Implementing Write-Through Cache for Real-Time Data Processing: A Scalable Approach
Learn how a write-through local cache boosts performance and consistency in high-volume data streams while reducing database load.
Join the DZone community and get the full member experience.
Join For FreeReal-time data processing systems often struggle with balancing performance and data consistency when handling high volumes of transactions. This article explores how a write-through local cache can optimize performance.
Introduction to Write-Through Caches
A write-through cache is a caching strategy where data is written to both the cache and the backing store simultaneously. This approach ensures that the cache always contains the most recent data while maintaining consistency with the underlying data store.
In distributed systems processing event streams, write-through caches can significantly reduce latency and database load by localizing data access patterns. Unlike write-back caching (which delays updates to the backing store) or read-through caching (which only populates on read operations), write-through caching provides stronger consistency guarantees while still offering performance benefits.
The Entity-Signal Pattern
Before diving into implementation details, let's understand the data model we're working with:
- EntityIDs: Unique identifiers for items in the system (e.g., users, devices)
- Signals: Attributes or events associated with these entities
- Signal History: A collection of signals for each entity that may need to be accessed frequently
This pattern is common in analytics systems, fraud detection platforms, recommendation engines, and IoT applications, where entity behavior needs to be tracked over time.
Architecture Overview
Our write-through cache implementation focuses on optimizing stream processing workloads where:
- Each processing node handles specific entityIDs (partitioned by hash)
- Signal history for these entities is frequently accessed
- New signals continually arrive via stream processing (e.g., Kinesis)
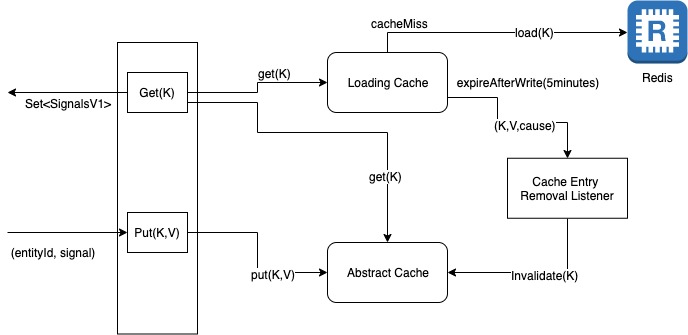
The (local) cache serves three primary purposes:
- Periodically load signals for entityIDs from Redis
- Store new signals arriving
- Always provide complete and current signal data for any cached entity
Implementation Details
The implementation consists of two coordinated components:
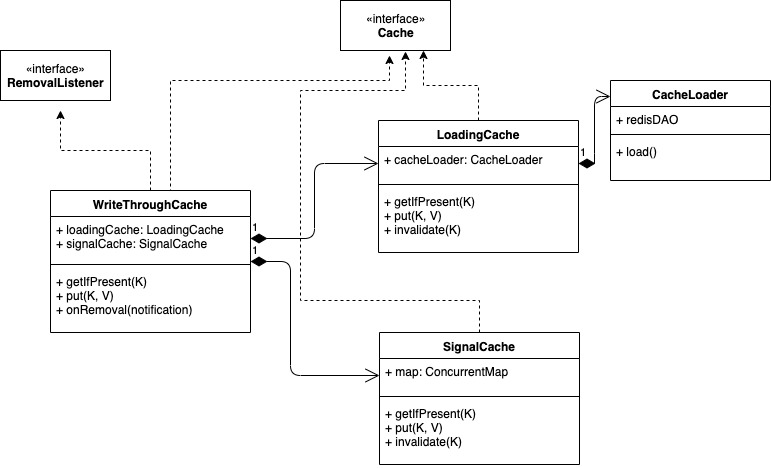
1. Loading Cache
The loading cache is responsible for periodically refreshing entity data from the backend Redis store:
private final LoadingCache<String, Set<Signal>> loadingCache;
// In constructor
this.loadingCache = CacheBuilder.newBuilder()
.maximumSize(LOADING_CACHE_MAX_SIZE)
.expireAfterWrite(LOADING_CACHE_TIMEOUT, TimeUnit.MINUTES)
.removalListener(this)
.recordStats()
.build(new SignalCacheLoader(
redisDAO,
secretTokenizer,
weblabClient,
metricsManager));Key configurations include:
- Maximum size: Prevents unbounded memory growth (
LOADING_CACHE_MAX_SIZE = 1000) - Expire-after-write: Ensures data is refreshed periodically (
LOADING_CACHE_TIMEOUT = 5minutes) - Removal listener: Notifies when entries are evicted
2. Signal Cache
The signal cache stores incoming signals between refresh cycles:
// Starts with initial capacity of 100 and grows till the size limit of loading cache
// As loading cache expires its entries, this class acts as a removal listener and removes the entry for Signal
// cache as well.When new signals need to be stored:
/**
* Index signals to the entityId.
* @param key entityId.
* @param value Set of signals.
*/
@Override
public void put(String key, Set<Signal> value) {
if (key != null && value != null) {
// Save the signal in local cache
localCache.put(key, Lists.newArrayList(value));
}
}When requesting signals for an entity:
@Override
public Set<Signal> getIfPresent(Object key) {
if (key != null && (key instanceof String)) {
final Set<Signal> signals = loadingCache.get((String) key);
if (log.isDebugEnabled()) {
log.debug("Number of signals retrieved from redis cache loader for [entity: {}] is {}",
getResult((String) key), signals.size());
}
// Fetch any recent signals for entity which came in after redis load()
final List<Signal> inMemorySignals = (List<Signal>) localCache.getIfPresent(key);
if (log.isDebugEnabled()) {
log.debug("Number of signals retrieved from local in-memory cache for [entity: {}] is {}",
getResult((String) key), inMemorySignals.size());
}
signals.addAll(inMemorySignals);
return new HashSet<>(signals);
}
return Collections.emptySet();
}
Memory Management Strategy
The cache implementation employs a coordinated memory management strategy:
- Loading cache: Configured with maximum size and expiry time. When entries expire or are evicted due to size constraints, removal notifications are triggered.
- Signal cache: It starts with a defined initial capacity and grows as needed. Its size is effectively controlled by the loading cache through the removal notification mechanism.
/**
* When loadingCache expires its entry, this listener removes the key from
* localCache as well.
* @param removalNotification
*/
@Override
public void onRemoval(RemovalNotification removalNotification) {
if (log.isDebugEnabled()) {
log.debug("Invalidating local cache for [entity: {}]",
secretTokenizer.getHashedResult((String) removalNotification.getKey()));
}
localCache.invalidate(removalNotification.getKey());
}This coordinated approach ensures both caches stay in sync and allows the JVM to reclaim memory when entries are no longer needed.
Business Benefits
1. Reduced Transaction Costs
By localizing data access, this caching strategy dramatically reduces Redis operations:
- Without cache: Each incoming signal requires a Redis read and write.
- With cache: Redis reads occur once per expiry interval per entity.
- Cost reduction: For high-volume systems processing millions of events, this can translate to a 95%+ reduction in Redis operations.
2. Improved Latency
Stream processing latency is significantly reduced:
- Without cache: 10-20ms per signal (Redis round-trip)
- With cache: Sub-millisecond response for cached entities
- Benefit: Lower processing latency leads to more responsive systems
3. Enhanced Resilience
The write-through cache provides resilience against temporary Redis failures:
- Processing can continue with cached data during short outages
- Writes can be queued and flushed when connectivity is restored
- System availability increases while dependency on Redis availability decreases
4. Optimized Cost Structure
Beyond direct transaction cost reduction:
- Infrastructure savings: Reduced Redis cluster size needed for the same workload
- Scaling efficiency: More efficient processing means fewer nodes needed for the same throughput
- Operational simplicity: Less complex Redis scaling and management
Considerations and Best Practices
While implementing this pattern, keep these guidelines in mind:
- Cache size tuning: Set the maximum cache size based on entity cardinality and available memory.
- Expiry intervals: Balance freshness needs against Redis load.
- Monitoring: Implement cache hit/miss metrics to verify efficiency.
- Consistency controls: Consider adding version stamps for conflict resolution.
- Warm-up strategy: Pre-populate caches for critical entities during startup.
Conclusion
A well-implemented write-through cache can transform the performance and cost profile of entity-based stream processing systems. By intelligently caching entity signals at the processing node level and coordinating with a backing Redis store, organizations can achieve both high performance and data consistency while significantly reducing infrastructure costs.
This pattern is particularly valuable for high-throughput systems where entities exhibit locality (the same entities appear repeatedly in the stream) and where signal history needs to be maintained and frequently accessed during processing.
Whether you're building a fraud detection system, user behavior analytics, or IoT data processor, consider implementing this write-through caching pattern to boost performance while keeping your database costs under control.
Opinions expressed by DZone contributors are their own.
Comments