AWS Partition Projections: Enhancing Athena Query Performance
This article provides an analysis of performance improvements in AWS Athena queries using the partition projections feature.
Join the DZone community and get the full member experience.
Join For FreeIn today's data-driven landscape, organizations are increasingly turning to robust solutions like AWS Data Lake to centralize vast amounts of structured and unstructured data. AWS Data Lake, a scalable and secure repository, allows businesses to store data in its native format, facilitating diverse analytics and machine learning tasks. One of the popular tools to query this vast reservoir of information is Amazon Athena, a serverless, interactive query service that makes it easy to analyze data directly in Amazon S3 using standard SQL. However, as the volume of data grows exponentially, performance challenges can emerge. Large datasets, complex queries, and suboptimal table structures can lead to increased query times and costs, potentially undermining the very benefits that these solutions promise. This article delves specifically into the details of how to harness the power of partition projections to address these performance challenges.
Before diving into the advanced concept of partition projections in Athena, it's essential to grasp the foundational idea of partitions, especially in the context of a data lake.
What Are Partitions in AWS Data Lake?
In the realm of data storage and retrieval, a partition refers to a division of a table's data based on the values of one or more columns. Think of it as organizing a vast bookshelf (your data) into different sections (partitions) based on genres (column values). By doing so, when you're looking for a specific type of book (data), you only need to search in the relevant section (partition) rather than the entire bookshelf.
In a data lake, partitions are typically directories that contain data files. Each directory corresponds to a specific value or range of values from the partitioning column(s).
Why Are Partitions Important?
Efficiency: Without partitions, querying vast datasets would involve scanning every single file, which is both time-consuming and costly. With partitions, only the relevant directories are scanned, significantly reducing the amount of data processed.
- Cost Savings: In cloud environments like AWS, where you pay for the amount of data scanned, partitions can lead to substantial cost reductions.
- Scalability: As data grows, so does the importance of partitions. They ensure that even as your data lake swells with more data, retrieval times remain manageable.
Challenges With Partitions
While partitions offer numerous benefits, they aren't without challenges:
- Maintenance: As new data comes in, new partitions might need to be created, and existing ones might need updates.
- Optimal Partitioning: Too few partitions can mean you're still scanning a lot of unnecessary data. Conversely, too many partitions can lead to a large number of small files, which can also degrade performance.
With this foundational understanding of partitions in a data lake, we can now delve deeper into the concept of partition projections in Athena and how they aim to address some of these challenges.
What Are Partition Projections?
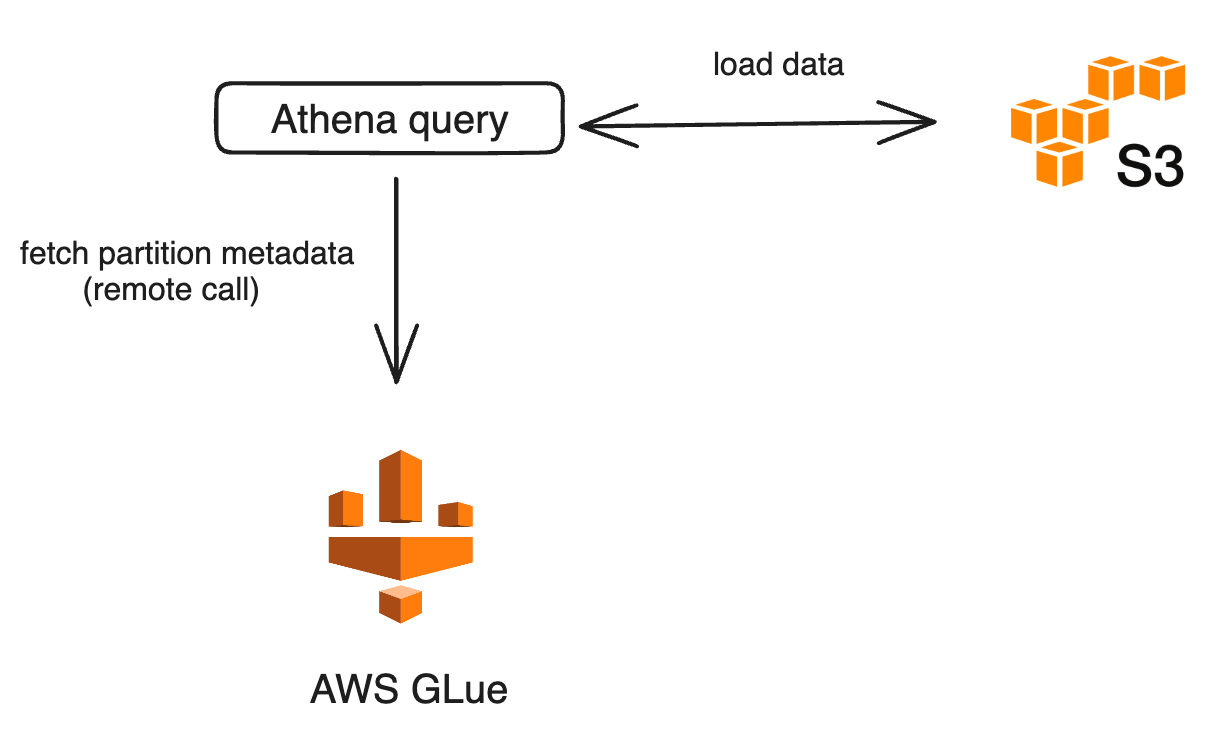
Partition pruning is a technique where only the relevant metadata, specific to a query, is selected, eliminating unnecessary data. This method often makes queries run faster. Athena employs this strategy for all tables that have partitioned columns. In a typical scenario, when Athena processes queries, it first communicates with the AWS Glue Data Catalog by making a GetPartitions request, after which it performs partition pruning. However, if a table has an extensive set of partitions, this call can slow things down.
To avoid this expensive operation on a highly partitioned table, AWS has introduced the technique of partition projections. With partition projection, Athena doesn't need to make the GetPartitions call. Instead, the configuration provided in partition projection equips Athena with all it needs to create the partitions on its own.
Benefits of Partition Projections
- Improved Query Performance: By reducing the amount of data scanned, queries run faster and more efficiently.
- Reduced Costs: With Athena, you pay for the data you scan. By scanning less data, costs are minimized.
- Simplified Data Management: Virtual partitions eliminate the need for continuous partition maintenance tasks, such as adding new partitions when new data arrives.
Setting Up Partition Projections
To utilize partition projections:
1. Define Projection Types: Athena supports several projection types, including `integer,` `enum,` `date,` and `injected.` Each type serves a specific use case, like generating a range of integers or dates.
2. Specify Projection Configuration: This involves defining the rules and patterns for your projections. For instance, for a date projection, you'd specify the start date, end date, and the date format.
3. Modify Table Properties: Once projections are defined, modify your table properties in Athena to use these projections.
An Example Use-Case
Let us take an example where our data is stored in the data lake and is partitioned by customer_id and dt. The data is stored in parquet format, which is a columnar data format.
s3://my-bucket/data/customer_id/yyyy-MM-dd/*.parquet
In our example, let us have data for one year, i.e., 365 days and 100 customers. This would result in 365*100=36500 partitions on the data-lake.
Let us benchmark the queries on this table with and without partition projections enabled.
Let us get the count of all the records for the entire year for five customers.
Query
SELECT count(*) FROM "analytic_test"."customer_events"
where dt >= '2022-01-01' and
customer_id IN ('Customer_001', 'Customer_002', 'Customer_003', 'Customer_004', 'Customer_005')Without Partition Projection
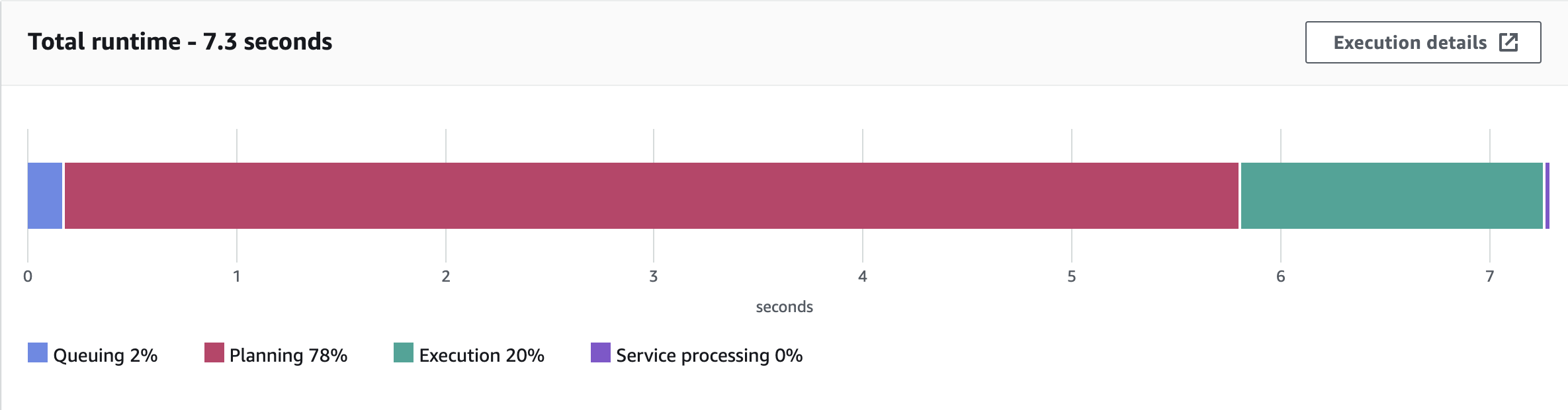
Without partition projections enabled, the total query runtime is 7.3 seconds. Out of that, it spends 78% in planning and 20% executing the query.
Query Results
Planning: 78% = 5.6 seconds
Execution 20% = 1.46
With Partition Projections
Now, let us enable partition projection for this table. Take a look at all the table properties that are suffixed with "partition.*". In this example, since we had two partitions, dt and cutsomer_id. We will use date type projection, and for customer_id, we will use enum type projection. For enum types, you can build an automation job to update the table property whenever there are newer records for it.
CREATE EXTERNAL TABLE `customer_events`(
`event_id` bigint COMMENT '',
`event_text` string COMMENT '')
PARTITIONED BY (
`customer_id` string COMMENT '',
`dt` string COMMENT '')
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
's3://my-bucket/data/events.customer_events'
TBLPROPERTIES (
'has_encrypted_data'='false',
'parquet.compression'='SNAPPY',
'transient_lastDdlTime'='1698737433',
'projection.enabled'='true',
'projection.dt.type'='date',
'projection.dt.range'='NOW-1YEARS,NOW',
'projection.dt.format'='yyyy-MM-dd',
'projection.dt.interval'='1',
'projection.dt.interval.unit'='DAYS',
'projection.customer_id.type'='enum',
'projection.customer_id.values'='Customer_001,Customer_002,Customer_003,Customer_004,Customer_005,Customer_006,Customer_007,Customer_008,Customer_009,Customer_010,Customer_011,Customer_012,Customer_013,Customer_014,Customer_015,Customer_016,Customer_017,Customer_018,Customer_019,Customer_020,Customer_021,Customer_022,Customer_023,Customer_024,Customer_025,Customer_026,Customer_027,Customer_028,Customer_029,Customer_030,Customer_031,Customer_032,Customer_033,Customer_034,Customer_035,Customer_036,Customer_037,Customer_038,Customer_039,Customer_040,Customer_041,Customer_042,Customer_043,Customer_044,Customer_045,Customer_046,Customer_047,Customer_048,Customer_049,Customer_050,Customer_051,Customer_052,Customer_053,Customer_054,Customer_055,Customer_056,Customer_057,Customer_058,Customer_059,Customer_060,Customer_061,Customer_062,Customer_063,Customer_064,Customer_065,Customer_066,Customer_067,Customer_068,Customer_069,Customer_070,Customer_071,Customer_072,Customer_073,Customer_074,Customer_075,Customer_076,Customer_077,Customer_078,Customer_079,Customer_080,Customer_081,Customer_082,Customer_083,Customer_084,Customer_085,Customer_086,Customer_087,Customer_088,Customer_089,Customer_090,Customer_091,Customer_092,Customer_093,Customer_094,Customer_095,Customer_096,Customer_097,Customer_098,Customer_099,Customer_100')Query results
Planning: 1.69 seconds
Execution: 0.6 seconds
Results
We can see a roughly 70% improvement in the query performance. This is because Athena avoids a remote call to AWS glue to fetch the partitions, as with this feature, it is able to project the values for these partitions.
Limitations and Considerations
While powerful, partition projections do not solve all the problems.
- Complex Setups: Setting up projections requires a deep understanding of your data and the patterns it follows.
- Not Always the Best Fit: For datasets that don't follow predictable patterns or have irregular updates, traditional partitioning might be more suitable.
Conclusion
AWS's introduction of Partition Projections in Athena is a testament to their commitment to improving user experience and efficiency. By leveraging this feature, organizations can achieve faster query performance with minimal configuration changes. As with all tools, understanding its strengths and limitations is key to harnessing its full potential.
Opinions expressed by DZone contributors are their own.
Comments