Building Unified, Access-Aware Search in a Data Mesh
By indexing authorization alongside metadata, we delivered fast, trustable search that shows every user exactly what they’re allowed to see
Join the DZone community and get the full member experience.
Join For FreeOver the last few years, I have worked on a distributed data platform in which each engineering group owns the data it produces from heterogeneous data processing systems. Our central platform follows a data mesh model, as every domain manages its own pipelines and storage, but discovery in the unified system should be seamless to anyone searching across the mesh. That goal sounded simple, but wasn’t that simple considering we host datasets from ultra and black undisclosed products.
The first complaint we heard, repeatedly:
“I know the dataset exists, but how can I find it without having access to it?”
Usually, the dataset existed. It was just invisible in someone else's catalog, labeled differently, or hidden by access rules that refused to allow the dataset to be discovered. That feedback forced us to rebuild discovery so users could see everything they’re allowed to see, and nothing more.
This post walks through the four-layer architecture that made that possible.
What Unified Search Means in a Mesh
The platform had to surface more than datasets. Our search index needed to cover:
- Analytical datasets across warehouses and lakes
- ML models and feature stores
- Lineage graphs
- Policy and classification tags
- Search-driven documentation and usage signals
And the most important rule: search must return only what the user can actually access, not “search then filter.” Even revealing the name of a restricted dataset is a leak.
We also discovered that access-aware search isn’t just about security, but it builds trust across our customers. When results feel incomplete, people stop using the platform.
Architectural Layers
We ended up with a four-layer architecture:
- Discovery – asset registration and metadata standardization
- Enrichment – attach lineage, compliance, and popularity data
- Indexing – store enriched assets in text and vector indexes
- Authorization – enforce access control before scoring results
Each layer does one thing well, and we made sure that strict functional boundaries are explicit when implementing it.
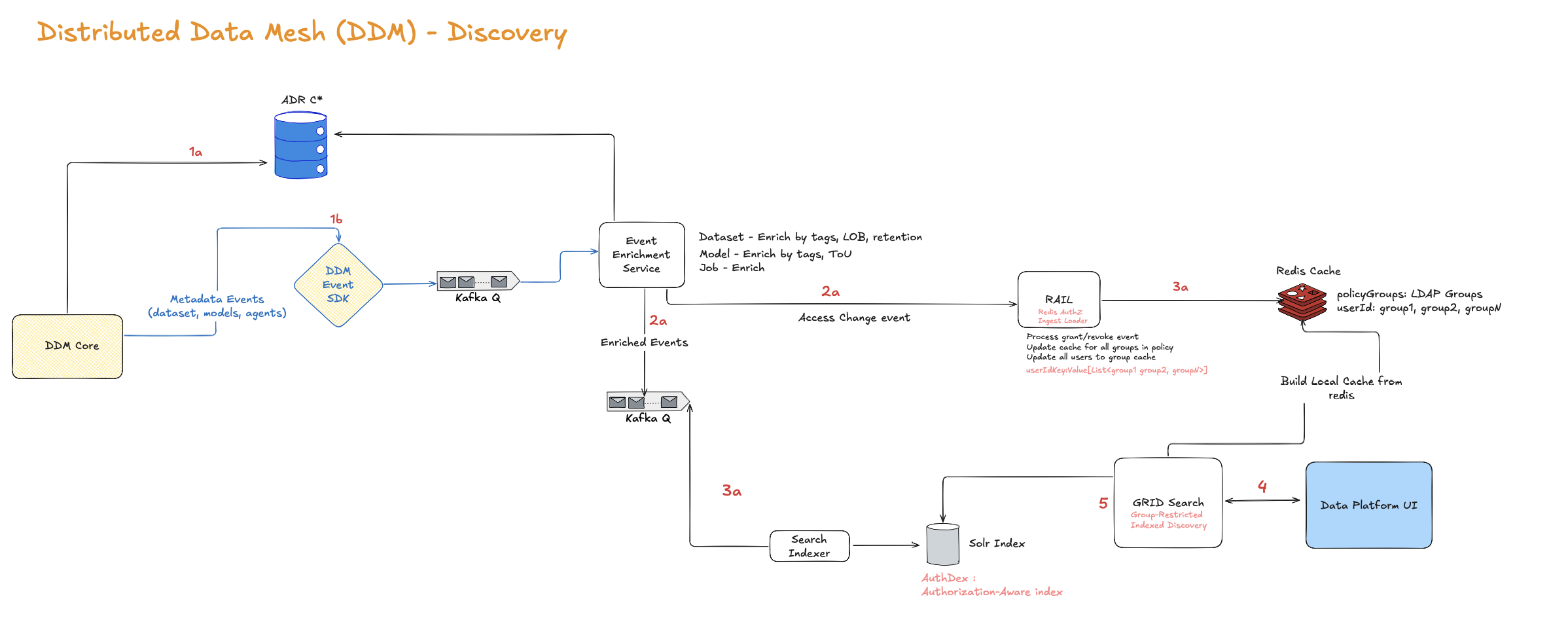
Layer 1: Discovery
The discovery layer handles asset registration, producers publish schemas, ownership, tags, policies, and lineage to a central metadata catalog. Each asset gets a consistent representation, no matter which domain or compute platform created it.
Example metadata event:
{
"dataset": "sales.customer",
"owner": "retail_analytics",
"tags": ["pii", "financial"],
"policy": "restricted",
"lineage": {
"upstream": ["raw.transactions", "raw.customers"],
"downstream": ["reports.customer_ltv"]
},
"schema": {
"columns": [
{"name": "customer_id", "type": "string", "pii": false},
{"name": "email", "type": "string", "pii": true},
{"name": "revenue", "type": "decimal", "pii": false}
]
}
}Lineage is important for propagated permissioning. If dataset B contains data from dataset A, and A is restricted, B inherits that restriction. Our first version ignored this and accidentally exposed derived datasets.
Layer 2: Enrichment
Every metadata change becomes an event on Kafka. An enrichment consumer subscribes and adds context: lineage links from a graph store, compliance labels from tag combinations, and popularity scores from query logs, or adds a description.
Example:
class EnrichmentConsumer:
def __init__(self, kafka_consumer, lineage_client, compliance_engine):
self.consumer = kafka_consumer
self.lineage = lineage_client
self.compliance = compliance_engine
def process(self, event):
# Resolve full lineage graph
upstream = self.lineage.get_ancestors(event.dataset)
downstream = self.lineage.get_descendants(event.dataset)
# Derive compliance labels from tags
if "pii" in event.tags:
event.compliance_labels.add("gdpr_subject")
if "financial" in event.tags:
event.compliance_labels.add("sox_relevant")
# Propagate restrictions from upstream
inherited_policy = self.compliance.max_restriction(upstream)
event.effective_policy = max(event.policy, inherited_policy)
# Compute popularity score
event.popularity = self.query_logs.get_access_count(event.dataset)
return EnrichedAsset(event, upstream, downstream)The effective_policy field merges declared and inherited rules. Also, in some cases, because security metadata changes faster than schemas, enrichment recomputes this for every event, not just at registration.
Layer 3: Indexing
Enriched assets flow into two parallel indexes optimized for different query types:
- Text search (Elasticsearch/Lucene): filters and keyword queries such as “datasets tagged PII owned by
retail_analytics.” - Vector search (FAISS or Elastic kNN): semantic similarity like "datasets similar to our churn model" even if names differ.
Both share the same document structure:
# Elasticsearch mapping
asset_mapping = {
"properties": {
"dataset": {"type": "keyword"},
"owner": {"type": "keyword"},
"tags": {"type": "keyword"},
"description": {"type": "text"},
"effective_policy": {"type": "keyword"},
"allowed_groups": {"type": "keyword"}, # Pre-computed access list
"embedding": {
"type": "dense_vector",
"dims": 384,
"index": true,
"similarity": "cosine"
}
}
}The allowed_groups field is key. We pre-compute which user groups can access each asset and store that list directly in the index. That shifts permission checks from query time to index time.
Layer 4: Authorization
At query time, authorization runs before scoring or ranking. Our first approach checked permissions via API calls for every result, which reduced latency from 150 ms to nearly 20s.
The fix: keep a local cache of user-group memberships next to the search engine and apply them as pre-filters.
class AuthorizationFilter:
def __init__(self, group_cache):
self.group_cache = group_cache # Redis or local cache
def build_filter(self, user_id):
# Fetch user's group memberships from cache
user_groups = self.group_cache.get_groups(user_id)
# Build Elasticsearch terms filter
return {
"bool": {
"filter": {
"terms": {
"allowed_groups": list(user_groups)
}
}
}
}
def execute_search(self, user_id, query):
auth_filter = self.build_filter(user_id)
# Merge auth filter with user's search query
filtered_query = {
"query": {
"bool": {
"must": query,
"filter": auth_filter["bool"]["filter"]
}
}
}
return self.es_client.search(filtered_query)This reduced response time back under 200 ms and guaranteed that restricted datasets never appear in the candidate set.
Search Execution Flow
- Fetch user group membership from cache
- Build an allowed-document filter
- Apply the filter before scoring
- Run search and ranking only on the permitted corpus
Latency stays constant as authorization rules grow, and users no longer stumble across off-limits assets.
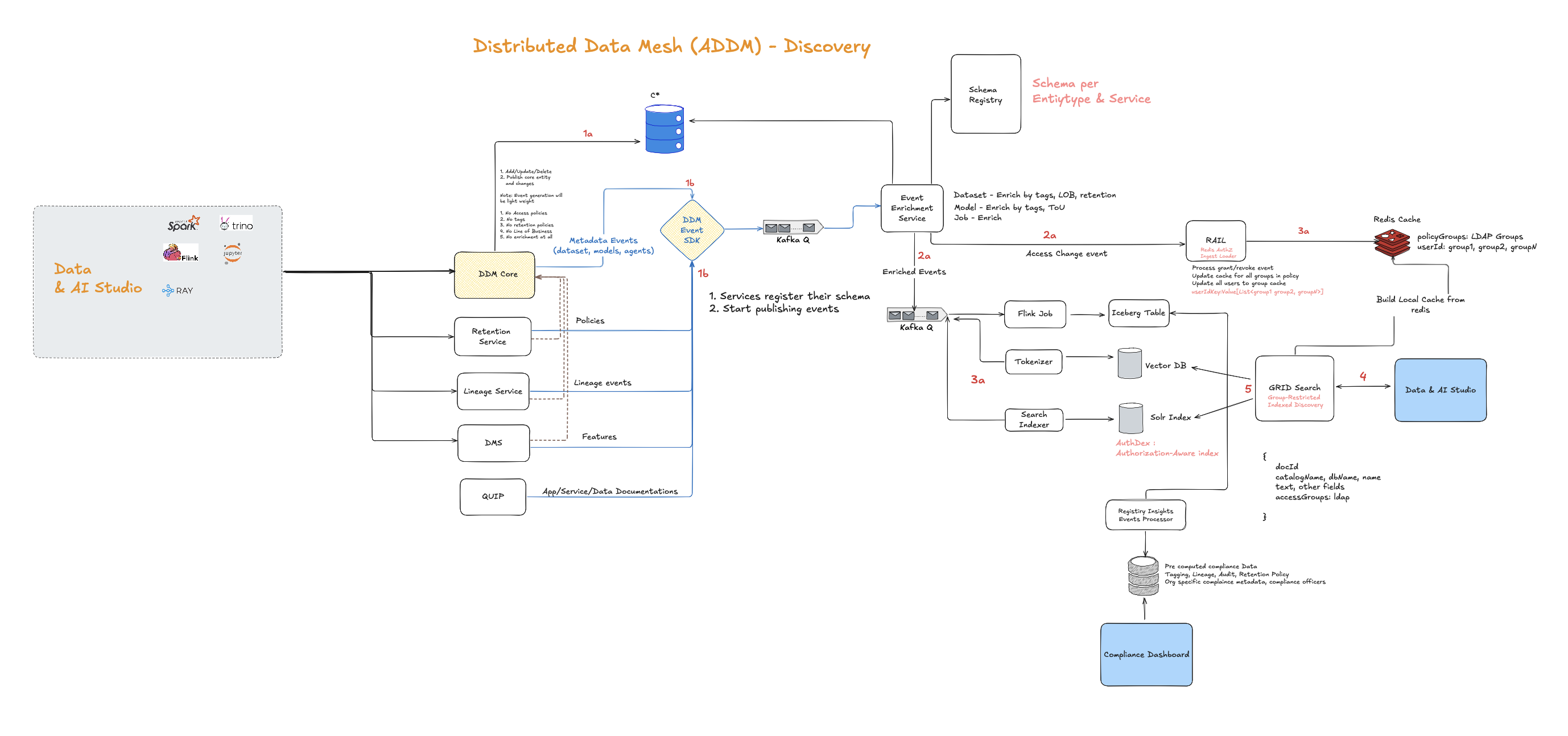
The Hard Problems You Don’t See on the Whiteboard
- Lineage means inherited access. If dataset B uses data from A, B inherits A’s restrictions. We enforce this in enrichment.
- Security metadata changes faster than schemas. Group memberships change constantly, so index segments must refresh in real time.
- Even embeddings follow governance. If a description contains red-flag terms, we apply tighter vector-index restrictions.
What Worked Well
After rollout, the improvements were clear:
- Fewer duplicate tables
- Higher reuse of curated datasets
- Search logs exposed ownership gaps
- More documentation contributions from data consumers
Search became both a discovery tool and a quality feedback loop.
Closing Thoughts
In a data mesh, discovery is where the design of how data is indexed is tested. Indexing documents is easy. Indexing real-time authorization is operationally a hard job.
The four-layer design - discovery, enrichment, indexing, authorization - turns an open-ended search problem into a predictable pipeline. Each layer has a clear contract, and authorization becomes data, not runtime checks.
When search results respect both data structure and access rules, engineers stop second-guessing what they see. That confidence is what makes a mesh truly work.
Opinions expressed by DZone contributors are their own.
Comments