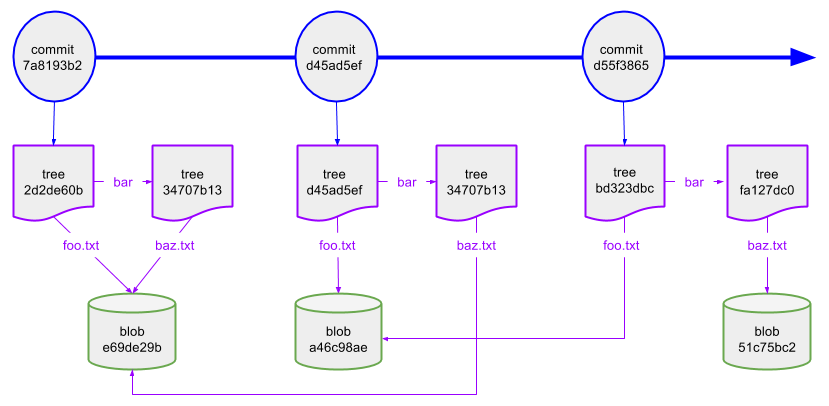
each commit represents a snapshot of the project: from the commit, you can access all of the files and directories in the project as they appeared at the time of the commit. each commit contains three pieces of information: metadata about the commit (who made it, when it happened, and the message), a list of parent commits (which is empty for the first commit but has at least one entry for every other commit), and a reference to the “tree” object holding the root of the project directory.
tree objects are like directories in a filesystem; they contain a list of names and references to the content for each name. in the case of git, a name may either reference another tree object (in this example, the “
bar
” sub-directory), or a “blob” object that holds the content of a regular file.
as i said above, an object's sha-1 is built from the object's content. that's why we have two files in the project but only one blob; because they're both empty files, the content is identical and therefore the sha-1 is identical.
you can use the
cat-file
command to look at the objects in the repository. starting with the commit, here are the four objects from this commit (the blob, being empty, doesn't have any output from this command):
> git cat-file -p 37a649dd6dec75cd68a2c3dfb7fa2948a0d3426e
tree 2d2de60b0620e7ac574fa8050997a48efa469f5d
author keith gregory
1478179229 -0400
committer keith gregory
1478179229 -0400 initial revision > git cat-file -p 2d2de60b0620e7ac574fa8050997a48efa469f5d
040000 tree 34707b133d819e3505b31c17fe67b1c6eacda817 bar
100644 blob e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 foo.txt> git cat-file -p 34707b133d819e3505b31c17fe67b1c6eacda817
100644 blob e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 baz.txt> git cat-file -p e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
now, let's create some content. i'm generating random text with that i think is a neat hack. you get a stream of random bytes from
/dev/urandom
, then use
sed
to throw away anything that you don't want. since the random bytes includes a new line every 256 bytes (on average), you get a file that can be edited just like typical source code. one thing that's non-obvious: linux by default would interpret the stream of bytes as utf-8, meaning a lot of invalid characters from the random source; explicitly setting the
lang
variable to an 8-bit encoding solves this.
> cat /dev/urandom | lang=iso8859-1 sed -e 's/[^ a-za-z0-9]//g' | head -10000 > foo.txt> ls -l foo.txt
-rw-rw-r-- 1 kgregory kgregory 642217 nov 3 10:05 foo.txt> head -4 foo.txt
u4uiesn4hn61l6is epqxlhsvalpjgt
n8opikrst5nqswnqyymt9bbmewbvaasvjzttfjcxht2vay2codt7j rm3f7cwefdgicodfs0tudgx
ovqjwoykmktowkd8nxwntccckui cxn3bn5gn4im38y cfs6idxgij9o6gbeggbw6bczj
2bluwmwqygynfihp8rul8m2aajm1fwcy8zx9fvmvji30p9sbekq6giuorvjswrw8plcsrewfsxezxxo2hk2is3mfnpvikragug3he96iwhen we commit this change, our object directory gets three new entries:
13369623 4 -r--r--r-- 1 kgregory kgregory 82 nov 3 09:20 .git/objects/2d/2de60b0620e7ac574fa8050997a48efa469f5d
13369612 4 -r--r--r-- 1 kgregory kgregory 52 nov 3 09:20 .git/objects/34/707b133d819e3505b31c17fe67b1c6eacda817
13369637 4 -r--r--r-- 1 kgregory kgregory 137 nov 3 09:20 .git/objects/37/a649dd6dec75cd68a2c3dfb7fa2948a0d3426e
13369609 4 -r--r--r-- 1 kgregory kgregory 15 nov 3 09:20 .git/objects/e6/9de29bb2d1d6434b8b29ae775ad8c2e48c5391
13369652 4 -r--r--r-- 1 kgregory kgregory 170 nov 3 10:07 .git/objects/16/c0d98f4476f088c46086583b9ebf76dee03bb9
13369650 4 -r--r--r-- 1 kgregory kgregory 81 nov 3 10:07 .git/objects/bf/21b205ba0ceff1655ca5c8476bbc254748d2b2
13369647 488 -r--r--r-- 1 kgregory kgregory 496994 nov 3 10:07 .git/objects/ef/49cb59aee81783788c17b5a024bd377f2b119e
in the diagram, you can see what happened: adding content to the file created a new blob. since this had a different sha-1 than the original file content, it meant that we got a new tree to reference it. of course, we have a new commit that references that tree. since
baz.txt
wasn't changed, it continues to point to the original blob. in turn, that means that the directory
bar
hasn't changed, so it can be represented by same tree object.
one interesting thing is to compare the size of the original file, 642,217 bytes, with the 496,994 bytes stored in the repository. git compresses all of its objects (so you can't just
cat
the files). i generated random data for
foo.txt
, which is normally incompressible, but limiting it to alphanumeric characters meant that each character only takes fit in six bits rather than eight. compressing the file saves roughly 25% of its space.
i'm going to diverge from the diagram for the next example because i think it's important to understand that git stores full objects rather than diffs. so, we'll add a few new lines to the file:
> cat /dev/urandom | lang=iso8859-1 sed -e 's/[^ a-za-z0-9]//g' | head -100 >> foo.txtwhen we look at the objects, we see that there is a new blob that is slightly larger than the old one, and that the commit object (c620754c) is nowhere near large enough to hold the change. clearly, the commit does not encapsulate a diff.
13369652 4 -r--r--r-- 1 kgregory kgregory 170 nov 3 10:07 .git/objects/16/c0d98f4476f088c46086583b9ebf76dee03bb9
13369650 4 -r--r--r-- 1 kgregory kgregory 81 nov 3 10:07 .git/objects/bf/21b205ba0ceff1655ca5c8476bbc254748d2b2
13369647 488 -r--r--r-- 1 kgregory kgregory 496994 nov 3 10:07 .git/objects/ef/49cb59aee81783788c17b5a024bd377f2b119e
13369648 492 -r--r--r-- 1 kgregory kgregory 501902 nov 3 10:18 .git/objects/58/2f9a9353fc84a6a3571d3983fbe2a0418007db
13369656 4 -r--r--r-- 1 kgregory kgregory 81 nov 3 10:18 .git/objects/9b/671a1155ddca40deb84af138959d37706a8b03
13369658 4 -r--r--r-- 1 kgregory kgregory 165 nov 3 10:18 .git/objects/c6/20754c351f5462bf149a93bdf0d3d51b7d91a9before moving on, i want to call out git's two-level directory structure. filesystem directories are typically a linear list of files, and searching for a specific filename becomes a significant cost once you have more than a few hundred files. even a small repository, however, may have 10,000 or more objects. a two-level filesystem is the first step to solving this problem; the top level consists of sub-directories with two-character names, representing the first byte of the object's sha-1 hash. each sub-directory only holds those objects whose hashes start with that byte, thereby partitioning the total search space.
large repositories would still be expensive to search, so git also uses “pack” files, stored in
.git/objects/pack
; each pack file contains some large number of commits, indexed for efficient access. you can trigger this compression using
git gc
, although that only affects your local repository. pack files are also used when retrieving objects from a remote repository, so your initial clone gives you a pre-packed object directory.
branches
ok, you've seen how git stores objects. what happens when you create a branch?
> git checkout -b my-branch
switched to a new branch 'my-branch'
> cat /dev/urandom | lang=iso8859-1 sed -e 's/[^ a-za-z0-9]//g' | head -100 >> foo.txt
> git commit -m "add some content in a branch" foo.txt
[my-branch 1791626] add some content in a branch
1 file changed, 100 insertions(+)
if you look in
.git/objects
, you'll see another three objects, and at this point, i assume that you know what they are.
13369648 492 -r--r--r-- 1 kgregory kgregory 501902 nov 3 10:18 .git/objects/58/2f9a9353fc84a6a3571d3983fbe2a0418007db
13369656 4 -r--r--r-- 1 kgregory kgregory 81 nov 3 10:18 .git/objects/9b/671a1155ddca40deb84af138959d37706a8b03
13369658 4 -r--r--r-- 1 kgregory kgregory 165 nov 3 10:18 .git/objects/c6/20754c351f5462bf149a93bdf0d3d51b7d91a9
13510395 4 -r--r--r-- 1 kgregory kgregory 175 nov 3 11:50 .git/objects/17/91626ece8dce3c713261e470a60049553d5411
13377993 496 -r--r--r-- 1 kgregory kgregory 506883 nov 3 11:50 .git/objects/57/c091e77d909f2f20e985150ea922c3ec303ab6
13377996 4 -r--r--r-- 1 kgregory kgregory 81 nov 3 11:50 .git/objects/f2/c824ab04c8f902ab195901e922ab802d8bc37bhow does git know that this commit belongs to a branch? the answer is that git stores that information elsewhere:
> ls -l .git/refs/heads/
total 8
-rw-rw-r-- 1 kgregory kgregory 41 nov 3 10:18 master
-rw-rw-r-- 1 kgregory kgregory 41 nov 3 11:50 my-branch> cat .git/refs/heads/master
c620754c351f5462bf149a93bdf0d3d51b7d91a9
> cat .git/refs/heads/my-branch
1791626ece8dce3c713261e470a60049553d5411
that's it: text files that hold the sha-1 of a commit. there is one additional file,
.git/head
, which says which of those text files represent the “working” branch:
> cat .git/head
ref: refs/heads/my-branch
this isn't quite the entire story. for one thing, it omits tags, stored in
.git/refs/tags
. or “unattached head” state, when
.git/head
holds a commit rather than a ref. and most important, remote branches and their relationship to local branches. but this post (and the talk) are long enough as it is.
merges
you've been making changes to a development branch. now, it's time to merge those changes into master (or an integration branch). it's useful to know what happens when you type
git merge
.
fast-forward merges
the simplest type of merge — indeed, you could argue that it's not really a merge at all because it doesn't create new commits — is a fast-forward merge. this is the sort of merge that we'd get if we merged our example project branch into master.
> git checkout master
switched to branch 'master'
> git merge my-branch
updating c620754..1791626
fast-forward
foo.txt | 100 ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
1 file changed, 100 insertions(+)
as i said, it's not really a merge at all; if you look in
.git/objects
you'll see the same list of files that were there after the last commit. what has changed are the refs:
> ls -l .git/refs/heads/
total 8
-rw-rw-r-- 1 kgregory kgregory 41 nov 3 12:15 master
-rw-rw-r-- 1 kgregory kgregory 41 nov 3 11:50 my-branch> cat .git/refs/heads/master
1791626ece8dce3c713261e470a60049553d5411
> cat .git/refs/heads/my-branch
1791626ece8dce3c713261e470a60049553d5411here's a diagram of what happened, showing the repository state pre- and post-merge:
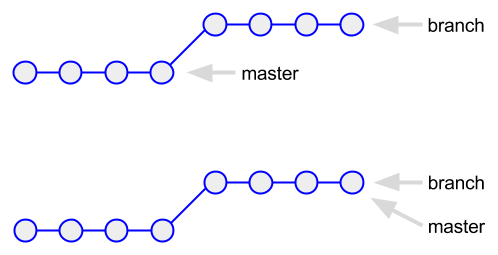
topologically, the “branch” represents a straight line, extending the last commit on
master
. therefore, “merging” the branch is as simple as re-pointing the master reference to that commit.
squashed merges
i'll start this section with a rant. one of the things that i hate when looking at the history of a project is to see a series of commits like this: “added foo”; “added unit test for foo”; “added another testcase for foo”; “fixed foo to cover new testcase” ...really? i don't care what you did to make “foo” work, i just care that you did it. if your commits are interspersed with those of the person working on “bar,” the evolution of the project becomes almost impossible to follow (i'll return to this in the next section).
fortunately, this can be resolved easily with a squash merge:
> git merge --squash my-branch
updating c620754..1791626
fast-forward
squash commit -- not updating head
foo.txt | 100 ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
1 file changed, 100 insertions(+)the “not updating head” part of this message is important. rather than commit the changes, a squash merge leaves them staged and lets you commit (with a summary message) once you've verified the changes. the diagram looks like this:
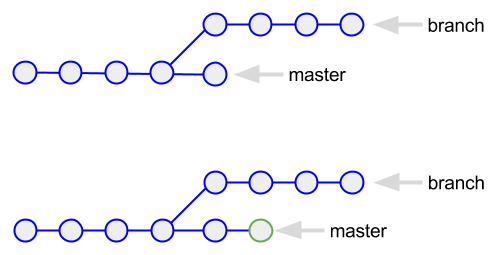
the thing to understand about squashed commits is that they're not actually merges; there's no connection between the branch and master. as a result, “
git branch -d my-branch
” will fail, warning you that it's an unmerged branch; you need to force deletion by replacing
-d
with
-d
.
to wrap up this section, i don't think that you need to squash all merges, just the ones that merge a feature onto master or an integration branch. use normal merges when pulling an integration branch onto master or when back-porting changes from the integration branch to the development branch (i do, however, recommend squashing backports from master to integration).
“normal” merges, with or without conflicts
to understand what i dislike about “normal” merges, we need to do one. for this, we'll create a completely new repository, one where we'll compile our favorite quotes from lewis carroll. we start by creating the file
carroll.txt
in
master
; for this section, i'll just show changes to the file, not the actual commits.
jabberwocky
walrus and carpenter
in order to work independently, one person will make the changes to jabberwocky on a branch named “
jabber
”:
jabberwocky
twas brillig, and the slithy toves
did gire and gimbal in the wabe
all mimsy were the borogroves
and the mome raths outgrabe
walrus and carpenter
after that's checked in, someone else modifies the file on
master
:
jabberwocky
walrus and carpenter
the time has come, the walrus said,
to talk of many things:
of shoes, and ships, and sealing wax
of cabbages, and kings
and why the sea is boiling hot
and whether pigs have wings
back on branch
jabber
, someone has found the actual text and corrected mistakes:
jabberwocky
'twas brillig, and the slithy toves
did gyre and gimble in the wabe
all mimsy were the borogoves
and the mome raths outgrabe
walrus and carpenter
at this point, we have two commits on
jabber
, and one on
master
after the branch was made. if you look at the commit log for
jabber
you see this:
commit 2e68e9b9905b043b06166cf9aa5566d550dbd8ad
author: keith gregory
date: thu nov 3 12:59:40 2016 -0400
fix typos in jabberwocky
commit 5a7d657fb0c322d9d5aca5c7a9d8ef6eb690eaeb
author: keith gregory
date: thu nov 3 12:41:35 2016 -0400 jabberwocky: initial verse commit e2490ffad2ba7032367f94c0bf16ca44e4b28ee6 author: keith gregory
date: thu nov 3 12:39:41 2016 -0400 initial commit, titles without content
and on
master
, this is the commit log:
commit 5269b0742e49a3b201ddc0255c50c37b1318aa9c
author: keith gregory
date: thu nov 3 12:57:19 2016 -0400
favorite verse of walrus
commit e2490ffad2ba7032367f94c0bf16ca44e4b28ee6
author: keith gregory
date: thu nov 3 12:39:41 2016 -0400 initial commit, titles without content
now the question is: what happens when you merge
jabber
onto
master
? in my experience, most people think that the branch commits are added into master based on when they occurred. this is certainly reinforced by the post-merge commit log:
commit 8ba1b90996b4fb67529a2964836f8524a220f2d8
merge: 5269b07 2e68e9b
author: keith gregory
date: thu nov 3 13:03:09 2016 -0400
merge branch 'jabber'
commit 2e68e9b9905b043b06166cf9aa5566d550dbd8ad
author: keith gregory
date: thu nov 3 12:59:40 2016 -0400 fix typos in jabberwocky commit 5269b0742e49a3b201ddc0255c50c37b1318aa9c author: keith gregory
date: thu nov 3 12:57:19 2016 -0400 favorite verse of walrus commit 5a7d657fb0c322d9d5aca5c7a9d8ef6eb690eaeb author: keith gregory
date: thu nov 3 12:41:35 2016 -0400 jabberwocky: initial verse commit e2490ffad2ba7032367f94c0bf16ca44e4b28ee6 author: keith gregory
date: thu nov 3 12:39:41 2016 -0400 initial commit, titles without content
take a closer look at those commit hashes and compare them to the hashes from the separate branches. they're the same, which means that the commits are unchanged. in fact,
git log
walks the parent references of both branches, making it appear that commits are on one branch when they aren't. the diagram actually looks like this (yes, i know, there are two commits too many):
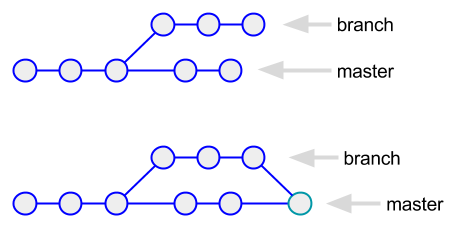
the merge created a new commit, which has two parent references. it also created a new blob to hold the combined file, along with a modified tree. if we run
cat-file
on the merge commit, this is what we get:
tree 589187777a672868e50aefc491ed640125d1e3ed
parent 5269b0742e49a3b201ddc0255c50c37b1318aa9c
parent 2e68e9b9905b043b06166cf9aa5566d550dbd8ad
author keith gregory
1478192589 -0400
committer keith gregory
1478192589 -0400 merge branch 'jabber'
so, what does it mean that
git log
produces the illusion of a series of merged commits? consider what happens when you check out one of the commits in the list, for example
2e68e9b9
.
this was a commit that was made on the branch. if you check out that commit and look at the commit log from that point, you'll see that commit
5269b074
no longer appears. it was made on
master
, in a completely different chain of commits.
in a complex series of merges (say, multiple development branches onto an integration branch and several integration branches onto a feature branch) you can completely lose track of where and why a change was made. if you try to diff your way through the commit history, you'll find that the code changes dramatically between commits, and appears to flip-flop. you're simply seeing the code state on different branches.
wrapping up: how safe is sha-1?
“everybody knows” that sha-1 is a “broken” hash, so why is it the basis for storing objects in git?
the answer to that question has two parts. the first is that sha-1 is “broken” in terms of an attacker being able to create a false message that has the same sha-1 hash as a real message: it takes fewer than the expected number of attempts (although still a lot!). this is a problem if the message that you're hashing is involved in validating a server certificate. it's not a problem in the case of git because at worst, the attacher would be able to replace a single object — you might lose one file within a commit or need to manually rebuild a directory.
that's an active attacker, but what about accidental collisions? let's say that you have a commit with a particular hash and it just so happens that you create a blob with the same hash. it could happen, although the chances are vanishingly small . if it does happen, git ignores the later file .
so don't worry, be happy, and remember to squash features from development branches.
Published at DZone with permission of Keith Gregory. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments