Azure SLM Showdown: Evaluating Phi-3, Llama 3, and Snowflake Arctic for Production
Evaluate Phi-3, Llama 3, and Snowflake Arctic. Learn to deploy cost-effective, high-performance SLMs on Azure for production workloads.
Join the DZone community and get the full member experience.
Join For FreeIn the rapidly evolving landscape of Generative AI, the industry is witnessing a significant shift. While the “bigger is better” mantra once dominated, the tide is turning. As organizations move from experimental pilots to production-grade applications, the focus has shifted toward small language models (SLMs). These models offer lower latency, reduced compute costs, and the ability to run on edge devices, while maintaining performance that rivals massive models like GPT-4 for specific tasks.
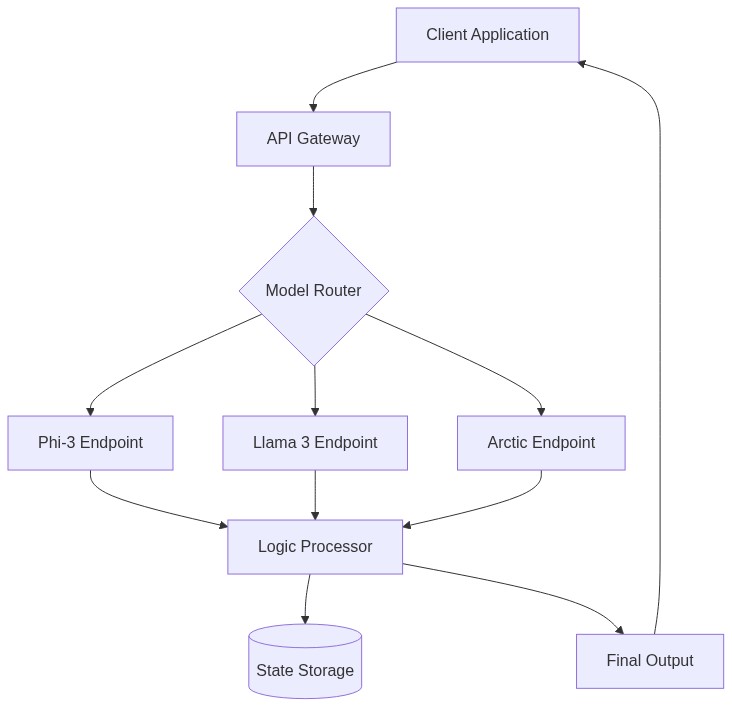
Microsoft Azure has positioned itself as a premier destination for these models, offering them through the Model-as-a-Service (MaaS) framework and the Azure AI Model Catalog. In this article, we provide a technical deep dive into three of the most prominent SLMs available on Azure: Microsoft’s Phi-3, Meta’s Llama 3 (8B), and Snowflake Arctic. We analyze their architectures, benchmark performance, deployment strategies, and cost efficiency to help you decide which model best fits your workload.
1. Microsoft Phi-3: The Master of Efficiency
Microsoft’s Phi-3 family represents a breakthrough in how model quality is achieved. Rather than relying on sheer volumes of web-scraped data, Phi-3 was trained on Phi-3-specific data — a combination of highly filtered web data and synthetic data designed to resemble the clarity and educational value of textbooks.
Architecture and Variations
Phi-3 is available in several sizes, but Phi-3 Mini (3.8B parameters) is the most popular for SLM use cases. Despite its small size, it frequently outperforms models twice its size (such as Llama 2 7B or Mistral 7B) on reasoning and logic tasks. It uses a dense Transformer architecture and is optimized for ONNX Runtime, making it ideal for cross-platform deployment.
Pros and Cons
Pros
- Unmatched efficiency: Extremely low resource footprint; can run on basic CPU-only instances or mobile devices.
- Reasoning capability: Exceptionally strong at logical reasoning and mathematics relative to its size.
- Permissive licensing: MIT license allows broad commercial use.
Cons
- Knowledge cutoff: Due to its focus on reasoning over factual memorization, it may struggle with niche factual queries without RAG (Retrieval-Augmented Generation).
- Context window limitations: While a 128k context version exists, the baseline 4k version is limited for long-document processing.
2. Meta Llama 3 (8B): The Generalist Powerhouse
Llama 3 8B is the evolution of Meta’s highly successful open-weights lineage. Trained on a massive 15 trillion tokens, Llama 3 emphasizes versatility and conversational fluency. It is the “Swiss Army knife” of SLMs, designed to handle everything from creative writing to complex coding.
Architecture and Improvements
Llama 3 uses a standard decoder-only Transformer architecture but introduces a more efficient tokenizer with a 128k vocabulary, significantly improving token compression and inference speed. It also features Grouped Query Attention (GQA), which enhances performance during long-context inference.
Pros and Cons
Pros
- Generalization: Excellent at following complex instructions and maintaining a consistent persona.
- Ecosystem support: As an industry standard for open-weights models, it has best-in-class support for quantization and fine-tuning tools (UnsLoTH, vLLM, etc.).
- Fine-tuning potential: Highly responsive to supervised fine-tuning (SFT) and RLHF.
Cons
- Compute requirements: Requires more VRAM than Phi-3 and typically needs an A10 or T4 GPU for comfortable inference.
- Licensing constraints: The Llama 3 Community License includes restrictions for very large-scale commercial deployments (over 700M monthly active users).
3. Snowflake Arctic: The Enterprise Specialist
Snowflake Arctic is a unique entrant in the SLM space. While its total parameter count is large (480B), it uses a Mixture-of-Experts (MoE) architecture. In this setup, only a small subset of parameters (about 17B) is active during any single inference request. This makes it “small” in terms of compute cost per token, even though its memory footprint is larger.
Architecture and Enterprise Focus
Arctic was built specifically for enterprise tasks such as SQL generation, coding, and complex instruction following. It uses a dense-to-MoE hybrid design that prioritizes high-quality reasoning over broad creative knowledge.
Pros and Cons
Pros
- Data-to-SQL mastery: Outperforms nearly all peers for generating SQL and interacting with structured data.
- MoE efficiency: Delivers the reasoning depth of a massive model with the token-generation speed of a much smaller one.
- Apache 2.0 license: Fully open for commercial use without restrictive clauses.
Cons
- Memory footprint: Because all 480B parameters must be loaded into memory (unless using quantized or offloaded variants), it requires significantly more GPU memory than Phi-3 or Llama 3 8B.
- Deployment complexity: Best suited for Azure’s serverless MaaS endpoints rather than small self-hosted VMs.
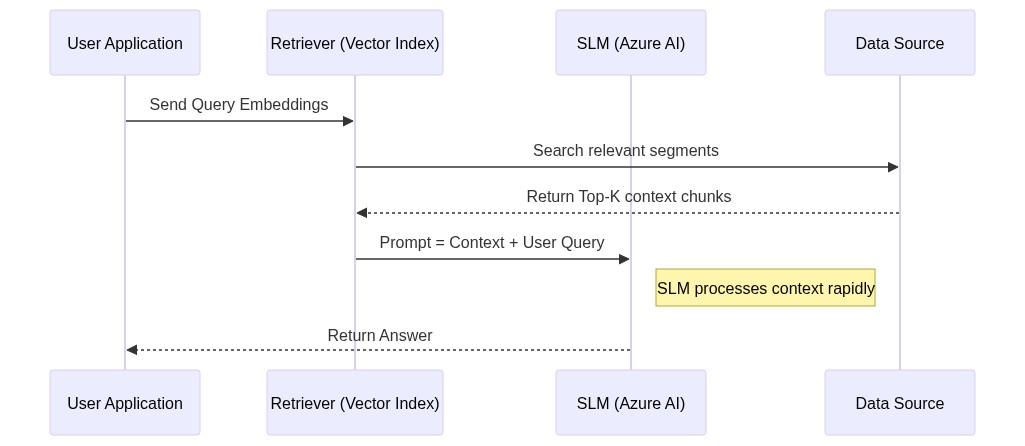
Advanced Data Flow: RAG with SLMs
Retrieval-Augmented Generation (RAG) is one of the most common production patterns. SLMs are particularly well suited for RAG because they can process retrieved context with much lower latency than GPT-4. However, smaller context windows — such as Arctic’s 4k or Llama 3’s 8k — require more sophisticated retrieval strategies compared to Phi-3’s 128k variant.
Technical Comparison Tables
To better understand how these models stack up, we have categorized their capabilities into three comparison tables focusing on technical specifications, benchmarks, and Azure-specific deployment factors.
Table 1: Technical Specifications
| Feature | Phi-3 Mini | Llama 3 8B | Snowflake Arctic |
|---|---|---|---|
| Parameters | 3.8 Billion | 8 Billion | 480B (17B Active) |
| Architecture | Dense Transformer | Dense Transformer | MoE (Mixture of Experts) |
| Context Window | 4k / 128k | 8k | 4k |
| Tokenizer | 32k Vocab | 128k Vocab | 32k Vocab |
| Licensing | MIT | Llama 3 Community | Apache 2.0 |
| Primary Strength | Reasoning & Logic | General Purpose | SQL & Coding |
Table 2: Benchmark Performance (Reported Figures)
| Benchmark | Phi-3 Mini | Llama 3 8B | Snowflake Arctic |
|---|---|---|---|
| MMLU (General) | 68.8% | 66.6% | 62.9% |
| GSM8K (Math) | 82.5% | 79.6% | 66.1% |
| HumanEval (Code) | 58.5% | 62.2% | 64.3% |
| BigBench Hard | 69.7% | 61.1% | 51.5% |
Table 3: Azure Deployment and Cost (Estimated)
| Factor | Phi-3 Mini | Llama 3 8B | Snowflake Arctic |
|---|---|---|---|
| Azure MaaS Availability | Yes (Serverless) | Yes (Serverless) | Yes (Serverless) |
| Min. Recommended VM | Standard_NC6s_v3 | Standard_NC24s_v3 | Standard_ND96asr_v4 |
| Cost per 1M Input | ~$0.10 | ~$0.15 | ~$0.24 |
| Cost per 1M Output | ~$0.10 | ~$0.60 | ~$0.24 |
| Fine-Tuning Support | Azure AI Studio LoRA | Azure AI Studio LoRA | Azure ML / Custom |
Note: Costs are based on average Azure Model-as-a-Service pricing and are subject to regional variation.
Analysis: Which Model Should You Choose?
Use Case 1: Low-Latency Edge Applications
If you are building an application that needs to run on a local device or requires the absolute lowest latency for simple tasks (like text classification or basic summarization), Phi-3 Mini is the undisputed winner. Its small footprint allows it to be quantized to 4-bit and run on a standard laptop CPU while still providing coherent, logical responses.
Use Case 2: Sophisticated Chatbots and Creative Tools
For applications requiring “personality,” conversational nuance, and broad general knowledge, Llama 3 8B is superior. It has a much lower “hallucination" rate in casual conversation compared to Phi-3 and handles creative tasks (like drafting emails or marketing copy) with much better flow and vocabulary diversity.
Use Case 3: Enterprise Data Bots and SQL Generation
If your goal is to build a copilot for your data warehouse or an internal tool that generates SQL queries from natural language, Snowflake Arctic is designed for this specific purpose. Its training focus on “Enterprise Intelligence” makes it more reliable for code generation and technical instruction following than its dense SLM counterparts.
Deployment Strategies on Azure
Azure offers two primary ways to deploy these models, each with distinct advantages.
1. Model-as-a-Service (Serverless APIs)
This is the recommended approach for most developers. You don't need to manage GPUs; instead, you call an API and pay per token.
- Best for: Burst workloads, rapid prototyping, and applications where managing infrastructure is a bottleneck.
- How-to: Navigate to Azure AI Studio, select the model from the catalog, and click “Deploy” -> “Serverless API.”
2. Managed Online Endpoints (Dedicated Infrastructure)
This involves deploying the model onto a specific Azure VM instance (e.g., NCv3-series).
- Best for: High-volume, steady-state workloads where token-based pricing becomes more expensive than hourly VM costs, or when high customization of the inference server (like using vLLM) is required.
- How-to: Use the
azure-ai-mlPython SDK to define an endpoint and deployment configuration.
Fine-Tuning Example: Phi-3 on Azure AI Studio
Fine-tuning is essential for making an SLM perform like a specialized expert. Here is a conceptual workflow for fine-tuning Phi-3 using Low-Rank Adaptation (LoRA) on Azure.
Step 1: Data Preparation
Format your data into a JSONL file. For Phi-3, the format should follow the ChatML structure:
{"messages": [{"role": "user", "content": "Explain quantum physics to a toddler."}, {"role": "assistant", "content": "Quantum physics is like having a toy that can be in two boxes at the same time..."}]}Step 2: Submission via Python SDK
Using the Azure AI SDK, you can trigger a fine-tuning job on a GPU cluster:
from azure.ai.ml import MLClient
from azure.ai.ml.entities import FineTuningJob
# Initialize client
ml_client = MLClient(credential, subscription_id, resource_group, workspace_name)
# Define the job
job = FineTuningJob(
model="azureml://registries/azureml/models/Phi-3-mini-4k-instruct",
task="chat_completion",
training_data=Input(type="uri_file", path="path_to_your_data.jsonl"),
hyperparameters={
"learning_rate": "0.0002",
"batch_size": "4",
"epochs": "3"
}
)
# Submit the job
ml_client.jobs.create_or_update(job)This approach utilizes LoRA, which only updates a small fraction of the model's weights, significantly reducing the VRAM required for training and preventing “catastrophic forgetting.”
Conclusion: The Right Tool for the Job
Choosing between Phi-3, Llama 3, and Snowflake Arctic on Azure is not about which model is objectively “best,” but which best aligns with your operational constraints:
- Choose Phi-3 when compute efficiency and logical reasoning are paramount.
- Choose Llama 3 8B when you need a versatile, conversational generalist with a rich ecosystem.
- Choose Snowflake Arctic when your application centers on structured data, SQL, and enterprise-grade code generation.
As Azure continues to expand its Model Catalog, standardized APIs make swapping models easier than ever, reducing the risk of model lock-in. Organizations should test prompts across all three to find the optimal balance of cost, performance, and capability for their specific workloads.
Conclusion: The Right Tool for the Job
Choosing between Phi-3, Llama 3, and Snowflake Arctic on Azure is not about which model is objectively “best,” but which best aligns with your operational constraints:
- Choose Phi-3 when compute efficiency and logical reasoning are paramount.
- Choose Llama 3 8B when you need a versatile, conversational generalist with a rich ecosystem.
- Choose Snowflake Arctic when your application centers on structured data, SQL, and enterprise-grade code generation.
As Azure continues to expand its Model Catalog, standardized APIs make swapping models easier than ever, reducing the risk of model lock-in. Organizations should test prompts across all three to find the optimal balance of cost, performance, and capability for their specific workloads.
Published at DZone with permission of Jubin Abhishek Soni. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments