Using AWS S3 for Database Backup Storage
Database backups allow restoring upon database failures and recovering from data corruption. AWS S3 is an affordable, highly durable and reliable storage option.
Join the DZone community and get the full member experience.
Join For FreeDatabase backup is an important operation to consider for any database system. Taking backups not only allows restoring upon database failures but also recovering from data corruption. However, storing a backup in durable and reliable storage can be expensive. Cloud services like AWS S3 provide highly durable and reliable storage for database backups while reducing costs with archival facilities using AWS Glacier.
So what are the key characteristics that make AWS S3 suitable for database backup storage?
AWS S3 provides 99.999999999% durability by replicating the data across multiple physical facilities, avoiding a single point of failure. In combination with encrypting data at rest and access control mechanisms, S3 provides support for security standards and compliance certifications including PCI-DSS, HIPAA/HITECH, FedRAMP, EU Data Protection Directive, and FISMA, helping to satisfy compliance requirements.
Creating Database Dumps
Depending on the database system, the approach in taking database backups can differ. Taking backups of relational databases like MySQL, Postgres can be done using database dump tools that allow taking point-in-time snapshots of the database to a file. NoSQL databases like MongoDB also provide support for database dumps.
It is important to periodically create database snapshots in accordance with the RTO (Recovery Time Objectives) and RPO (Recovery Point Objectives) of the applications.
When taking backups, it is important to understand that the operation is resource intensive (IO, in particular) and can cause outages for the application. Therefore, it is required to select appropriate timings and use strategies like taking backups from read-only replicas of relational databases and from clusters with throttling utilities for NoSQL databases.
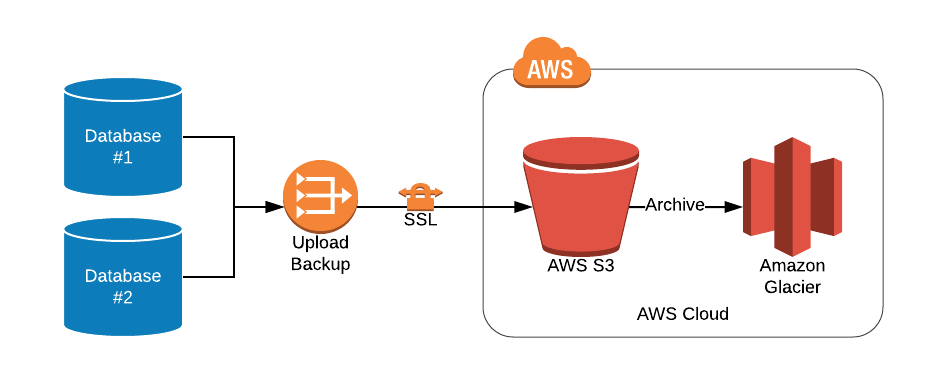
Uploading Backups to S3
Uploading MySQL, Postgres, and MongoDB backup to S3 is straightforward. AWS S3 provides CLI (command line interface) with a command to upload files directly to S3 buckets.
aws s3 cp /tmp/foo/ s3://bucket/ --recursiveIf the backups contain multiple files and only the difference needs to be uploaded, AWS CLI commands like sync can be used.
aws s3 sync . s3://mybucketHowever, it is important to have a proper backup file naming convention and versioning enabled at S3 buckets to reduce the risk of overwriting existing files. This can also be achieved using access control, preventing file deletion using bucket and IAM policies.
Backup Security
Backup files uploaded to S3 are encrypted in transit using HTTPS. S3 provides optional configurations to encrypt files at rest with following encryption mechanisms.
- Server-side encryption: You request Amazon S3 to encrypt your object before saving it on disks in its data centers and decrypt it when you download the objects.
- Client-side encryption: You can encrypt data on the client side and upload the encrypted data to Amazon S3. In this case, you manage the encryption process, the encryption keys, and the related tools.
Reducing the Size of Backups
Database backups can be from several megabytes to terabytes and will consume large amounts of storage space over time. However, the content inside most of the backups is textual with higher compression factors. Therefore, it is important to compress the backups with utilizing like GZip not only to reduce the storage consumption but also to move the backups to different storage locations for short and long-term storage archives.
Archiving Backups
Generally, AWS S3 can be considered the first-level database backup archival solution. The costs for backups can be further reduced using S3 lifecycle rules to move the backups to AWS Glacier, further reducing storage costs. However, after moving the old backups to Glacier, it will increase the retrieval time up to several hours depending on storage configurations and retrieval plans with Glacier.
Opinions expressed by DZone contributors are their own.
Comments