Vector Database: A Beginner's Guide
Enter vector databases, a technological innovation that has emerged as a solution to the challenges posed by the ever-expanding landscape of data.
Join the DZone community and get the full member experience.
Join For FreeIn the age of burgeoning data complexity and high-dimensional information, traditional databases often fall short when it comes to efficiently handling and extracting meaning from intricate datasets. Enter vector databases, a technological innovation that has emerged as a solution to the challenges posed by the ever-expanding landscape of data.
Understanding Vector Databases
Vector databases have gained significant importance in various fields due to their unique ability to efficiently store, index, and search high-dimensional data points, often referred to as vectors. These databases are designed to handle data where each entry is represented as a vector in a multi-dimensional space. The vectors can represent a wide range of information, such as numerical features, embeddings from text or images, and even complex data like molecular structures.
Let's represent the vector database using a 2D grid where one axis represents the color of the animal (brown, black, white) and the other axis represents the size (small, medium, large).
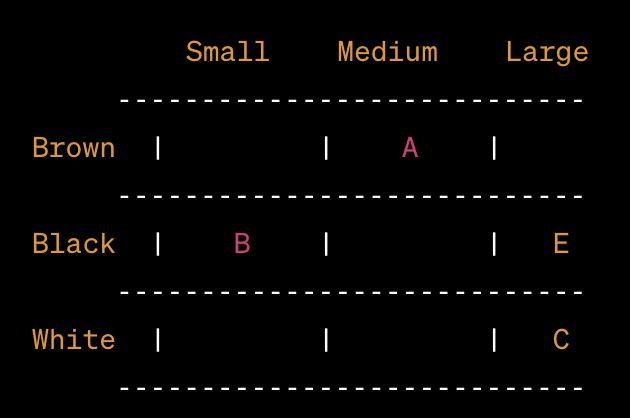
In this representation:
- Image A: Brown color, Medium size
- Image B: Black color, Small size
- Image C: White color, Large size
- Image E: Black color, Large size
You can imagine each image as a point plotted on this grid based on its color and size attributes. This simplified grid captures the essence of how a vector database could be represented visually, even though the actual vector spaces might have many more dimensions and use sophisticated techniques for search and retrieval.
Explain Vector Databases Like I’m Five
Imagine you have a bunch of different types of fruit, like apples, oranges, bananas, and grapes. You love the taste of apples and want to find other fruits that taste similar to apples. Instead of sorting the fruits by their colors or sizes, you decide to group them based on how sweet or sour they are.

So, you put all the sweet fruits together, like apples, grapes, and ripe bananas. You put the sour fruits in another group, like oranges and unripe bananas. Now, when you want to find fruits that taste like apples, you just look in the group of sweet fruits because they're more likely to have a similar taste.
But what if you're looking for something specific, like a fruit that's as sweet as an apple but also has a tangy flavor like an orange? It might be a bit hard to find in your groups, right? That's when you ask someone who knows a lot about different fruits, like a fruit expert. They can suggest a fruit that matches your unique taste request because they know about the flavors of many fruits.
In this case, that knowledgeable person is acting like a "vector database." They have a lot of information about different fruits and can help you find one that fits your special taste, even if it's not based on the usual things like colors or shapes.
Similarly, a vector database is like this helpful expert for computers. It's designed to remember lots of details about things, like food, in a special way. So, if you're looking for a food that's similar in taste to something you love or a food with a combination of flavors you enjoy, this vector database can quickly find the right options for you. It's like having a flavor expert for computers who knows all about tastes and can suggest great choices based on what you're craving, just like that knowledgeable person with fruit.
How Do Vector Databases Store Data?
Vector databases store data by using vector embeddings. Vector embeddings in vector databases refer to a way of representing objects, such as items, documents, or data points, as vectors in a multi-dimensional space. Each object is assigned a vector that captures various characteristics or features of that object. These vectors are designed in such a way that similar objects have vectors that are closer to each other in the vector space, while dissimilar objects have vectors that are farther apart.
Think of vector embeddings as a special code that describes the important aspects of an object. Imagine you have different animals, and you want to represent them in a way that similar animals have similar codes. For instance, cats and dogs might have codes that are quite close, as they share common features like being four-legged and having fur. On the other hand, animals like fish and birds would have codes that are further apart, reflecting their differences.
In a vector database, these embeddings are used to store and organize objects. When you want to find objects that are similar to a given query, the database looks at the embeddings and calculates the distances between the query's embedding and the embeddings of other objects. This helps the database quickly identify objects that are most similar to the query.
For example, in a music streaming app, songs could be represented as vectors using embeddings that capture musical features like tempo, genre, and instruments used. When you search for songs similar to your favorite track, the app's vector database would compare the embeddings to find songs that match your preferences closely.
Vector embeddings are a way of turning complex objects into numerical vectors that capture their characteristics, and vector databases use these embeddings to efficiently search and retrieve similar or relevant objects based on their positions in the vector space.
How Do Vector Databases Work?
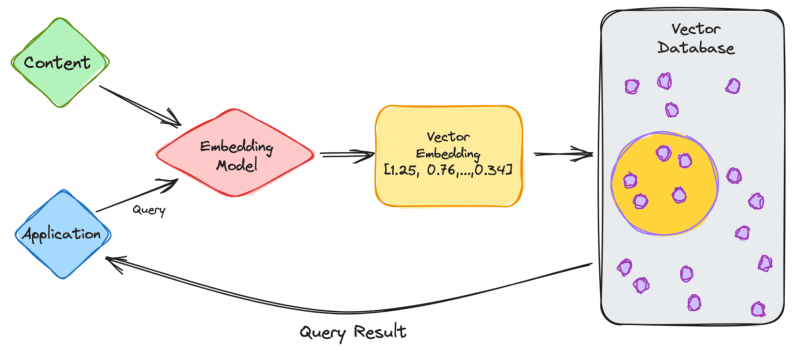
Image credits: KDnuggets
User Query
- You input a question or request into the ChatGPT application.
Embedding Creation
- The application converts your input into a compact numerical form called a vector embedding.
- This embedding captures the essence of your query in a mathematical representation.
Database Comparison
- The vector embedding is compared with other embeddings stored in the vector database.
- Similarity measures help identify the most related embeddings based on content.
Output Generation
- The database generates a response composed of embeddings closely matching your query's meaning.
User Response
- The response, containing relevant information linked to the identified embeddings, is sent back to you.
Follow-up Queries
- When you make subsequent queries, the embedding model generates new embeddings.
- These new embeddings are used to find similar embeddings in the database, connecting back to the original content.
How Vector Databases Know Which Vectors Are Similar
A vector database determines the similarity between vectors using various mathematical techniques, with one of the most common methods being cosine similarity.
When you search for "Best cricket player in the world" on Google, and it shows a list of top players, there are several steps involved, of which cosine similarity is the main one.
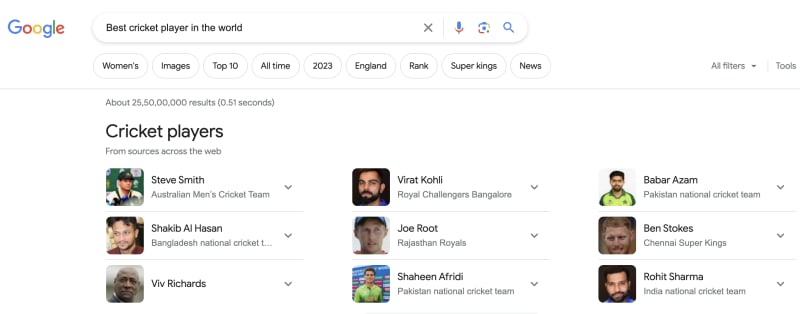
The vector representation of the search query is compared to the vector representations of all the player profiles in the database using cosine similarity. The more similar the vectors are, the higher the cosine similarity score.
Note: Well, this is just for the sake of an example. it's important to note that search engines like Google use complex algorithms that go beyond simple vector similarity. They consider various factors such as the user's location, search history, authority of the sources, and more to provide the most relevant and personalized search results.
Vector Database Capabilities
The significance of vector databases lies in their capabilities and applications:
Efficient Similarity Search
Vector databases excel at performing similarity searches, where you can retrieve vectors that are most similar to a given query vector. This is crucial in various applications like recommendation systems (finding similar products or content), image and video retrieval, facial recognition, and information retrieval.
High-Dimensional Data
Traditional relational databases struggle with high-dimensional data because of the "curse of dimensionality," where distances between data points become less meaningful as the number of dimensions increases. Vector databases are designed to handle high-dimensional data more efficiently, making them suitable for applications like natural language processing, computer vision, and genomics.
Machine Learning and AI
Vector databases are often used to store embeddings generated by machine learning models. These embeddings capture the essential features of the data and can be used for various tasks, such as clustering, classification, and anomaly detection.
Real-Time Applications
Many vector databases are optimized for real-time or near-real-time querying, making them suitable for applications that require quick responses, such as recommendation systems in e-commerce, fraud detection, and monitoring IoT sensor data.
Personalization and User Profiling
Vector databases enable personalized experiences by allowing systems to understand and predict user preferences. This is crucial in platforms like streaming services, social media, and online marketplaces.
Spatial and Geographic Data
Vector databases can handle geographic data, such as points, lines, and polygons, efficiently. This is essential in applications like geographical information systems (GIS), location-based services, and navigation applications.
Healthcare and Life Sciences
In genomics and molecular biology, vector databases are used to store and analyze genetic sequences, protein structures, and other molecular data. This helps in drug discovery, disease diagnosis, and personalized medicine.
Data Fusion and Integration
Vector databases can integrate data from various sources and types, enabling more comprehensive analysis and insights. This is valuable in scenarios where data comes from multiple modalities, such as combining text, image, and numerical data.
Multilingual Search
Vector databases can be used to create powerful multilingual search engines by representing text documents as vectors in a common space, enabling cross-lingual similarity searches.
Graph Data
Vector databases can represent and process graph data efficiently, which is crucial in social network analysis, recommendation systems, and fraud detection.
The Crucial Role of Vector Databases in Today’s Data Landscape
Vector databases are experiencing high demand due to their essential role in tackling the challenges posed by the explosion of high-dimensional data in modern applications.
As industries increasingly adopt technologies like machine learning, artificial intelligence, and data analytics, the need to efficiently store, search, and analyze complex data representations has become paramount. Vector databases enable businesses to harness the power of similarity search, personalized recommendations, and content retrieval, driving enhanced user experiences and improved decision-making.
With applications ranging from e-commerce and content platforms to healthcare and autonomous vehicles, the demand for vector databases stems from their ability to handle diverse data types and deliver accurate results in real time. As data continues to grow in complexity and volume, the scalability, speed, and accuracy offered by vector databases position them as a critical tool for extracting meaningful insights and unlocking new opportunities across various domains.
SingleStore as a Vector Database
Harness the robust vector database capabilities of SingleStoreDB, tailored to seamlessly serve AI-driven applications, chatbots, image recognition systems, and more. With SingleStoreDB at your disposal, the necessity for maintaining a dedicated vector database for your vector-intensive workloads becomes obsolete.
Diverging from conventional vector database approaches, SingleStoreDB takes a novel approach by housing vector data within relational tables alongside diverse data types. This innovative amalgamation empowers you to effortlessly access comprehensive metadata and additional attributes pertaining to your vector data, all while leveraging the extensive querying prowess of SQL.
SingleStoreDB has been meticulously architected with a scalable framework, ensuring unfaltering support for your burgeoning data requirements. Say goodbye to limitations and embrace a solution that grows in tandem with your data demands.
Example of Face Matching With SQL in SingleStore
We loaded 16,784,377 rows into this table:
create table people(
id bigint not null primary key,
filename varchar(255),
vector blob
);
Each row represents one image of a celebrity and contains a unique ID number, the file name where the image is stored, and a 128-element floating point vector representing the meaning of the face. This vector was obtained using facenet, a pre-trained neural network for creating vector embeddings from a face image.
Don't worry; you don't need to understand the AI to use this kind of approach — you just need to use somebody else's pre-trained neural network or any tool that can provide you with summary vectors for an object.
Now, we query this table using:
select vector
into @v
from people
where filename = "Emma_Thompson/Emma_Thompson_0001.jpg";
select filename, dot_product(vector, @v) as score
from people where score > 0.1
order by score desc
limit 5;
The first query gets a query vector @v for the image Emma_Thompson_0001.jpg. The second query finds the top five closest matches:
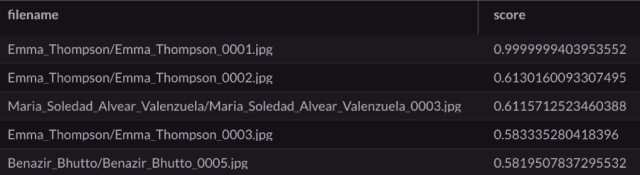
Emma_Thompson_0001.jpg is a perfect match for itself, so the score is close to 1. But interestingly, the next closest match is Emma_Thompson_0002.jpg. Here are the query image and closest match:

Moreover, the search speed we obtained was truly incredible. The 2nd query took only 0.005 seconds on a 16 vcpu machine. And it processed all 16M vectors. This is a rate of over 3.3 billion vector matches per second.
The significance of vector databases stems from their ability to handle complex, high-dimensional data while offering efficient querying and retrieval mechanisms. As data continues to grow in complexity and volume, vector databases are becoming increasingly vital in a wide range of applications across industries.
Published at DZone with permission of Pavan Belagatti. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments