Using Zero-Width Assertions in Regular Expressions
Explore anchors, lookahead, and lookbehind assertions, which allow you to manage which characters will be included in a match and more.
Join the DZone community and get the full member experience.
Join For FreeAnchors ^ $ \b \A \Z
Anchors in regular expressions allow you to specify the context in a string where your pattern should be matched. There are several types of anchors:
^matches the start of a line (in multiline mode) or the start of the string (by default).$matches the end of a line (in multiline mode) or the end of the string (by default).\Amatches the start of the string.\Zor\zmatches the end of the string.\bmatches a word boundary (before the first letter of a word or after the last letter of a word).\Bmatches a position that is not a word boundary (between two letters or between two non-letter characters).
These anchors are supported in Java, PHP, Python, Ruby, C#, and Go. In JavaScript, \A and \Z are not supported, but you can use ^ and $ instead of them; just remember to keep the multiline mode disabled.
For example, the regular expression ^abc will match the start of a string that contains the letters "abc". In multiline mode, the same regex will match these letters at the beginning of a line. You can use anchors in combination with other regular expression elements to create more complex matches. For example, ^From: (.*) matches a line starting with From:
The difference between \Z and \z is that \Z matches at the end of the string but also skips a possible newline character at the end. In contrast, \z is more strict and matches only at the end of the string.
If you have read the previous article, you may wonder if the anchors add any additional capabilities that are not supported by the three primitives (alternation, parentheses, and the star for repetition). The answer is that they do not, but they change what is captured by the regular expression. You can match a line starting with abc by explicitly adding the newline character: \nabc, but in this case, you will also match the newline character itself. When you use ^abc, the newline character is not consumed.
In a similar way, ing\b matches all words ending with ing. You can replace the anchor with a character class containing non-letter characters (such as spaces or punctuation): ing\W, but in this case, the regular expression will also consume the space or punctuation character.
If the regular expression starts with ^ so that it only matches at the start of the string, it's called anchored. In some programming languages, you can do an anchored match instead of a non-anchored search without using ^. For example, in PHP (PCRE), you can use the A modifier.
So the anchors don't add any new capabilities to the regular expressions, but they allow you to manage which characters will be included in the match or to match only at the beginning or end of the string. The matched language is still regular.
Zero-Width Assertions (?= ) (?! ) (?<= ) (?<! )
Zero-width assertions (also called lookahead and lookbehind assertions) allow you to check that a pattern occurs in the subject string without capturing any of the characters. This can be useful when you want to check for a pattern without moving the match pointer forward.
There are four types of lookaround assertions:
(?=abc) |
The next characters are “abc” (a positive lookahead) |
(?!abc) |
The next characters are not “abc” (a negative lookahead) |
(?<=abc) |
The previous characters are “abc” (a positive lookbehind) |
(?<!abc) |
The previous characters are not “abc” (a negative lookbehind) |
Zero-width assertions are generalized anchors. Just like anchors, they don't consume any character from the input string. Unlike anchors, they allow you to check anything, not only line boundaries or word boundaries. So you can replace an anchor with a zero-width assertion, but not vice versa. For example, ing\b could be rewritten as ing(?=\W|$).
Zero-width lookahead and lookbehind are supported in PHP, JavaScript, Python, Java, and Ruby. Unfortunately, they are not supported in Go.
Just like anchors, zero-width assertions still match a regular language, so from a theoretical point of view, they don't add anything new to the capabilities of regular expressions. They just make it possible to skip certain things from the captured string, so you only check for their presence but don't consume them.
Checking Strings After and Before the Expression
The positive lookahead checks that there is a subexpression after the current position. For example, you need to find all div selectors with the footer ID and remove the div part:
| Search for | Replace to | Explanation |
div(?=#footer) |
“div” followed by “#footer” |
(?=#footer) checks that there is the #footer string here, but does not consume it. In div#footer, only div will match. A lookahead is zero-width, just like the anchors.
In div#header, nothing will match, because the lookahead assertion fails.
Of course, this can be solved without any lookahead:
| Search for | Replace to | Explanation |
div#footer |
#footer |
A simpler equivalent |
Generally, any lookahead after the expression can be rewritten by copying the lookahead text into a replacement or by using backreferences.
In a similar way, a positive lookbehind checks that there is a subexpression before the current position:
| Search for | Replace to | Explanation |
(?<=<a href=")news/ |
blog/ |
Replace “news/” preceded by “<a href="” with “blog/” |
<a href="news/ |
<a href="blog/ |
The same replacement without lookbehind |
The positive lookahead and lookbehind lead to a shorter regex, but you can do without them in this case. However, these were just basic examples. In some of the following regular expressions, the lookaround will be indispensable.
Testing the Same Characters for Multiple Conditions
Sometimes you need to test a string for several conditions.
For example, you want to find a consonant without listing all of them. It may seem simple at first: [^aeiouy] However, this regular expression also finds spaces and punctuation marks, because it matches anything except a vowel. And you want to match any letter except a vowel. So you also need to check that the character is a letter.
(?=[a-z])[^aeiouy] |
A consonant |
[bcdfghjklmnpqrstvwxz] |
Without lookahead |
There are two conditions applied to the same character here:
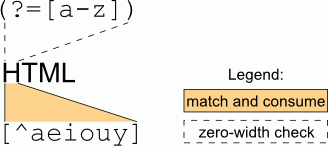
After (?=[a-z]) is checked, the current position is moved back because a lookahead has a width of zero: it does not consume characters, but only checks them. Then, [^aeiouy] matches (and consumes) one character that is not a vowel. For example, it could be H in HTML.
The order is important: the regex [^aeiouy](?=[a-z]) will match a character that is not a vowel, followed by any letter. Clearly, it's not what is needed.
This technique is not limited to testing one character for two conditions; there can be any number of conditions of different lengths:
border:(?=[^;}]*\<solid\>)(?=[^;}]*\<red\>)(?=[^;}]*\<1px\>)[^;}]* |
Find a CSS declaration that contains the words solid, red, and 1px in any order. |
This regex has three lookahead conditions. In each of them, [^;}]* skips any number of any characters except ; and } before the word. After the first lookahead, the current position is moved back and the second word is checked, etc.
The anchors \< and \> check that the whole word matches. Without them, 1px would match in 21px.
The last [^;}]* consumes the CSS declaration (the previous lookaheads only checked the presence of words, but didn't consume anything).
This regular expression matches {border: 1px solid red}, {border: red 1px solid;}, and {border:solid green 1px red} (different order of words; green is inserted), but doesn't match {border:red solid} (1px is missing).
Simulating Overlapped Matches
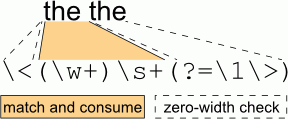
If you need to remove repeating words (e.g., replace the the with just the), you can do it in two ways, with and without lookahead:
| Search for | Replace to | Explanation |
\<(\w+)\s+(?=\1\>) |
Replace the first of repeating words with an empty string | |
\<(\w+)\s+\1\> |
\1 |
Replace two repeating words with the first word |
The regex with lookahead works like this: the first parentheses capture the first word; the lookahead checks that the next word is the same as the first one.
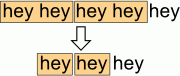
The two regular expressions look similar, but there is an important difference. When replacing 3 or more repeating words, only the regex with lookahead works correctly. The regex without lookahead replaces every two words. After replacing the first two words, it moves to the next two words because the matches cannot overlap:
However, you can simulate overlapped matches with lookaround. The lookahead will check that the second word is the same as the first one. Then, the second word will be matched against the third one, etc. Every word that has the same word after it will be replaced with an empty string:
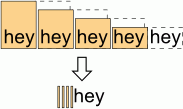
The correct regex without lookahead is \<(\w+)(\s+\1)+\> It matches any number of repeating words (not just two of them).
Checking Negative Conditions
The negative lookahead checks that the next characters do NOT match the expression in parentheses. Just like a positive lookahead, it does not consume the characters. For example, (?!toves) checks that the next characters are not “toves” without including them in the match.
<\?(?!php) |
“<?” without “php” after it |
This pattern will match <? in <?echo 'text'?> or in <?xml.
Another example is an anagram search. To find anagrams for “mate”, check that the first character is one of M, A, T, or E. Then, check that the second character is one of these letters and is not equal to the first character. After that, check the third character, which has to be different from the first and the second one, etc.
\<([mate])(?!\1)([mate])(?!\1)(?!\2)([mate])(?!\1)(?!\2)(?!\3)([mate])\> |
Anagram for “mate” |
The sequence (?!\1)(?!\2) checks that the next character is not equal to the first subexpression and is not equal to the second subexpression.
The anagrams for “mate” are: meat, team, and tame. Certainly, there are special tools for anagram search, which are faster and easier to use.
A lookbehind can be negative, too, so it's possible to check that the previous characters do NOT match some expression:
\w+(?<!ing)\b |
A word that does not end with “ing” (the negative lookbehind) |
In most regex engines, a lookbehind must have a fixed length: you can use character lists and classes ([a-z] or \w), but not repetitions such as * or +. Aba is free from this limitation. You can go back by any number of characters; for example, you can find files not containing a word and insert some text at the end of such files.
| Search for | Replace to | Explanation |
(?<!Table of contents.*)$$ |
<a href="/toc">Contents</a> |
Insert the link to the end of each file not containing the words “Table of contents” |
^^(?!.*Table of contents) |
<a href="/toc">Contents</a> |
Insert it to the beginning of each file not containing the words |
However, you should be careful with this feature because an unlimited-length lookbehind can be slow.
Controlling Backtracking
A lookahead and a lookbehind do not backtrack; that is, when they have found a match and another part of the regular expression fails, they don't try to find another match. It's usually not important, because lookaround expressions are zero-width. They consume nothing and don't move the current position, so you cannot see which part of the string they match.
However, you can extract the matching text if you use a subexpression inside the lookaround. For example:
| Search for | Replace to | Explanation |
(?=\<(\w+)) |
\1 |
Repeat each word |
Since lookarounds don't backtrack, this regular expression never matches:
(?=(\N*))\1\N |
A regex that doesn't backtrack and always fails |
\N*\N |
A regex that backtracks and succeeds on non-empty lines |
The subexpression (\N*) matches the whole line. \1 consumes the previously matched subexpression and \N tries to match the next character. It always fails because the next character is a newline.
A similar regex without lookahead succeeds because when the engine finds that the next character is a newline, \N* backtracks. At first, it has consumed the whole line (“greedy” match), but now it tries to match less characters. And it succeeds when \N* matches all but the last character of the line and \N matches the last character.
It's possible to prevent excessive backtracking with a lookaround, but it's easier to use atomic groups for that.
In a negative lookaround, subexpressions are meaningless because if a regex succeeds, negative lookarounds in it must fail. So, the subexpressions are always equal to an empty string. It's recommended to use a non-capturing group instead of the usual parentheses in a negative lookaround.
(?!(a))\1 |
A regex that always fails: (not A) and A |
Published at DZone with permission of Peter Kankowski. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments