A Fully Self‑Contained Text Embedding Service in C#
Build fast, deterministic text embeddings in C# using feature hashing, trigram features, and L2 normalization — no APIs, GPUs, or external models required.
Join the DZone community and get the full member experience.
Join For FreeModern semantic search, retrieval-augmented generation (RAG) pipelines, and large-scale recommendation models heavily rely on embeddings — transformations of natural language text into dense numeric representations called vectors. These embeddings position semantically related text in nearby regions of vector space. It enables similarity computation through distant metrices such as Cosine similarity or Euclidean distance. Cloud-hosted services like OpenAI has text-embedding-ada-002 provide high-quality vector encodings.
But it comes with API keys, network latency, and per-token usage costs. In contrast, LocalEmbeddingService does all the computation within hosted process, no GPUs, no outbound requests, no model files to manage.
The method it uses is called the hashing trick (or feature hashing). The same algorithm is implemented in scikit-learn’s HashingVectorizer.
1. Contract: IEmbeddingService
public class LocalEmbeddingService : IEmbeddingService
{
public int Dimensions => 512;The service creates 512-dimensional float vectors. This is intentional. It is large enough to capture document semantics yet small enough for in-memory dot-product similarity searches across millions of vectors. These dimensions can be increased to 1024 or 2048, but will require additional GPU and memory usage.
2. Stop Words
private static readonly HashSet<string> StopWords =
new(StopAnalyzer.ENGLISH_STOP_WORDS_SET, StringComparer.OrdinalIgnoreCase);Stop words are common high-frequency words like “and”, “the”, “is”, and “while”. It does contain minimal/no semantic information, but can heavily influence vectorized output if these are not filtered. In the above code, Lucene.NET’s nuget package is used, instead of hardcoding, which has a predefined set StopAnalyzer.ENGLISH_STOP_WORDS_SET. It is well curated and validated.
The set is wrapped in HashSet<string> with OrdinalIgnoreCase which provides fast case-insensitive lookup without any extra allocation at query time.
3. Text Cleaning — Tokenization
private static Dictionary<string, int> Tokenize(string text)
{
var freq = new Dictionary<string, int>(StringComparer.OrdinalIgnoreCase);
var tokens = text
.ToLowerInvariant()
.Split(new[] { ' ', '\t', '\n', '\r', ',', '.', '!', '?', ';', ':',
'"', '\'', '(', ')', '[', ']', '{', '}',
'-', '_', '/', '\\' },
StringSplitOptions.RemoveEmptyEntries)
.Where(t => t.Length > 2 && !StopWords.Contains(t));
foreach (var token in tokens)
freq[token] = freq.GetValueOrDefault(token) + 1;
return freq;
}Tokenization is the very first step of text cleaning. Each word has to go through it. It has 3 main things.
- Lowercasing: It keeps all the words in lower case. “System” and “system” have the same meaning.
- Split based on delimiter/punctuation: Each delimiter/punctuation is considered as a word boundary. “top-of-the-line” will become [“top”, “line”] after splitting and removing stop words.
- Filtering: If the tokens are less than 3 characters, then they will be skipped with stop words.
After tokenization, it gives a term-frequency map like { "compute": 2, "learn": 3, "embedding": 1, … }.
4. Hashing Trick/Feature Hashing
The core challenge here is the size of real-world vocabularies. There are millions of distinct terms. It makes it almost impossible to allocate a separate vector dimension per term/token. Hashing tricks solve this problem by hashing tokens directly into a bounded index range via a hash function. It will eliminate the need to store a vocabulary.
private static int StableBucket(string token, int size)
{
unchecked
{
uint hash = 2166136261u; // FNV offset basis
foreach (char c in token)
{
hash ^= (byte)c;
hash *= 16777619u; // FNV prime
}
return (int)(hash % (uint)size);
}
}Here FNV-1a (Fowler–Noll–Vo) hash function is used. It is a lightweight, non-cryptographic hash ideal for short strings with excellent bit distribution. It uses two canonical constants.
- FNV offset basis: Decimal: 2166136261, Hex: 0x811C9DC5
- FNV prime: Decimal: 16777619, Hex: 0x01000193
Each character is processed by XOR-ing the current hash with the character’s byte value. Then it is multiplied by FNV prime. The XOR-then-Multiply order ensures every byte influences 32 bits, improving avalanche behavior for short tokens like English words.
Here .NET’s string.GetHashCode() is not useful because it randomizes per process run against hash flooding attacks. The StableBucket is required to return same bucket indices across every run for deterministic 32-bit results.
The use of unchecked in C# ensures overflow checking for 32-bit integer semantics.
5. Log-Based TF Normalization
float weight = MathF.Log(1f + count);Term frequency does not scale linearly with semantic importance. For example, a word/term that appears 10 times in a document is not actually 10 times more important that the term appears once. When the log log(1 + count) is applied, it compresses the raw frequency.
The table below shows how this log-based frequency works.
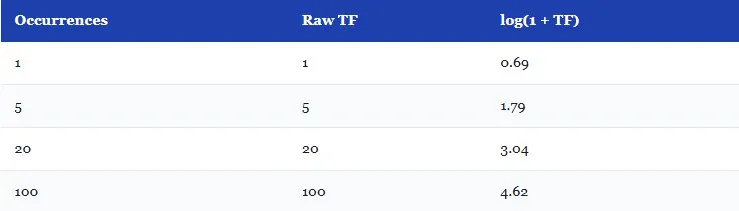
This ensures that no single repeated term disproportionately shapes the embedding, the same reasoning behind TF-IDF in traditional information retrieval systems.
6. Trigram Features for Morphology Capture
if (token.Length >= 4)
{
for (int i = 0; i <= token.Length - 3; i++)
{
string trigram = token[i..(i + 3)];
int trigramBucket = StableBucket(trigram, Dimensions);
vector[trigramBucket] += weight * 0.5f;
}
}Whole world hashing can produce hard edge cases for terms like “play”, “player”, “playing”. These terms are treated as separate features and land in different buckets. Trigrams help to reconnect them and smooth out these gaps.
Here are trigrams for “playing” and “player”.
playing - pla, lay, ayi, yin, ing
player - pla, lay, aye, yerHere, common trigrams like pla and lay cause both terms to accumulate weight in some of the same hashed buckets, which pulls their vectors closer in embedding space. The half weight (o.5f ) ensures that trigram features do not dominate the whole-word signal.
7. L2 Vector Normalization — Cosine Similarity via Direct Dot Products
private static void NormalizeL2(float[] vector)
{
float magnitude = 0f;
foreach (float v in vector) magnitude += v * v;
magnitude = MathF.Sqrt(magnitude);
if (magnitude > 0f)
for (int i = 0; i < vector.Length; i++)
vector[i] /= magnitude;
}Once all token and trigram weights have been applied, the resulting vector is normalized so that its Euclidean length equals 1. This normalization enables a key mathematical identity:
cosine_similarity(a, b) = a · b when ‖a‖ = ‖b‖ = 1When vectors are already L2-normalized, the cosine similarity is evaluated using the raw dot product operation, eliminating the need for any division.
8. Utility: GetTopTokenWeights
public Dictionary<string, float> GetTopTokenWeights(string text, int topN = 10)
{
var tokenFreq = Tokenize(text);
return tokenFreq
.Select(kv => new { Token = kv.Key, Weight = MathF.Log(1f + kv.Value) })
.OrderByDescending(x => x.Weight)
.Take(topN)
.ToDictionary(x => x.Token, x => x.Weight);
}This diagnosis method highlights the tokens that contributed most to the final embeddings. It provides critical insight into why two documents achieve high similarity scores and confirms that the stop word removal and tokenization are working as expected.
Limitations and Production Enhancements
This service is fully deterministic, fast, and requires zero supporting infrastructure. It performs well for vocabulary-driven similarity — cases where documents share the same vocabulary. It does not encode semantic relationships. For example, “car” and “sedan” will end up in separate buckets and will not have the same similarity score.
For production-grade semantic search, LocalEmbeddingService can be replaced with either OpenAI or a local ONNX sentence transformer. The shared IEmbeddingService interface by both implementations ensures that no code change is required for any components like API Controllers, vector index, or retrieval logic.
Project repository: TextEmbeddingService
Published at DZone with permission of Mangesh Walimbe. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments