Tired of Reverse-Engineering Code? A Data-First Pattern for Legacy Modernization
Legacy modernization fails because teams try to decipher millions lines of code. Here is a pattern to slim down systems by reverse-engineering the data.
Join the DZone community and get the full member experience.
Join For FreeWe have all faced the Monolith from Hell. It’s a 20-year-old system. The documentation is missing, the original architects retired a decade ago, and the codebase is a tangled mess of spaghetti logic.
When tasked with modernizing such a system, the instinct is a function-first approach: read the source code, trace the logic, and try to replicate the existing functionality in a modern language.
This approach is flawed. It almost always leads to bloated modernization, where you inadvertently port over dead features, bugs, and inefficiencies.
A more effective strategy is the data-origin approach. Data doesn’t lie. By analyzing the actual state of the database rather than the code interacting with it, we can discover the true business rules and drastically reduce the scope of the new system.
Here is a three-step pattern to implement data-first modernization: modeling, profiling, and standardization.
The Core Concept: System Slimming
Legacy systems grow like coral reefs — layer upon layer of features that are no longer used. If you look at the code, a function might appear critical. But if you look at the database, you might find that the column populated by that function has been NULL for ten years.
The goal of this pattern is to identify dead data in order to identify dead code.
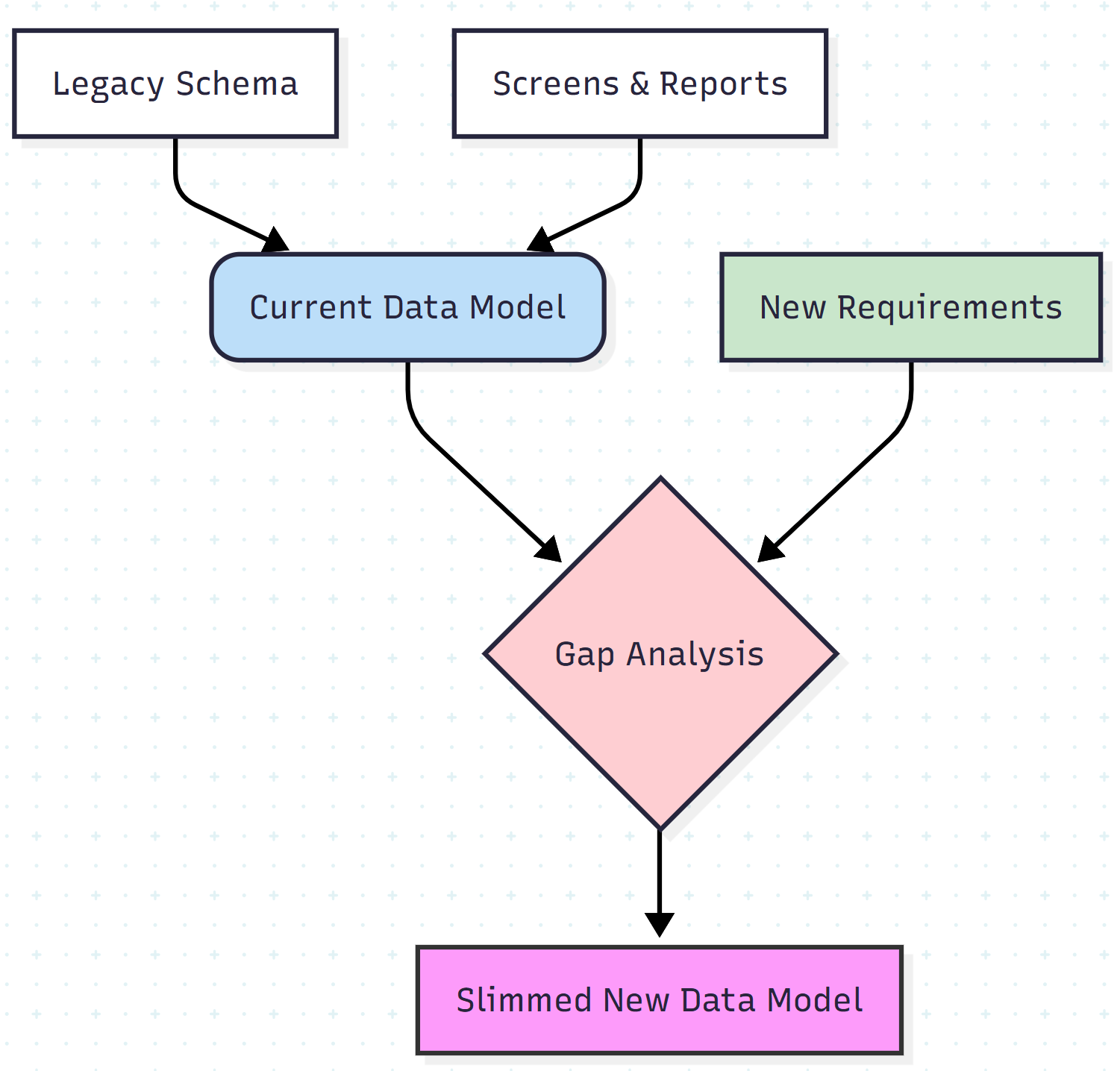
Step 1: Data Modeling (The Map)
Before writing a single line of new code, we must map the territory. We treat the legacy system’s database schema as a suggestion, not a fact.
The process involves three phases:
- Current State Modeling: Reverse-engineer the physical schema into a logical model.
- Constraint Extraction: Identify implied relationships that aren't enforced by foreign keys (often handled by application logic in legacy systems).
- Future State Modeling: Overlay new business requirements to see where the friction points are.
Instead of reading code, we look at screens and reports. These represent the actual input and output of the system. If a database column exists but never appears on a screen or report, it is a candidate for deletion.
Step 2: Data Profiling (The Reality Check)
This is the most critical step. Documentation may say a field is “required,” but the data might show it is 50% empty. Documentation may say a status code has five states; the data might reveal that only two are used.
We execute a four-stage profiling pipeline to determine the system’s actual usage.
The Profiling Pipeline
- Statistical Analysis: Calculate cardinality, null rates, and min/max values for every column.
- Single-Item Analysis: Check value distribution. If a “Configuration” column has the value
DEFAULTin 99.9% of rows, that feature is likely dead. - Correlation Analysis: Detect dependencies (for example, if
AccountTypeis “B,”CreditLimitis alwaysNULL). - Issue Extraction: Flag “zombie data” (data that exists but has no business meaning).
Implementation: SQL Profiling Strategy
You don't need complex AI for this. Simple SQL aggregation can reveal massive amounts of technical debt.
-- Example: Profiling a "Status" column to find unused business logic
SELECT
status_code,
COUNT(*) as frequency,
(COUNT(*) * 100.0 / (SELECT COUNT(*) FROM orders)) as percentage
FROM orders
GROUP BY status_code
ORDER BY frequency DESC;
-- Result:
-- | status_code | frequency | percentage |
-- |-------------|-----------|------------|
-- | CLOSED | 150,000 | 98.0% |
-- | OPEN | 3,000 | 1.9% |
-- | PENDING | 2 | 0.001% | <-- Candidate for feature removal
-- | ARCHIVED | 0 | 0.0% | <-- Dead Code CandidateIn this example, the code handling ARCHIVED and PENDING states might constitute 30% of the application logic, yet it applies to virtually zero records. Delete it.
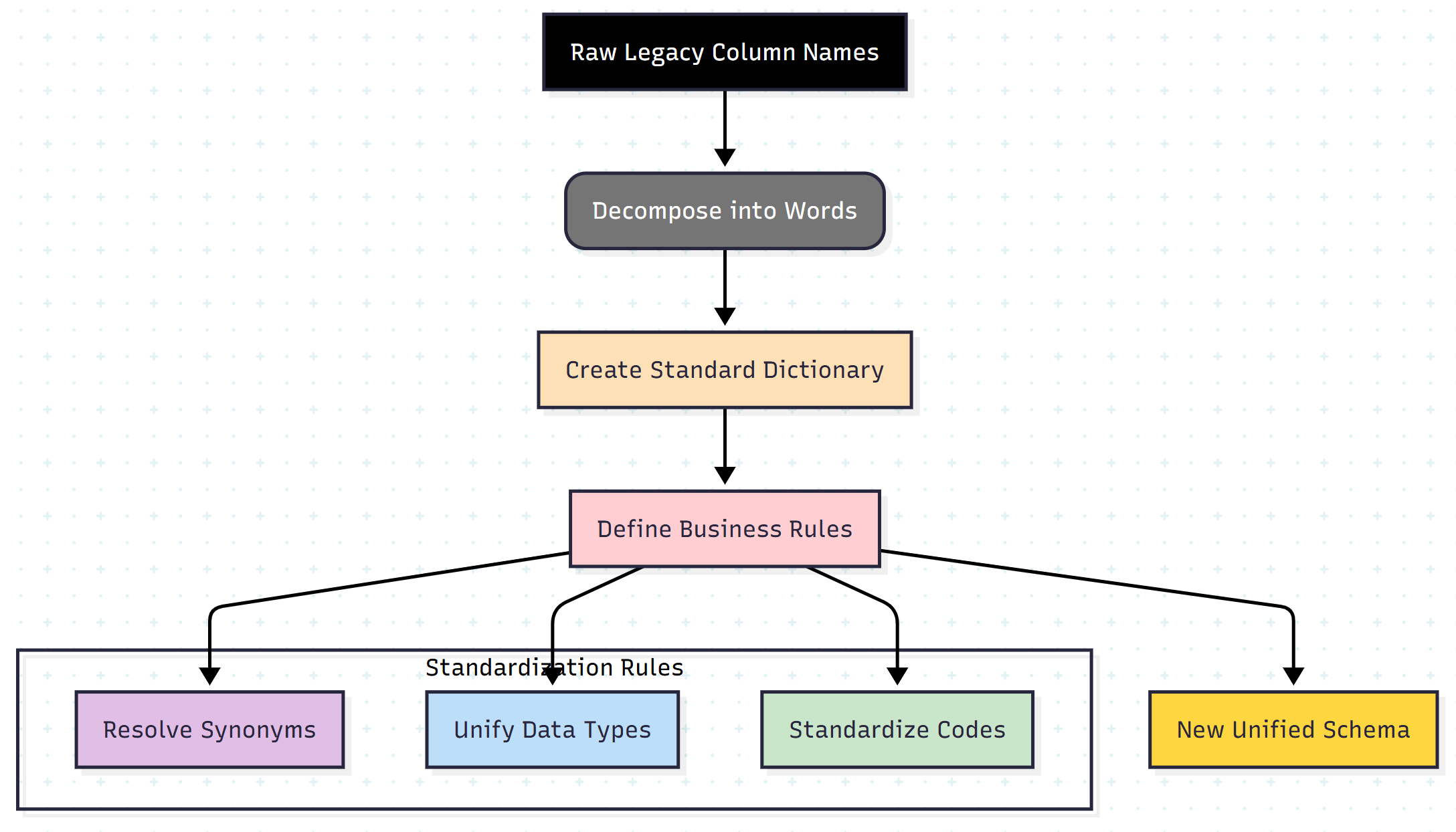
Step 3: Data Standardization (The Cleanup)
Legacy systems are notorious for inconsistent naming conventions (for example, cust_id, customer_no, c_id). This inconsistency makes microservices decomposition nearly impossible.
We apply a six-step standardization process:
- Item Extraction: Extract all column names from the legacy schema.
- Word Decomposition: Break
customer_address_homeinto Customer, Address, Home. - Dictionary Creation: Define standard terms (for example, Customer = Client, No = ID).
- Standard Definition: Create a “golden record” definition for every data element.
- Code Value Definition: Standardize flags (map
0/1,T/F,Y/Nto a single boolean standard). - Unification: Rename legacy columns to match the new standard.
The Standardization Flow
Results and ROI
By prioritizing data over code, you stop migrating waste. In a recent large-scale modernization project using this pattern, the engineering team achieved:
- 45% reduction in development scope: Nearly half the anticipated code did not need to be rewritten.
- 35% reduction in storage: Zombie data and unused columns were purged.
- 80% reduction in data items: Redundant columns were standardized (for example, merging
home_phoneandmobile_phoneintocontact_numberwith a type flag).
Conclusion
Modernization is not just about moving from COBOL or Java 6 to Go or Rust — it is an opportunity to declutter.
If you start by looking at the code, you will get lost in the complexity of how the system works. If you start by looking at the data, you understand what the system actually does.
Key takeaway: Before you write a single user story for your migration, profile your production database. The most efficient code is the code you realize you don’t need to write.
Opinions expressed by DZone contributors are their own.
Comments