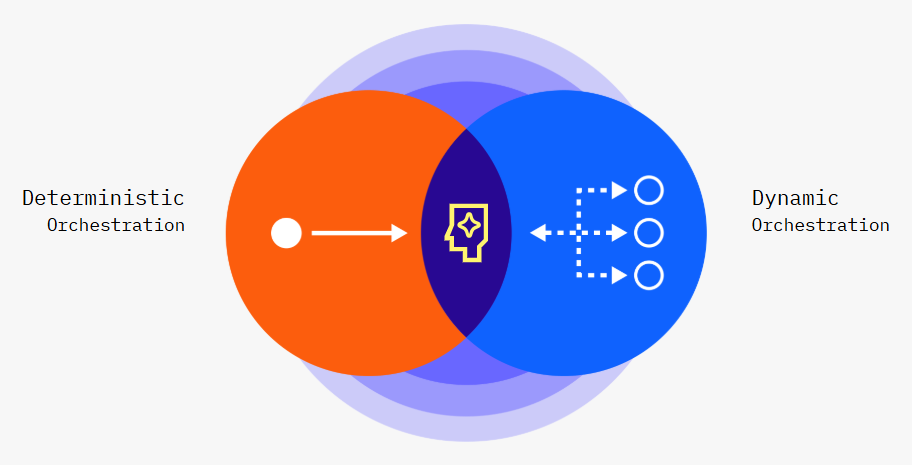
This section explores AI automation's fundamental building blocks, ranging from the aspects of AI training and foundation models to the critical considerations of security, compliance, architecture, and the invaluable role that AI coding assistants play.
AI Model Training
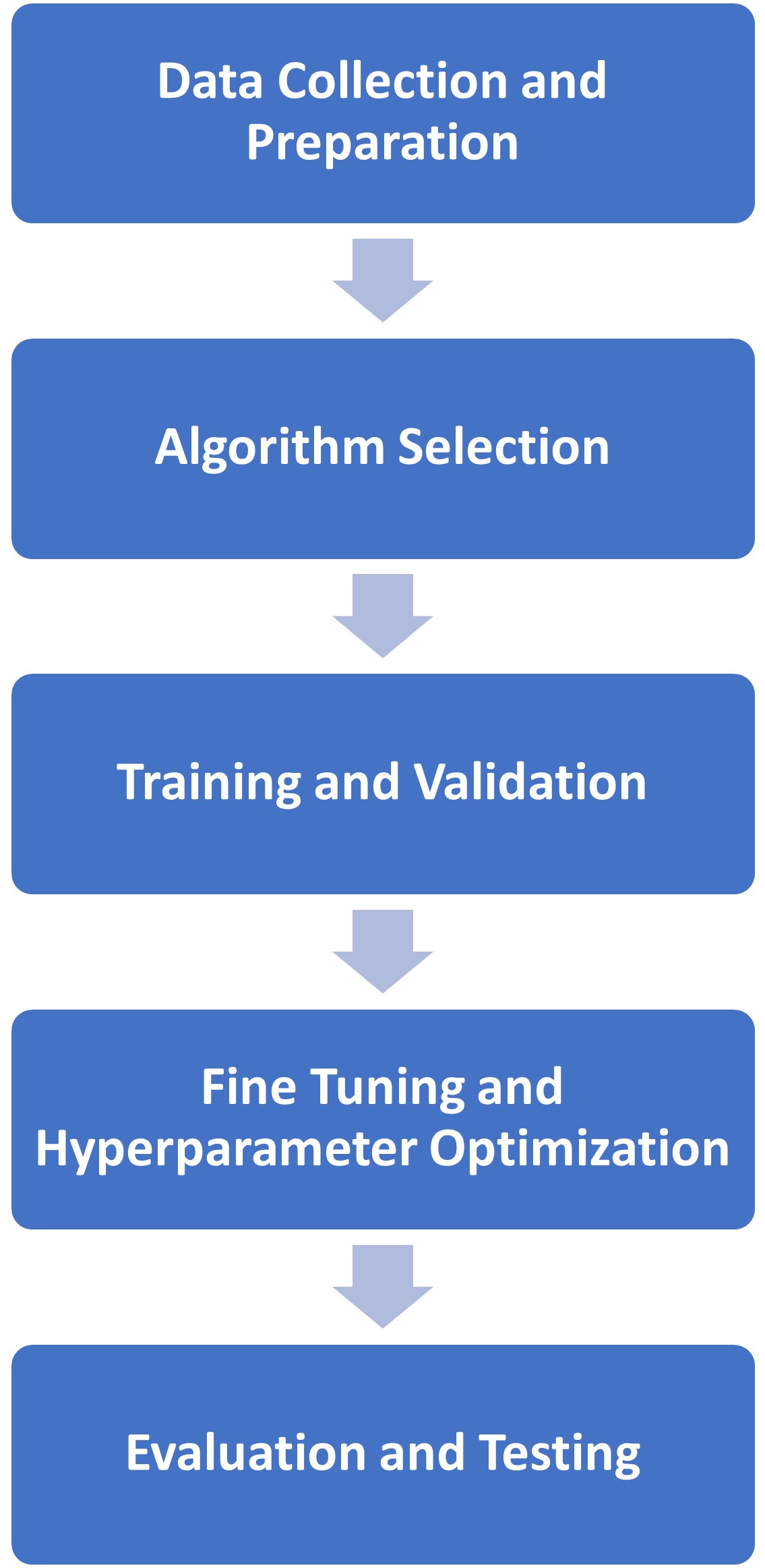
The AI model training process encompasses several crucial steps:
- Data is systematically gathered, cleansed, and curated, ensuring its quality and relevance.
- Algorithms are carefully selected based on factors like accuracy and complexity, shaping how the model processes data.
- The training and validation phases follow, allowing the model to learn patterns iteratively and undergo evaluations to enhance accuracy.
For example, fine-tuning and hyperparameter optimization refine the model's performance, specializing it for specific tasks. Evaluation and testing involve exposing the model to separate datasets to assess accuracy, identifying strengths and weaknesses for necessary adjustments. This comprehensive training process ensures that AI models continuously learn, adapt, and excel in various applications.
Figure 2: AI model training process
Importance of Training Data Duality and Diversity
AI training data serves as the foundation for teaching ML algorithms to recognize patterns and make predictions. Whether it's images, audio, text, or structured data, each example in the training dataset is associated with an output label that guides the algorithm's learning process. The accuracy and generalization ability of ML models heavily depend on the quality and diversity of the training data.
Consider an AI system trained to recognize facial expressions, but only on a dataset featuring a specific demographic group. Such a model may struggle to accurately interpret expressions from other demographics, leading to biased or incomplete predictions. To illustrate, imagine a scenario where a healthcare AI system trained primarily on data from a certain ethnic group might struggle to provide accurate diagnostic predictions for individuals from different ethnic backgrounds. Hence, the careful selection and preprocessing of training data to ensure representation across diverse demographics are essential to building robust and unbiased AI models.
The risk of AI bias, which can result in unfair or discriminatory outcomes, can be mitigated by incorporating diverse and representative training data and employing unbiased labeling processes. This underscores the importance of meticulous curation and validation of training datasets to foster fairness, accuracy, and inclusivity in AI applications.
Foundation Models
The emergence of foundation models (FMs) has reshaped the AI field. Unlike traditional AI systems that are specialized tools for specific applications, FMs (also known as base models) have gained prominence due to two notable trends in machine learning:
- A select number of deep learning architectures have demonstrated the ability to achieve diverse results across a wide range of tasks.
- There is recognition that AI models, during their training, can give rise to new and unforeseen concepts beyond their original intended purposes.
FMs are pre-trained with a general contextual understanding of patterns, structures, and representations, creating a baseline of knowledge that can be fine-tuned for domain-specific tasks across various industries. These models leverage transfer learning, allowing them to apply knowledge from one situation to another, build upon it, and scale, enabled by graphics processing units (GPUs) for efficient parallel processing.
Deep learning (particularly in the form of transformers) has played a significant role in the development of FMs, enhancing their capabilities in NLP, computer vision, and audio processing. Transformers (as a type of artificial neural network) enable FMs to capture contextual relationships and dependencies, contributing to their effectiveness in understanding and processing complex data sequences.
Figure 3: Foundation model

Benefits of using FMs include:
- Accessibility – FMs offer accessible and sophisticated AI automation that can help bridge resource gaps. Models are built on data not typically available to most organizations, offering an advanced starting point for AI initiatives.
- Enhanced model performance – FMs establish a baseline accuracy that surpasses what organizations might achieve independently, reducing the months or years of effort required. This inherent accuracy facilitates subsequent fine-tuning efforts to achieve tailored results in AI automation apps.
- Efficient time to value – With pre-training, FMs significantly reduce the time to value by providing a baseline. These models can then be fine-tuned for specific outcomes, accelerating the deployment of bespoke AI solutions.
- Use of limited talent – FMs enable organizations to leverage AI/ML without extensive investments in data science resources, allowing companies to make effective use of advanced AI capabilities.
- Cost-effective expense management – FMs minimize the need for expensive hardware during initial training. While there are costs associated with serving and fine-tuning the final model, they are significantly lower compared to the expenses incurred in training the foundation model itself.
Challenges with using FMs include:
- Resource-intensive development – Developing FMs demands significant resources, particularly in the initial training phase, requiring vast amounts of generic data, tens of thousands of GPUs, and a skilled team of ML engineers and data scientists.
- Interpretability concerns – The "black-box" nature of FMs, where the neural network's workings are not transparent, makes them difficult to interpret. The inability to explain model outputs can have harmful consequences in high-stakes fields (e.g., healthcare, finance), a concern that also extends to any neural-network-based model.
- Privacy and security risks – FMs require access to large amounts of data, and potentially sensitive information (e.g., customer and proprietary business data). When deployed or accessed by third-party providers, organizations need to manage privacy and security risks carefully in AI automation scenarios.
- Accuracy and bias mitigation – If models are trained on statistically biased data, they may produce flawed outputs, introducing risks of discriminatory algorithms. Inclusive design processes and data diversity are essential to minimize bias and ensure accurate AI automation outcomes.
Security and Compliance
Understanding and addressing the security and compliance challenges inherent to automation becomes paramount for fostering trust, mitigating risks, and stimulating the sustainable growth of intelligent systems. Regulatory frameworks are essential to govern the development, deployment, and operation of AI systems, ensuring compliance with existing laws and standards. Meanwhile, ethical considerations address the responsible and fair use of AI, encompassing transparency, accountability, and bias mitigation in algorithmic decision making.
Striking a balance between innovation and compliance requires careful examination of data privacy, security, and the potential societal implications of AI applications. The development of robust governance models, informed by ethical principles, is crucial to fostering public trust and addressing concerns related to bias, discrimination, and unintended consequences in AI automation.
Robust compliance strategies that are imperative for ethical and lawful AI practices:
- Staying abreast of regulations
- Conducting ethical impact assessments
- Prioritizing transparency, fairness, and bias mitigation
- Adopting a privacy-by-design approach
- Ensuring data governance and quality
- Incorporating human oversight
- Implementing security measures
- Maintaining documentation and auditing
- Collaborating with stakeholders and providing employee training
- Continuously monitoring and improving compliance processes
Leveraging technology, especially advanced algorithms, and ML can significantly enhance AI regulatory compliance. This integration empowers organizations with real-time monitoring, analysis of vast datasets, proactive risk identification, and automatic updates to internal processes.
Proactive data security measures to help safeguard an organization's sensitive information and ensure the resilience and trustworthiness of its intelligent systems:
- Integrate privacy measures from the start, with core design elements focused on data protection practices (e.g., encryption, access control) and validate your solution provider's commitment to security policies
- Tailor data security measures to address unique requirements of specific industries (e.g., fraud prevention in finance)
- Schedule regular data deletion to minimize data storage, reducing susceptibility to data breaches and cyber threats
- Obscure and anonymize sensitive customer data during training and other processes to add an extra layer of protection in the event of unauthorized access
- Implement comprehensive access control mechanisms (e.g., RBAC, MFA) to limit data access to authorized personnel
- Conduct periodic security audits and penetration testing to pinpoint vulnerabilities and proactively mitigate risks.
- Enable regionalized data storage and controlled transfer to strengthen defenses against data breaches and cyber threats
Below are examples of several common data privacy concerns and mitigation strategies.
Data collection and storage – accumulated sensitive user information during AI processes, raising concerns about unauthorized access or misuse
- Implement anonymization to dissociate personal identifiers
- Employ secure encryption methods for data storage
Algorithmic bias – inherent biases in AI algorithms leading to discriminatory outcomes, compromising fairness and privacy
- Regularly audit and assess algorithms for bias, ensuring fair decision making
- Employ bias mitigation techniques
Inadequate consent mechanisms – lack of transparent and effective mechanisms for obtaining user consent, potentially leading to unauthorized use of personal data
- Implement clear and user-friendly consent processes, providing individuals with informed choices
- Ensure consent granularity
Data sharing and third parties – sharing sensitive data with third-party entities, posing risks if not properly regulated and leading to privacy breaches
- Establish robust data-sharing agreements with clear restrictions and safeguards
- Regularly audit third-party data-handling practices
Explainability and transparency – opacity in AI decision-making processes, undermining user trust and hindering their ability to understand how their data is used
- Utilize interpretable AI models that provide insights into decision logic
- Enhance transparency through clear communication about data processing practices
AI Automation Architecture
The AI automation architecture suite represents a comprehensive framework that intricately combines advanced algorithms, ML models, and efficient workflow orchestration, providing a structured and scalable foundation for organizations to seamlessly integrate and optimize AI technologies in diverse business processes.
AI Software Development Lifecycle
The AI software development lifecycle (SDLC) is a dynamic and iterative process that encompasses strategic planning, robust algorithm design, meticulous testing, and continual refinement to harness the full potential of AI technologies.
Here is the AI SDLC broken down into steps:
- Choose a scale-appropriate problem and involve frontline personnel for meaningful AI application development
- Identify tasks for AI automation to unlock opportunities while retaining the value of skilled human resources
- Collect, secure, transform, aggregate, label, and optimize datasets for AI/ML algorithm learning
- Define required AI capabilities, including ML, NLP, expert systems, vision, and speech
- Select an SDLC model with requirements analysis, design, development, testing, and deployment phases
- Consider customer empathy, experiments, modular AI components, and bias avoidance during business analysis
- Leverage AI development platforms for ML, NLP, expert systems, automation, vision, and speech, along with robust cloud infrastructure
- Refer to platform-specific documentation for AI development
- Address the complexities of large test data, human biases, regulatory compliance, security, and system integration for effective AI/ML testing
- Implement a robust internal handoff between IT operations and development teams for organization-wide access to the AI/ML solution
- Provide post-deployment support, warranty support, and long-term maintenance for sustained AI functionality
Scaling AI automation requires a comprehensive strategy for fast, secure, and reliable deployment across diverse infrastructures, including containers, private and public clouds, middleware, and mainframes. The AIOps pipeline ensures a seamless developer experience, complying with industry regulations, while continuous deployment enables secure application rollout with swift rollback capabilities. This approach incorporates AI/ML analytics to predict and mitigate application failure risks, reducing costs and enhancing the customer experience.
Optimization of AI automation deployments focuses on reducing cycle time, enhancing efficiency through automation, and minimizing errors. Security considerations include role-based access controls, audit logs, parameterized configurations, robust secrets management, and anticipating deployment failures for automated rollbacks and efficient oversight.
AI Coding Assistants
AI coding assistants revolutionize software development by leveraging AI to streamline coding processes. These advanced tools offer multifaceted support to developers, enhancing both speed and accuracy in their coding endeavors. Key functionalities include:
- Generating code snippets based on prompts or to provide intelligent suggestions for auto-completion as developers actively write their code
- Troubleshooting, debugging, and optimizing code for improved functionality
- Assessing and enhancing the overall quality of the codebase
- Offering intelligent code recommendations that enable developers to work more efficiently and effectively, saving time and resources