When Not To Use a Graph Database
This article guides readers on what to consider when using a graph database. You will learn about the benefits, challenges, and what to consider when using databases.
Join the DZone community and get the full member experience.
Join For FreeThe use of graph databases has grown massively in recent years, and they are becoming promising solutions for organizations in any industry. Their increased flexibility makes it easier to leverage relationships and connections in a way that traditional relational databases can't do. But how do you know when to use a graph database? In this article, we explore what to consider if you’re thinking of using a graph database and show how the best approach may be to not use one at all.
What Is a Graph Database?
A graph database is a type of database that uses graph theory as the foundation for its data model. Graph databases consider connectedness as a first-class citizen, making them better suited to represent connected data than more old-school relational databases.
There are two types of graph technologies: RDF/Semantic Web and property graphs. While Semantic Web standards have existed for much longer, property graphs have become the dominant technology, with Cypher the most adopted graph query language.
In essence, the data model in a property graph database consists of the following attributes:
Nodes, edges, properties, and labels:
- Nodes can have properties.
- Nodes can have tags with one or more labels.
- Edges are directed and connect nodes to create structure in the graph.
- Edges can have properties.
Graph databases tend to be used for applications that consume interconnected data. A few common use cases include:
- Recommendation engines
- Semantic search
- Anti-money laundering
- Fraud detection
- 360 customer views
Beyond these applications, graph databases have become promising solutions for organizations that not only have to manage large volumes of data but need to generate business-critical insights. Graph databases promise to be the easiest way to gain such insights by making it easy to understand the relationships and context in our data.
Challenges With Graph Databases
But despite these lofty promises, graph databases are not conquering the world. According to DB-Engines, as of October 2022, they comprised just 1.8% of the database space, a far cry from fulfilling those promises.
There are several reasons that explain the difficulties in the adoption of graph databases. They can be summarized as follows:
Modeling Highly Interconnected Data
Due to a graph database’s high level of expressivity and the associated complexity, modeling data in a graph is not easy. It is akin to modeling knowledge, also known as knowledge engineering—an advanced skill that requires highly specialized engineers. This makes it difficult for graphs to be adopted by the general developer audience, setting a high barrier to entry.
Maintaining Consistency of Data
Another big issue with graph databases is the lack of an enforced schema. Graph databases mostly delegate schema verification to the application layer, whether implicitly or explicitly. This makes it difficult to build applications with complex data where data consistency in the database is crucial. The lack of an explicitly enforced schema in graph databases can become a major hurdle for widespread adoption.
Querying for Data
Interrogating the graph also comes with its own difficulties. Given that an (implicit) data model governs the paths that can be expressed, you have to somehow design your queries in a way that matches that implicit data model. What makes this particularly challenging is that you may not have modeled your data in the most optimal way. Moreover, most graph databases lack important modeling constructs such as nested or n-ary relations, which leads to inconsistencies in modeling decisions. Sometimes you may have defined a relationship as a node, other times as an edge. Your queries may then not always be touching the right data.
A Strongly-Typed Database
Overcoming these kinds of challenges is crucial to help fulfill the promises of graphs.
That’s why we've developed a new type of database: the strongly-typed database, TypeDB.
We built TypeDB (available open-source) to abstract away the low-level implementations of graph databases by offering a higher-level type system that makes it much easier for developers to work with complex data. TypeDB’s type system is based on the following core concepts.
Entity-Relationship Model
TypeDB makes it possible to model data using the well-known Entity-relationship model. Unlike in a graph database, this means we can map any ER diagram directly to how we implement it in TypeQL (TypeDB’s query language), avoiding the need to go through a normalization process. This means that the way we think of a model conceptually as humans is also how we implement it in code in TypeDB.
TypeDB’s model is composed of entity types, relation types, and attribute types, with the introduction of role types. The example below shows how a basic model in TypeQL is written:
define
person sub entity,
owns name,
plays employment:employee;
company sub entity,
owns name,
plays employment:employer;
employment sub relation,
relates employee,
relates employer;
name sub attribute,
value string;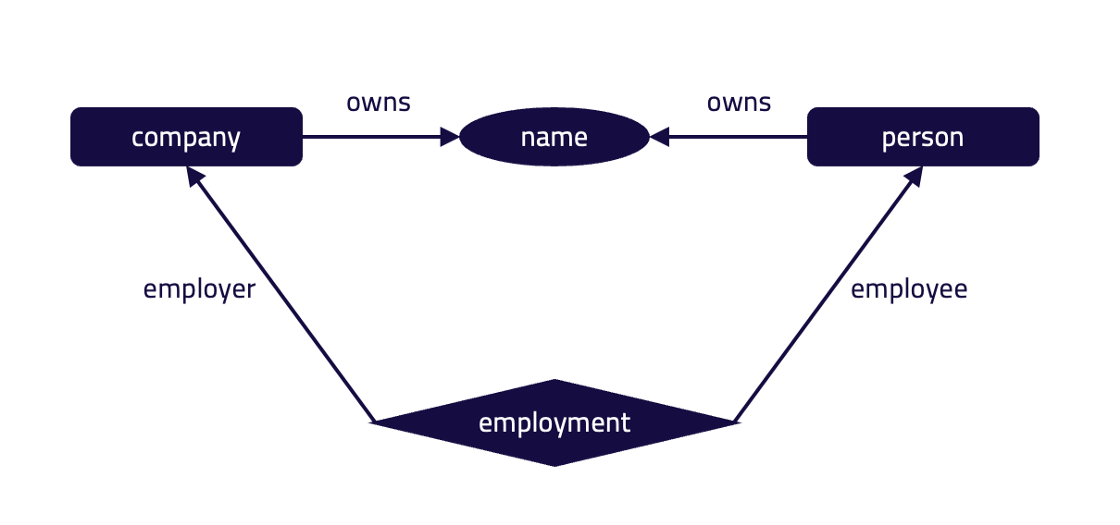
In this nomenclature, squares denote entities; diamonds denote relations; ovals denote attributes. This figure outlines a model with two entities — a person and a company — and both entities own a name attribute. The person plays the role of the employee in the employment relation, while the company plays the role of employer.
Type Hierarchies
TypeDB offers the ability to model type hierarchies out of the box, which is a feature graph databases don’t natively support. Following the principles of an object-oriented type system, TypeDB ensures that all types inherit the behaviors and properties of their super-types. This makes complex data structures reusable and data interpretation richer through polymorphism.
In the example below, a three-level entity person hierarchy is modeled. All of its subtypes will inherit the attributes' first-name and last-name without having to re-declare these one by one:
define
person sub entity,
owns first-name,
owns last-name;
student sub person;
undergrad sub student;
postgrad sub student;
teacher sub person;
supervisor sub teacher;
professor sub teacher;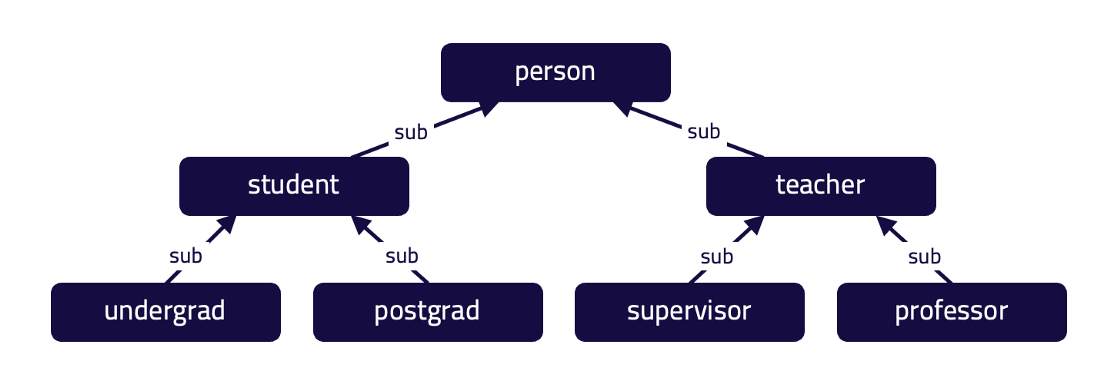
This type hierarchy describes an entity of type person that is sub-typed by the student and teacher types. There are two types of students, undergrads, and postgrads, and there are two types of teachers, supervisors, and professors.
Nested Relations
Relations are concepts that describe the association between two or more things. Sometimes, those things are relations themselves, which means modeling a relation that directly refers to another relation—nested relations. Graph databases don’t allow modeling nested relations, which would require having a binary edge point to a binary edge. The only possible way to achieve this would be through reification, transforming an edge into a node so that another edge can point to it.
TypeDB, however, does allow nested relations, making it possible to model data in its most natural form. In the example below, the relation of type marriage is assigned to the variable $mar, which is then used to connect it to a city through the relation located:
match
$alice isa person, has name "Alice";
$bob isa person, has name "Bob";
$mar ($alice, $bob) isa marriage;
$city isa city;
($mar, $city) isa location;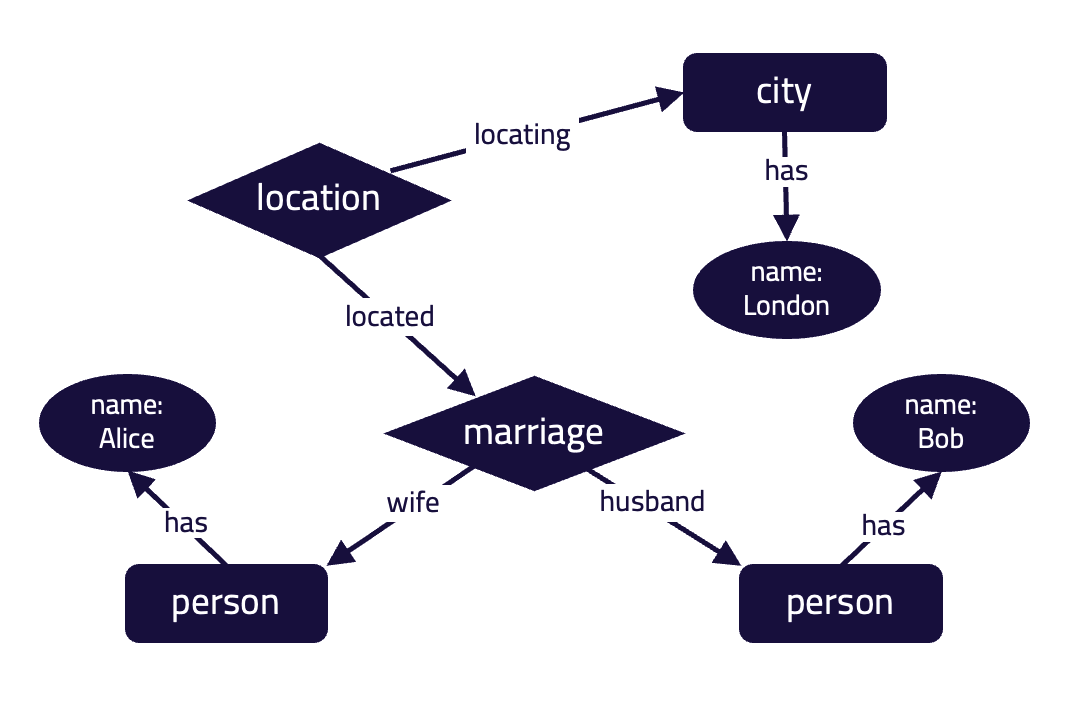
In this figure, the person “Alice” plays the role of wife, and the person “Bob” plays the role of husband in a marriage relation. Marriage is a nested relation, as it also plays the role of located in a location relation, where the city “London” plays the role of locating in that same relation.
N-ary Relations
In the real world, relations aren’t just binary connections between two things. That’s why it’s often necessary to capture three or more things related to each other at once. Representing them as separate binary relationships would lead to a loss of information, which is what happens in graph databases. TypeDB, on the other hand, can naturally represent an arbitrary number of things as one relation, for example, without needing to reify the model.
In this example, the n-ary relation cast connects three different entities: a person entity, a character entity, and a movie entity:
match
$person isa person, has name "Leonardo";
$character isa character, has name "Jack";
$movie isa movie, has name $movie-name;
(actor: $person, character: $character, movie: $movie) isa cast;
get $movie-name;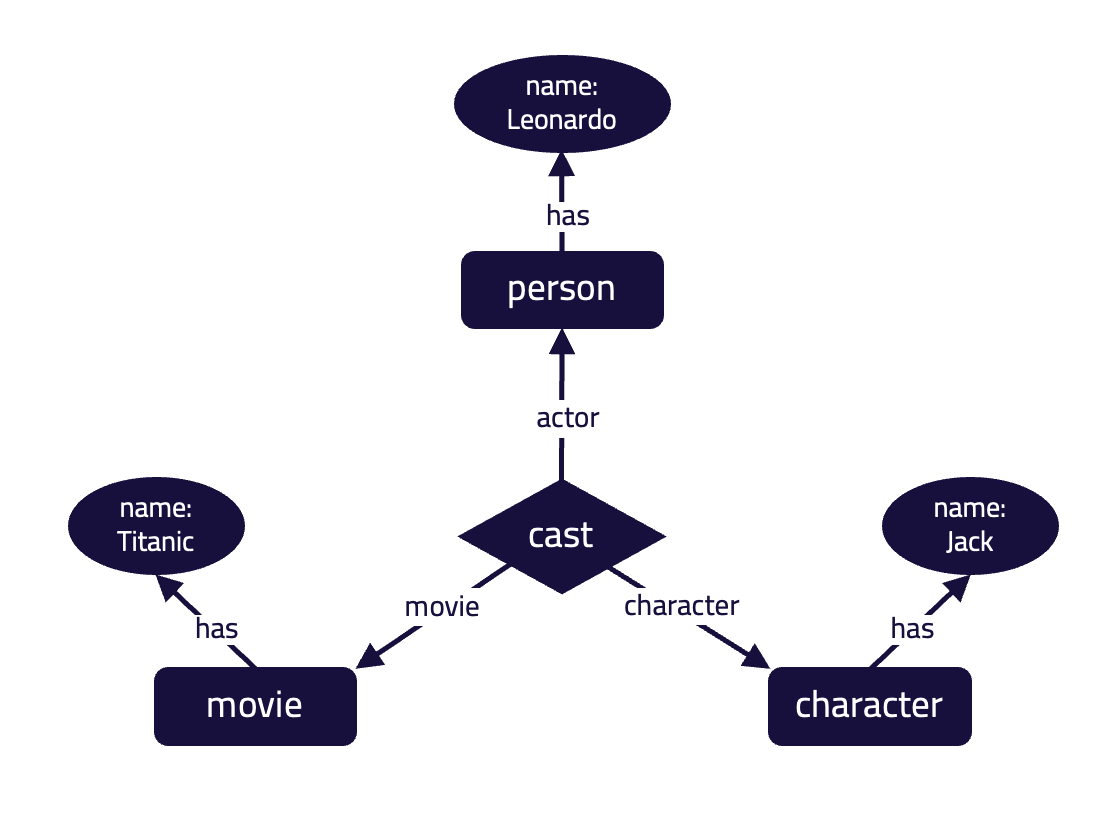
This is an example of an n-ary relation, specifically a ternary relation, of type cast. This relation relates to three entities: the movie “Titanic” plays the role of movie, the person “Leonardo” plays the role of actor, and the character “Jack” plays the role of character in this cast relation.
Safety
Unlike graph databases, TypeDB provides a way to describe the logical structures of your data, allowing TypeDB to validate that your code inserts and queries data correctly. Query validation goes beyond static type-checking and includes logical validation of meaningless queries. With strict type-checking errors, you have a dataset that you can trust.
In the example insert query below, the relation between Charlie and DataCo would be rejected, as a person cannot marry a company (assuming the schema follows the real world).
insert
$charlie isa person, has name "Charlie";
$dataCo isa company, has name "DataCo";
(husband: $charlie, wife: $dataCo) isa marriage; # invalid relation
commit>>
ERROR: invalid data detected during type validationInference
Finally, TypeDB offers a built-in inference engine, which enables TypeDB to derive new insights, and provides full explainability of those insights. Property graphs, on the other hand, don’t offer native inference capabilities.
Inferences in TypeDB are based on rules that are defined in your schema. During query runtime, if a certain logical form in your dataset is satisfied (as defined in a rule), the system will derive new conclusions. Like functions in programming, rules can chain onto one another, creating abstractions of behavior at the data level.
With the rule below, TypeDB would be able to infer that a city is located in a continent, even though no explicit relationship exists between the two.
define
rule transitive-location:
when {
(located: $city, locating: $country) isa location;
(located: $country, locating: $continent) isa location;
} then {
(located: $city, locating: $continent) isa location;
};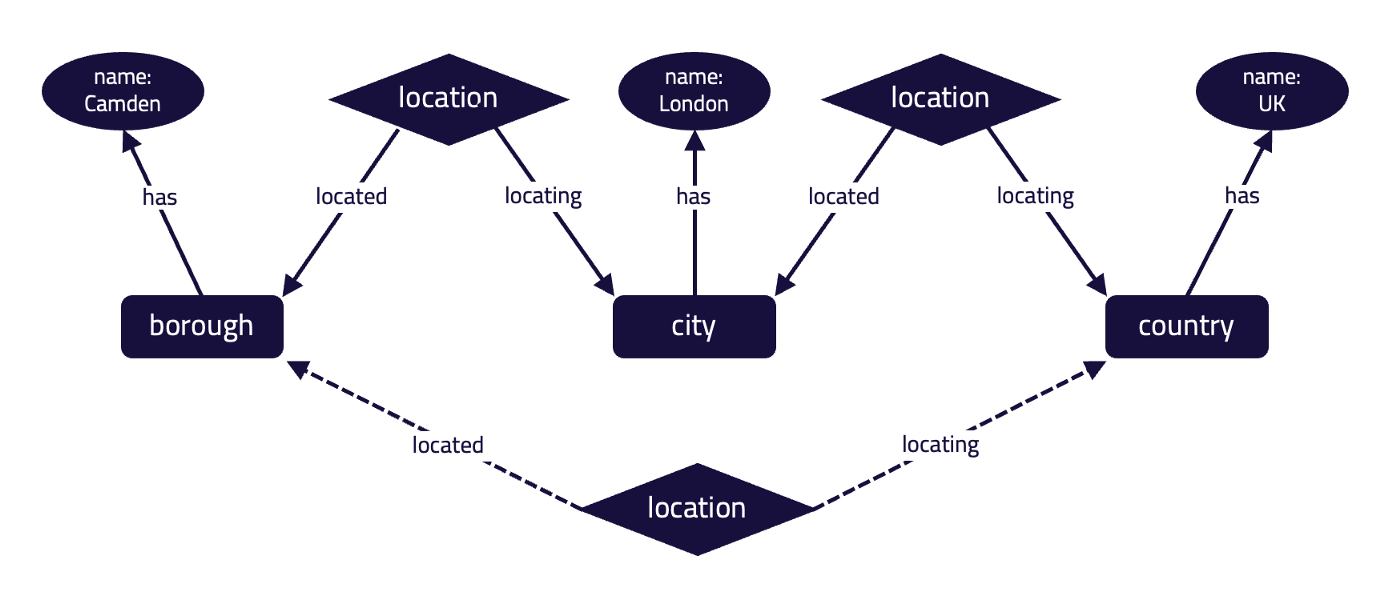
Using automated reasoning, TypeDB can infer a relationship (dotted line) between the borough “Camden” and the country “UK,” even though they’re not directly connected.
Conclusion
When do we use a graph database, then? Graphs were meant for applications that rely on complex and interconnected data. However, as we’ve seen, their lack of widespread adoption highlights the key failures and challenges of existing graph database solutions. To overcome those challenges and fulfill the original promise of graph databases, we built TypeDB.
You can find TypeDB on Github here.
Published at DZone with permission of Tomás Sabat. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments