Enabling Data Recovery With Apache Ignite Native Persistence
Learn how you can safely cross off the "data recovery" bullet from your architectural to-do list using Apache Ignite Native Persistence.
Join the DZone community and get the full member experience.
Join For FreeIn-memory databases, data grids, and computing platforms just cannot put aside the existence — and necessity — of good old-fashioned disk drives. The performance boost given by RAM is tempting and promising, but almost nobody wants to lose data. Services and applications call for durability unless the data is of no value to them or floods into the system at such a rate that you can sacrifice periodic data loss.
Apache Ignite has been able to use third-party persistence stores from the time it was born. The project is well integrated with relational databases (i.e. MongoDB or Cassandra) that back up your fast Ignite in-memory cluster at the disk level.
However, the restless Apache Ignite community was not entirely satisfied with this data persistence approach and eventually announced its own Ignite Native Persistence that is transparently integrated into the re-engineered durable memory architecture. The reasoning behind that decision is analyzed in this blog post on the Apache Software Foundation's web page.
Apparently, this new capability in Ignite will expand its usage and applicability... but usually, new opportunities bring new responsibilities. Ignite can definitely pursue new opportunities with its own durable memory architecture and native persistence. Where are the new responsibilities then? That's data recovery, folks — data recovery!
Data Recovery
 We all want to run our services and applications in an ideal world with no downtime, data loss, or performance bottlenecks. But the reality is vicious, unstable, and unpredictable. This is why software architects take the topic of data recovery seriously.
We all want to run our services and applications in an ideal world with no downtime, data loss, or performance bottlenecks. But the reality is vicious, unstable, and unpredictable. This is why software architects take the topic of data recovery seriously.
Regardless of the fact that the data is persisted on-disk, it can be easily damaged, erased, or corrupted. These are some of the possible reasons that spin around in my head:
- A new version of a software was rolled out in production and included a bug that corrupted a piece of data stored on disk.
- An IT guy was inattentive and executed an operation that erased some dataset completely.
- Disk drives will eventually wear out — damaging hardware cells and, as a result, data stored there.
Apache Ignite as a platform has never worried about the data recovery requirements before simply because it was not its zone of responsibility. That's pretty fair. If you use an Ignite cluster as-is, without any persistence, then on the occasion of data corruption or loss, you need to restart the in-memory cluster and preload consistent data back to it. If there is a persistence layer below Ignite, such as a relational database, then it's an RDBMS vendor's burden to take care of the data recovery.
RDBMS vendors solved this task long ago. To recover from any of three data-damaging causes listed above you just need to have a data backup or snapshot on hand. Every mature RDBMS provides a way to do full and incremental backups and snapshots that even allows for automating data recovering routines if needed.
Now it's Apache Ignite's turn to solve the data recovery task if its own native persistence is enabled. Data backups and snapshots are not available in the project but there are special interfaces that help to build data snapshotting functionality on top.
Distributed Data Snapshots
GridGain Ultimate Edition provides the ability to create snapshots of data stored cluster-wide that can later be used for a cluster's data recovery purposes. Moreover, snapshots taken from one cluster can also be applied to the second cluster. Essentially, GridGain snapshots are similar to RDBMS backups. The main reason why GridGain snapshots are not called "backups" is to avoid confusion with Apache Ignite backup copies of data stored in the cluster.
There are also a couple of tools that facilitate snapshot creation, management, and data recovery procedures. For instance, IT administrators can make shell scripts (and spend more time sipping coffee) rely on the command line-based Snapshots Management Tool.
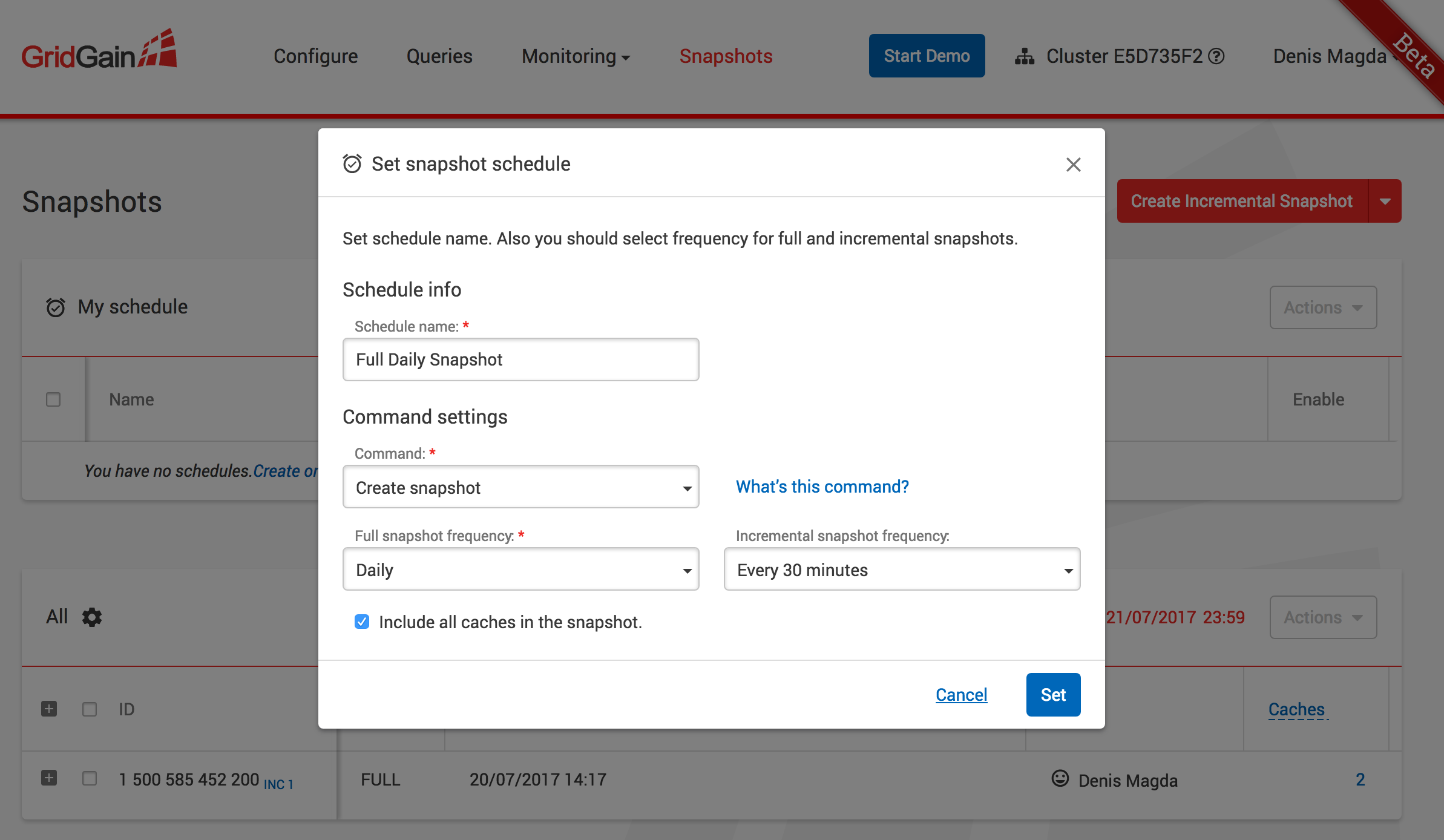
The second tool, the GridGain Web Console, helps not only achieve the same with a nice looking user interface but also allows building snapshots creation and management schedules. For example, if we need to create a full snapshot daily with incremental snapshots every next 30 minutes, this can be easily automated with a couple of clicks as shown on the screen below:
The Upshot
Regardless of the architecture that you build applications on, you should bring data recovery requirements to the table and predict consequences if somebody insists they are not relevant for your applications. You will definitely have to pay one day or another if not enough attention was dedicated to this topic.
Published at DZone with permission of Denis Magda. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments