Benefits of Data Ingestion
This article discusses that by using appropriate data ingestion tools, companies can collect, import, process data for later use or storage in a database.
Join the DZone community and get the full member experience.
Join For FreeIntroduction
In the last two decades, many businesses have had to change their models as business operations continue to complicate. The major challenge companies face today is that a large amount of data is generated from multiple data sources. So, data analytics have introduced filters to various data sources to detect this problem. They need analytics and business intelligence to access all their data sources to make better business decisions.
It is obvious that the company needs this data to make decisions based on predicted market trends, market forecasts, customer requirements, future needs, etc. But how do you get all your company data in one place to make a proper decision? Data ingestion consolidates your data and stores it in one place.
Data ingestion is one of the primary stages of the data handling process. By using appropriate data ingestion tools companies can collect, import, process data for later use or storage in a database.
The data can be collected from any source or it can be any type such as RDBMS, CSV, database, or form stream. Since data is collected from various sources, it has to be cleaned up and altered to be understood and analyzed.
Data serves as a backbone for any company's future plans and projections. Companies have to understand their audience, their needs, and their behavior in order to stand against market competition. All these things enable companies to make better products, make better decisions, run advertising campaigns, give user recommendations, and get better information in the market.
The company does not want to compromise its success, so relies on data ingestion to eliminate inaccurate data from the data collected and stored in database companies. There are also other uses of data ingestion such as tracking the efficiency of the service, receiving a green signal to move from the device, etc.

Data ingestion pipeline moves streaming data and batch data from the existing database and warehouse to a data lake. Businesses having big data can configure a data ingestion pipeline to structure their data. For an HDFS-based data lake, tools such as Kafka, Hive, or Spark are used for data ingestion.
One major factor you need to understand is how often your data need to be ingested. This is important to count because it will have a major impact on your performance, budget, and complexity of the project.
There are two data ingestion approaches; the first is batch and the second is streaming ingestion.
- Batch Processing: The most commonly used data ingestion approach is batch processing. It is a group-wise collection of data known as a batch that runs periodically and is sent to the destination. The priority of a batch or groups may depend on the logical order or condition applied to a batch. Batched ingestion is usually performed at a small level, but with much higher efficiency.
- Streaming Processing: It is also called real-time processing or streaming. In this process, data is sourced, manipulated, and loaded as soon as it is created or recognized by the data ingestion layer.

With an increase in the number of IoT devices, both the volume and variance of data sources are expanding. So, extracting data by applying traditional data ingestion becomes challenging regarding time and resources. Below are some difficulties faced by data ingestion:
- If the sources of data grow in a different format, then entering the data into the database is one of the biggest challenges for the business. The main difficulties come in prioritizing data and implementing algorithms so that decision-making data gets the highest priority.
- Data security regulation makes data ingestion complex and costly. The validity of data access and usage can be problematic and time-consuming.
- Modification and updating of existing data are the biggest problems in data ingestion.
- Improper data ingestion can lead to unreliable connectivity that upsets communication disturbances and results in data loss.
- Entering a large amount of data on a server can increase the company's overhead cost. This company will have to invest in a high data storage server with high bandwidth.
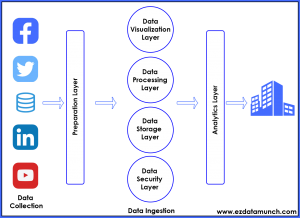
The big data problem can be understood properly by using the architecture pattern of data ingestion. The Layered Architecture is divided into different layers where each layer performs a particular function. This is classified into 6 layers.
- Data Ingestion Layer: Data here is prioritized and categorized, which makes data flow smoothly in further layers.
- Data Collector Layer: Also referred to as the transportation layer because data is transported from the data ingestion layer to the rest of the data pipeline.
- Data processing Layer: The information is routed from the source to the destination.
- Data Storage layer: Data is stored in the database.
- Data Query Level: Active analytics processing takes place. The importance of this layer is gathering the value from the data so that they are made to be more helpful for the next layer.
- Data Visualization layer: Users can find the true value of data.
Data Ingestion has 4 parameters when implementing a new pipeline:
- Data Format: Which format is your data in structured, semi-structured, unstructured? The design of your solution should be for all your formats.
- Data Frequency: Do you need to process in real-time or can you batch load?
- Data Velocity: At what speed does the data flow in your system and what is your deadline to process it?
- Data Size: What is the amount of data that needs to be loaded?
To accomplish data ingestion, the fundamental approach is to use the right tools and equipment that have the ability to support some key principles that are listed below:
- The data pipeline network must be fast and have the ability to meet business traffic. It should be easily customizable and managed.
- The tool should compatible with all the data security standards.
- In the process of data ingestion pipeline, there is a chance of data that can enter from unreliable networks with multiple structures like text, audio, video, XML files, CSV files log files, etc. Data pipelines must have the capability to support unreliable network data sources.
- The tool must have the ability to select the correct data format, this means that when the data variable comes in any format, it should have the ability to convert to a single format that helps to understand the data more quickly.
- It should not have too much of the developer dependency.
- The tools must have the ability to accept both batch and streaming processing. Because sometimes the situation comes when we need to use both processing.

Automate Data Ingestion Process
The data ingestion process technique has to be automated due to the existence of large data sources, which makes it difficult to handle manually. Automation can make the data ingestion process much faster and simpler.
This automated process is necessary where incoming data is automatically converted to a single, standardized format. Automated data ingestion platforms allow organizations to ingest data efficiently and rapidly.
Self-Service Notification
Self-service notification is necessary because data ingestion involves a series of coordinated processes, information is required to inform various applications to publish data to the data lake and monitor their functions.
Choose a Simple Data Ingestion Solution
Large files cause a lot of trouble for data ingestion. There may be potential for application failures when processing large files and loss of valuable data results in the breakdown of enterprise data flows. Therefore, it is better to choose tools that are compatible to tolerate a large file.
Published at DZone with permission of Abhishek Sharma. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments