When Should We Move to Microservices?
Avoiding the small monolith antipattern. At what scale do microservices make sense? Avoid a solution worse than the problem, and understand the tradeoffs.
Join the DZone community and get the full member experience.
Join For FreeLast month I wrote about modular monoliths and the value of modern monolithic architecture. One of the more interesting discussions that came out of that article (and video) is the inverse discussion: when is it right to still pick microservices?
Like any design choice, the answer is subjective and depends on many things. But there are still general rules of thumb and global metrics we can use. Before we get into these problems, we need to understand what it means to have a microservice architecture. Then we can gauge the benefit and price of having such an architecture.
Small Monoliths
A common misconception is that microservices are simply broken down monoliths. This isn’t the case. I’ve talked to quite a few people who still hold that notion, to be fair they might have a point. This is how AWS defines microservices:
Microservices are an architectural and organizational approach to software development where software is composed of small independent services that communicate over well-defined APIs. These services are owned by small, self-contained teams.
Microservices architectures make applications easier to scale and faster to develop, enabling innovation and accelerating time-to-market for new features.
Smaller monoliths might fit the definition, but they don’t if you read between the lines. The words “independent,” and “easier to scale” hint at the problem. The problem (and advantage) of a monolith is a single point of failure. By having one service we can usually find problems more easily. The architecture is much simpler.
If we break this service down into smaller pieces, we essentially create distributed points of failure. If one piece along the chain fails, the entire architecture breaks down. That isn’t independent, and it isn’t easier to scale. Microservices are NOT small monoliths and breaking down the monolith isn’t only about working with smaller projects. It’s about shifting the way we work.
What Makes a Microservice?
A good microservice needs to follow these principles for robustness and scale:
- Divided by business function: this is a logical division. A microservice is a standalone “product” that provides a complete package. This means that the team responsible for the microservice can make all the changes required for the business without dependencies.
- Automation through CI/CD: without continuous delivery, the cost of updating would eliminate every benefit of microservices.
- Independent deployment: is implied, since a commit on one microservice will only trigger the CD of that specific service. We can accomplish this through Kubernetes and Infrastructure as Code (IaC) solutions.
- Encapsulation: it should hide the underlying implementation details. A service acts as a standalone product that publishes an API for other products. We commonly accomplished this via REST interfaces but also messaging middleware. This is further enhanced with API Gateways.
- Decentralized with no single point of failure: otherwise, we would distribute failure.
- Failures should be isolated: without this, a single service going down could create a domino effect. Circuit breakers are probably the most important tools for isolating failures. To satisfy this dependency, every microservice handles its own data. This means many databases, which can be challenging at times.
- Observable: this is required to deal with failures on a scale. Without proper observability, we are effectively blind as the various teams can deploy automatically.
This is all good and well, but what does that mean in practical terms?
Most of what it means is that we need to make several big changes to the way we handle some big ideas. We need to move more of the complexity to the DevOps team. We need to handle cross-microservice transactional state differently. This is one of the hardest concepts to grasp when dealing with microservices.
In an ideal world, all our operations will be simple and contained in a small microservice. The service mesh framework surrounding our microservices will handle all the global complexities and manage our individual services for us. But that isn’t the real world. In reality, our microservices might have a transactional state that carries between the services. External services might fail, and, for that, we need to take some unique approaches.
Reliance on the DevOps Team
If your company doesn’t have good DevOps and Platform Engineering teams, microservices aren’t an option. Instead of deploying one application, we might deploy hundreds because of migration. While the individual deployments are simple and automated, you will still throw a lot of work at operations.
When something doesn’t work or connect. When a new service needs to integrate or the service configuration should be adopted. Operations carry a greater burden when working with microservices. This requires great communication and collaboration. It also means the team managing a specific service needs to take some of the OPS burdens back. That isn’t a simple task.
As developers, we need to know many of the tools used to tie our separate services back to a single unified service:
- Service mesh: lets us combine separate services and effectively acts as a load balancer between them. It also provides security, authorization, traffic control, and much more.
- API gateways: should be used instead of invoking the API directly. This can be awkward at times but it’s often essential to avoid costs, prevent rate limiting, and more.
- Feature flags and secrets: are useful in a monolith as well. But they’re impossible to manage at a microservice scale without dedicated tools.
- Circuit breaking: lets us kill a broken web service connection and recover gracefully. Without this, a single broken service can bring down the entire system.
- Identity management must be separate: you can’t get away with an authentication table in the database when dealing with a microservice environment.
I’ll skip orchestration, CI/CD, etc. but they, too, need to be adapted for every service that comes out. Some of those tools are opaque to developers but we need the help of DevOps in all the phases.
Saga Pattern
Stateless services would be ideal, carrying a state makes everything far more complex. If we stored the state in the client, we need to send it back and forth all the time. If it is on the server, we would need to either fetch it constantly, cache it, or save it locally and then all interaction would be performed against the current system. That eliminates the scalability of the system.
A typical microservice will store in its own database and work with local data. A service that needs remote information will typically cache some data to avoid round-trips to the other service. This is one of the biggest reasons microservices can scale. In a monolith, the database should become the bottleneck of the application, which means the monolith is efficient and limited by the speed we can store and retrieve the data. This has two major drawbacks:
- Size: the more data we have; the larger the database and performance impacts all users at once. Imagine querying an SQL table of every purchase ever made on Amazon just to find your specific purchase.
- Domain: databases have different use cases. Some databases are optimized for consistency, write speed, read speed, time data, spatial data, and more. A microservice that tracks user information would probably use a time series database, which is optimized for time-related information, whereas a purchase service will focus on a traditional conservative ACID database.
Note: A monolith can use more than one database. That can work perfectly well and can be very useful. But it’s the exception. Not the rule.
The saga pattern works by using compensating transactions to undo the effects of a saga if it fails. When a saga fails, the compensating transaction is executed to undo the changes made by the previous transaction. This allows the system to recover from failures and maintain a consistent state. We can accomplish this with tools, such as Apache Camel, but this is non-trivial and requires far more involvement than a typical transaction in a modern system. That means that for every major cross-service operation you would need to do the equivalent undo operation that will restore the state back. That is non-trivial. There are several tools for saga orchestration but this is a big subject that is beyond the scope of this article, still I will explain it in broad terms.
What’s important to understand about saga is that it avoids the classic ACID database principles and focuses on “eventual consistency.” That means operations would bring the database to a consistent state at some point. That is a very difficult process. Imagine debugging a problem that only occurs when the system is in an inconsistent state.
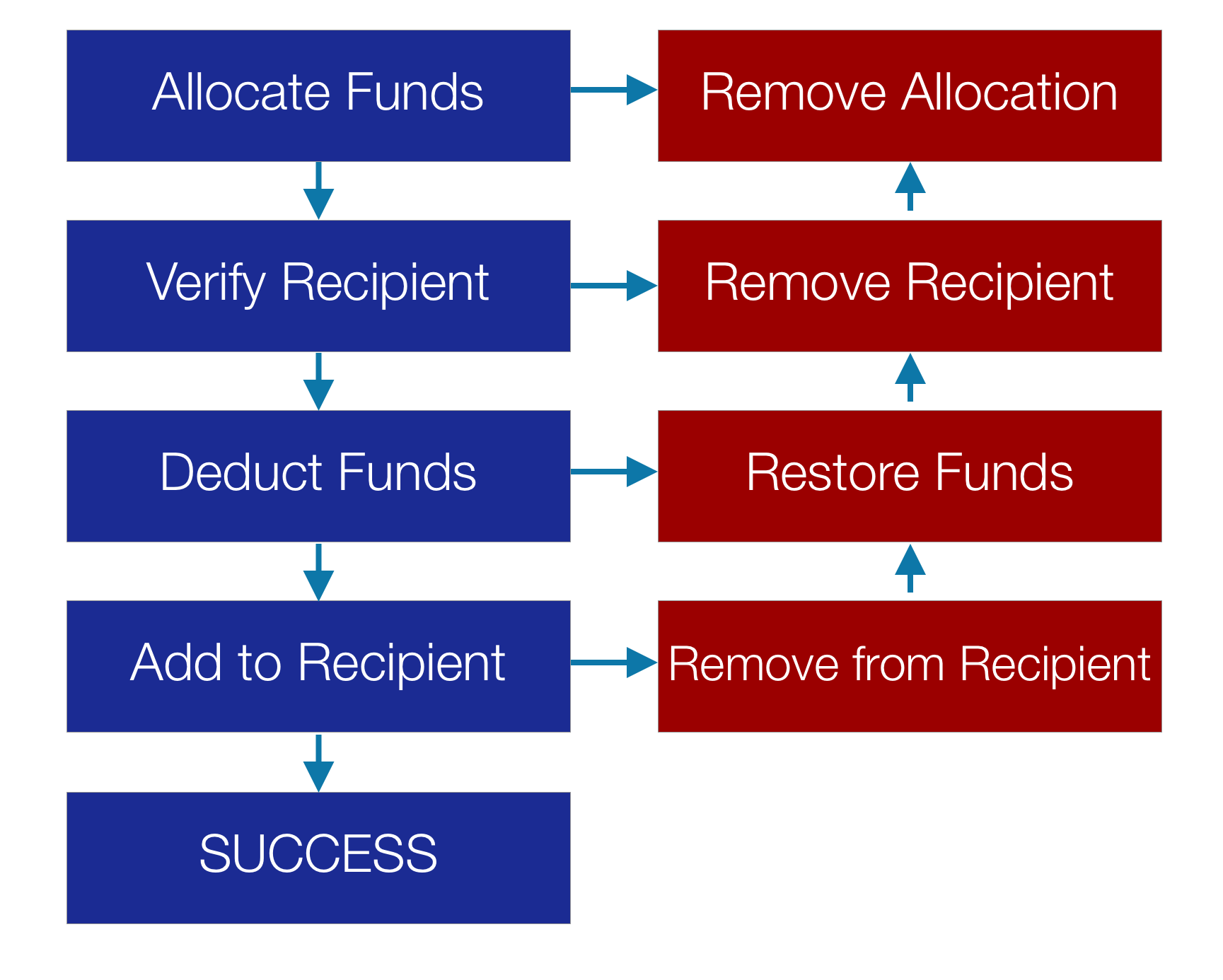
The following image demonstrated the idea in broad terms. Let’s say we have a money transfer process:
- For the money transfer, we need to first allocate funds.
- We then verify the recipient is valid and exists.
- Next, we need to deduct the funds from our account.
Finally, we need to add the money to the recipient’s account.
That is a successful transaction. With a regular database, this would be one transaction and we can see this in the blue column on the left in the image below. But if something goes wrong we need to run the reverse process:
- If a failure occurs when allocating funds, we need to remove the allocation. We need to create a separate block of code that does the inverse operation of the allocation.
- If verifying a recipient fails, we need to remove that recipient. Then we need to also remove the allocation.
- If deducting the funds fails, we need to restore the funds, remove the recipient, and remove the allocation.
- Finally, if adding the funds to the recipient fails, we need to run all the undo operations!
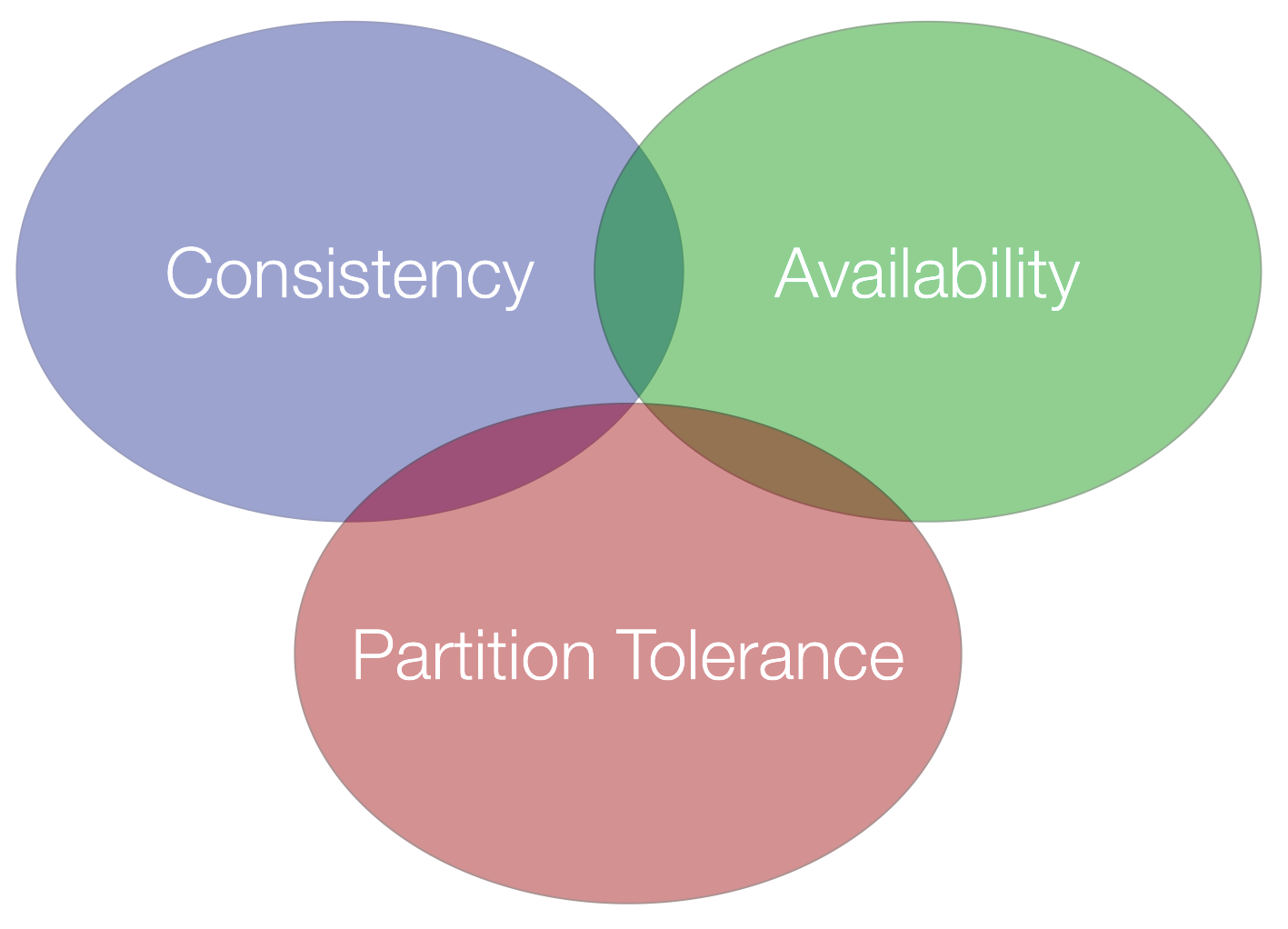
Another problem in saga is illustrated in the CAP theorem. CAP stands for Consistency, Availability, and Partition Tolerance. The problem is we need to pick any two… Don’t get me wrong, you might have all three. But, in a case of a failure, you can only guarantee two.
Availability means that requests receive responses. But there’s no guarantee they contain the most recent writes.
Consistency means that every read receives the most recent write on an error.
Tolerance means that everything will keep working even if many messages get dropped along the way.
This differs greatly from our historic approach to failure with transactions.
Should We Pick Microservices?
Hopefully, you understand how hard it is to deploy microservices properly. We need to make some big compromises. This new way isn’t necessarily better, in some regards, it is worse. But the proponents of microservices still have a point, we can gain a lot through microservices and should focus on those benefits too.
We mentioned the first requirement upfront: DevOps. Having a good DevOps team is a prerequisite to considering microservices. I saw teams trying to hack their way through this without an OPS team and they ended up spending more time on operational complexity than writing code. It wasn’t worth the effort.
The biggest benefit of microservices is to the team. That is why having a stable team and scope is crucial. Splitting teams into vertical teams that work independently is a tremendous benefit. The most modular monolith in the world can’t compete with that. When we have hundreds of developers following the git commits alone and tracking the code changes in scale becomes untenable. The value of microservices is only realized in a large team. This sounds reasonable enough, but in a startup environment, things shift suddenly. A colleague of mine works for a startup that employed dozens of developers. They decided to follow a microservice architecture and built a lot of them. Then came the downsizing and maintaining dozens of services in multiple languages became a problem.
Splitting a monolith is hard but doable. Unifying microservices to a monolith is probably harder, I’m unaware of anyone who seriously tried to do that but would be curious to hear stories.
Not One Size
To move to a microservice architecture, we need a bit of a mind shift. A good example is in the databases and a user tracking microservice. In a monolith, we would write the data to a table and move on with our work. But this is problematic.
As data scales, this user tracking table can end up containing a great deal of data that is hard to analyze in real-time without impacting the rest of the operating system. With a microservice, we can offer several advantages:
- The interface to the microservice can use messaging, which means the cost to send tracking information will be minimal.
- Tracking data can use a Time Series database, which would be more efficient for this use case.
- We can stream the data and process it asynchronously to derive additional value from that data.
There are complexities, data will no longer be localized. So, if we send tracking data asynchronously, we need to send everything necessary as the tracking service won’t be able to go back to the original service to get additional meta-data. But it has a locality advantage, if regulation changes about tracking storage, there’s a single place where this is stored.
Dynamic Control and Rollout
Did you ever push a button to a release that broke production?
I did, more than once (way too many times). That’s a terrible feeling. Microservices can still fail in production and can still fail catastrophically, but, often, their failure is more localized. It is also easier to roll them out to a specific subset of the system (Canary) and verify. These are all policies that can be controlled in depth by the people who actually have their fingers on the user’s pulse: OPS.
Observability for microservices is essential, expensive, but also more powerful. Since everything occurs at the network layer, it is all exposed to the observability tools. An SRE, or DevOps, can understand a failure with greater detail. This comes at the expense of the developer who might need to face increased complexity and limited tooling.
Applications can become too big to fail. Even with modularity, some of the largest monoliths around have so much code it takes hours to run through a full CI/CD cycle. Then, if the deployment fails, reverting to the last good version might also take a while.
Segmentation
Back in the day, we used to divide teams based on layers. Client, Server, DB, etc. This made sense since each of those required a unique set of skills. Today, vertical teams make more sense, but we still have specialties.
Typically, a mobile developer wouldn’t work on the backend. But let’s say we have a mobile team that wants to work with GraphQL instead of REST. With a monolith, we would either tell them to “live with it” or we would have to do the work. With microservices, we can create a simple service for them with very little code. A simple facade to the core services. We won’t need to worry about a mobile team writing server code since this would be relatively isolated. We can do the same for every client layer, this makes it easier to integrate a team vertically.
Too Big
It is hard to put the finger on a size that makes a monolith impractical but here’s what you should ask yourself:
How Many Teams Do We Have or Want?
If you have a couple of teams, then a monolith is probably great. If you have a dozen teams, then you might face a problem there.
Measure Pull Request and Issue Resolution Times
As a project grows, your pull requests will spend more time waiting to merge and issues will take longer to resolve. This is inevitable as complexity tends to grow in the project. Notice that a new project will have larger features and that might sway the results once you account for that in the project stats the decrease in productivity should be measurable.
Notice that this is one metric. In many cases, it can indicate other things such as the need to optimize the test pipeline, the review process, modularity, etc.
Do We Have Experts Who Know the Code?
At some point, a huge project becomes so big that the experts start losing track of the details. This becomes a problem when bugs become untenable and there’s no authoritative figure that can make a decision without consultation.
Are You Comfortable Spending Money?
Microservices will cost more. There’s no way around that. There are special cases where we can tune scale, but, ultimately, observability and management costs would remove any potential cost savings. Since personnel costs usually exceed the costs of cloud hosting, the total might still play in your favor as those costs might decrease if the scale is big enough.
Trade-Offs
The trade-offs of monolith vs. microservice are illustrated nicely in the following radar chart. Notice that this chart was designed with a large project in mind. The smaller the project, the better the picture is for the monolith.
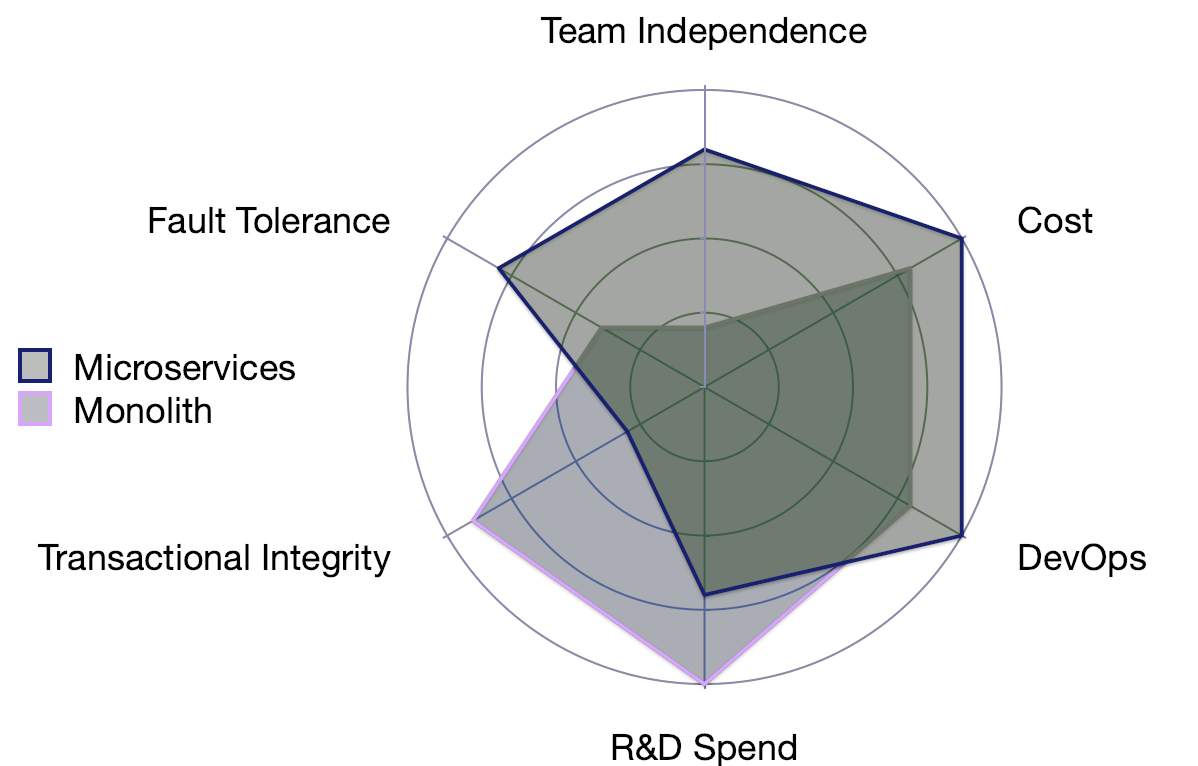
Notice that microservices deliver a benefit in larger projects in fault tolerance and team independence. But they pay a price in cost. They can reduce R and D spend but they mostly shift it to DevOps, so that isn’t a major benefit.
Final Word
The complexity of microservices is immense and sometimes ignored by the implementing teams. Developers use microservices as a cudgel to throw away parts of the system they don’t want to maintain, instead of building a sustainable, scalable architecture worthy of replacing a monolith.
I firmly believe that projects should start off with a monolith. Microservices are an optimization for scaling a team and optimizing prematurely is the root of all evil. The question is, when is the right time to do such an optimization?
There are some metrics we can use to make that decision easier. Ultimately, the change isn’t just splitting a monolith. It means rethinking transactions and core concepts. By starting with a monolith, we have a blueprint we can use to align our new implementation as it strengthens.
Published at DZone with permission of Shai Almog, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments