Benefits of REST APIs With HTTP/2
HTTP/2 brings with it a lot of benefits for REST APIs, both on the integration side of things and in terms of performance and security.
Join the DZone community and get the full member experience.
Join For Freehttp/1.x vs http/2
first, let's look at some of the high-level differences:
http/2 is binary, instead of textual
binary protocols are more efficient to parse, more compact "on the wire," and, most importantly, they are much less error-prone compared to textual protocols like http/1.x, because they often have a number of affordances to "help" with things like whitespace handling, capitalization, line endings, blank lines, and so on.
for example, http/1.1 defines four different ways to parse a message; in http/2 , there's just one code path.
http/2 is fully multiplexed, instead of ordered and blocking
http/1.x has a problem called "head-of-line blocking," where effectively only one request can be outstanding on a connection at a time.
http/1.1 tried to fix this with pipelining, but it didn't completely address the problem (a large or slow response can still block others behind it). additionally, pipelining has been found very difficult to deploy, because many intermediaries and servers don't process it correctly.
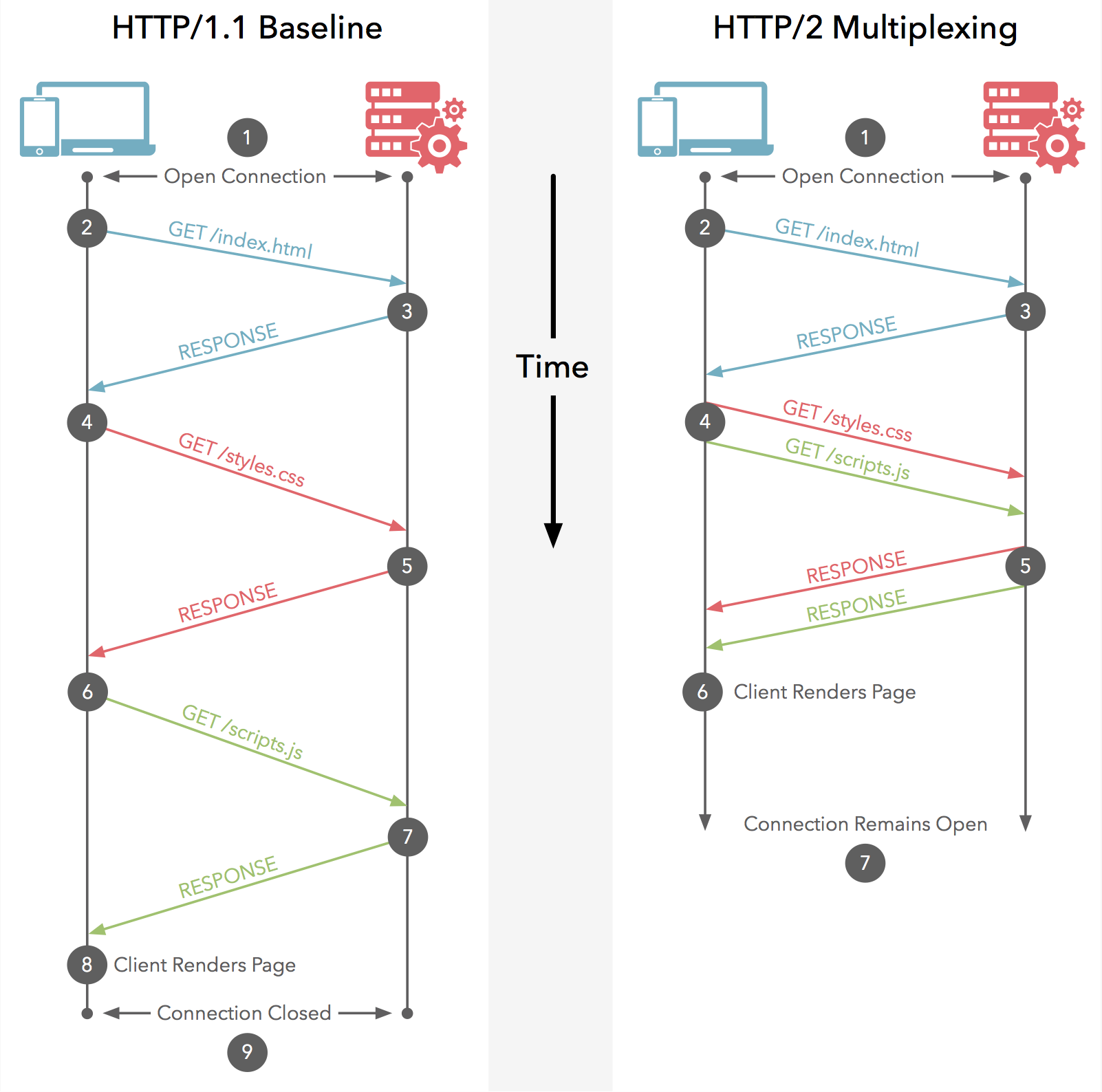
this forces clients to use a number of heuristics (often guessing) to determine what requests to put on which connection to the origin and when; since it's common for a page to load 10 times (or more) the number of available connections, this can severely impact performance, often resulting in a "waterfall" of blocked requests.
multiplexing addresses these problems by allowing multiple request and response messages to be in flight at the same time; it's even possible to intermingle parts of one message with another on the wire.
this, in turn, allows a client to use just one connection per origin to load a page.
http/2 can use one connection for parallelism
with http/1, browsers open between four and eight connections per origin. since many sites use multiple origins, this could mean that a single page load opens more than thirty connections.
one application opening so many connections simultaneously breaks a lot of the assumptions that tcp was built upon; since each connection will start a flood of data in the response, there's a real risk that buffers in the intervening network will overflow, causing a congestion event and retransmits.
you can see a demo of how http/2 is working here: https://http2.akamai.com/demo
additionally, using so many connections unfairly monopolizes network resources, "stealing" them from other, better-behaved applications (e.g., voip).
http/2 uses header compression to reduce overhead
if you assume that a page has about 80 assets (which is conservative in today's web), and each request has 1400 bytes of headers (again, not uncommon, thanks to cookies, referer, etc.), it takes at least 7-8 round trips to get the headers out "on the wire." that's not counting response time - that's just to get them out of the client.
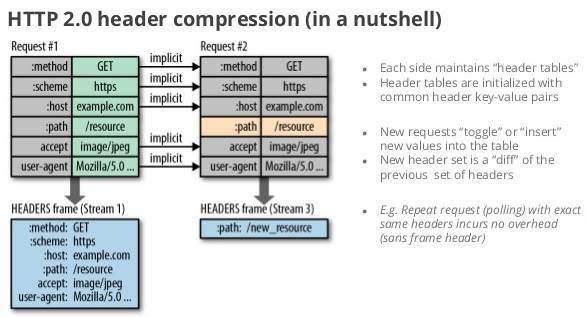
this is because of tcp's slow start mechanism , which paces packets out on new connections based on how many packets have been acknowledged - effectively limiting the number of packets that can be sent for the first few round trips.
in comparison, even a mild compression on headers allows those requests to get onto the wire within one roundtrip - perhaps even one packet.
this overhead is considerable, especially when you consider the impact upon mobile clients, which typically see round-trip latency of several hundred milliseconds, even under good conditions.
http/2 allows servers to "push" responses proactively into client caches
when a browser requests a page, the server sends the html in the response and then needs to wait for the browser to parse the html and issue requests for all of the embedded assets before it can start sending the javascript, images, and css.
server push potentially allows the server to avoid this round trip of delay by "pushing" the responses it thinks the client will need into its cache.
however, pushing responses is not "magical" - if used incorrectly, it can harm performance. for now, many are still will continue to work with webhooks .
how does this affect the existing rest apis built on http/1.1?
the main semantic of http has been retained in http/2. this means that it still has http methods such as
get
,
post
,
http headers
, and
uris
to identify resources.
what has changed in http/2 with respect to http/1.1 is the way the http semantic (e.g. "i want to put resource /foo on host domain.com") is transported over the wire. this means that rest apis built on http/1.1 will continue to work transparently as before, with no changes to be made to applications .
the web container that runs the applications will take care of translating the new wire format into the usual http semantic on behalf of the applications, and the application just sees the higher level http semantic, no matter if it was transported via http/1.1 or http/2 over the wire.
because the http/2 wire format is more efficient (in particular due to multiplexing and compression), rest apis on top of http/2 will also benefit from this.
the other major improvement present in http/2, http/2 push, targets the efficient downloading of correlated resources, and, as it's probably not useful in most rest api use cases, perhaps only the object storage like services can benefit from this (like amazon s3).
a typical requirement of http/2 is to be deployed over tls. this requires deployers to move from
http
to
https
which means buying ssl certificates from a trusted authority, etc.
thanks to simone bordet for his answer on stackoverflow ( https://stackoverflow.com/questions/31692868/rest-api-with-http-2/ )
http/2 benefits explained
among the key improvements brought by http/2 are multiplexed streams, header compression, server push, and a binary protocol instead of textual one. these and other positive changes allowed to achieve good web pages loading results, including those having lots of additional files attached to them (e.g. styles, scripts, images, fonts, etc.).
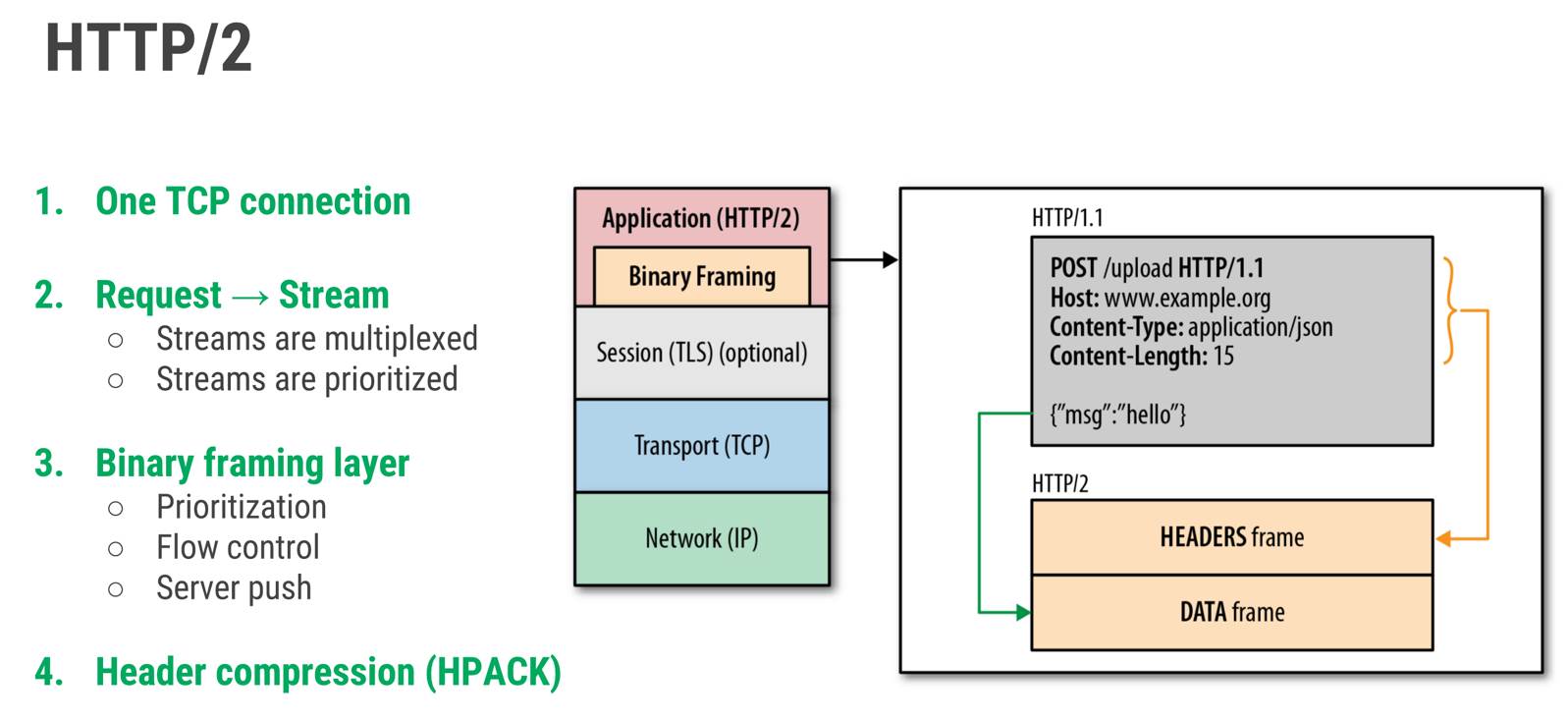
http/2, the new version of the http protocol, provides also a lot of new features for server-to-server communication:
bidirectional communication using push requests
http/2's "server push" allows a server to proactively send things to the client's cache for future use.
this helps avoid a round trip between fetching html and linked stylesheets and css, for example; the server can start sending these things right away, without waiting for the client to request them.
it's also useful for proactively updating or invalidating the client's cache, something that people have asked for.
of course, in some situations, the client doesn't want something pushed to it - usually because it already has a copy, or knows it won't use it. in these cases, it can just say "no" with rst_stream.
multiplexing within a single tcp connection
http/2 uses multiplexing to allow many messages to be interleaved together on a connection at the same time so that one large response (or one that takes a long time for the server to think about) doesn't block others.
furthermore, it adds header compression, so that the normal request and response headers don't dominate your bandwidth - even if what you're requesting is very small. that's a huge win on mobile, where getting big request headers can easily blow out the load time of a page with a lot of resources by several round trips.
long running connections
http/2 is designed to use fewer connections so servers and networks will enjoy less load. this is especially important when the network is getting congested because http/1's use of multiple connections for parallelism adds to the problem.
for example, if your phone opens up six tcp connections to each server to download a page's resources (remembering that most pages use multiple servers these days), it can very easily overload the mobile network's buffers, causing them to drop packets, triggering retransmits, and making the problem even worse.
http/2 allows the use of a single connection per host and encourages sites to consolidate their content on one host where possible.
stateful connections
if your http/1 client sends a request and then finds out it doesn't need the response, it needs to close the connection if it wants to save bandwidth; there's no safe way to recover it.
http/2 adds the rst_stream frame to allow a client to change its mind; if the browser navigates away from a page, or the user cancels a download, it can avoid having to open a new connection without wasting all of that bandwidth.
again, this is about improving perceived performance and network friendliness; by allowing clients to keep the connection alive in this common scenario, extra roundtrips and resource consumption are avoided.
but...
as always, not everything is about benefits, there are some questionable downsides:
using binary instead of text
this is also a good and a not so good feature.
one of the nice things about http/1 is the ability to open up telnet, type in a request (if the server doesn't time out!) and then look at the response. this won't be practical in http/2 because it's a binary protocol. why?
consider how can we store short int 30000 (0x7530), both as text and as binary:

as you can see, instead of using 5 bytes we are using 2 bytes. it is more than 50% size reduction.
while binary protocols have lower overhead to parse, as well as a slightly lighter network footprint, the real reason for this big change is that binary protocols are simpler and therefore less error-prone.
that's because textual protocols have to cover issues like how to delimit strings (counted? double-newline?), how to handle whitespace, extra characters, and so on. this leads to a lot of implementation complexity; in http/1, there are no fewer than three ways to tell when a message ends, along with a complex set of rules to determine which method is in use.
http/1's textual nature has also been the source of a number of security issues; because different implementations make different decisions about how to parse a message, malicious parties can wiggle their way in (e.g., with the response splitting attack).
one more reason to move away from text is that anything that looks remotely like http/1 will be processed as http/1, and when you add fundamental features like multiplexing (where associating content with the wrong message can have disastrous results), you need to make a clean break.
of course, all of this is small solace for the poor ops person who just wants to debug the protocol. that means that we'll need new tools and plenty of them to address this shortcoming; to start, wireshark already has a plug-in.
more encryption
http/2 doesn't require you to use tls (the standard form of ssl, the web's encryption layer), but its higher performance makes using encryption easier since it reduces the impact on how fast your site seems. this means that you will probably need to buy ssl certificates, renew them, etc. this is not a small amount money to spend when you are working with many microservices using rest apis.
in fact, many people believe that the only safe way to deploy the new protocol on the "open" internet is to use encryption; firefox and chrome have said that they'll only support http/2 using tls.
they have two reasons for this. one is that deploying a new version of http across the internet is hard, because a lot of "middleboxes," like proxies and firewalls, assume that http/1 won't ever change, and they can introduce interoperability and even security problems if they try to interpret an http/2 connection.
the other is that the web is an increasingly dangerous place, and using more encryption is one way to mitigate a number of threats. by using http/2 as a carrot for sites to use tls, they're hoping that the overall security of the web will improve.
summary
the real benefit to your existing rest apis will be if most of your microservices that are probably rest based are working server to server communication. in today's microservices architecture, when many microservices are talking between themselves in many ways but still using rest, http/2 can increase the speed of your workflows.
http/2 does not define a javascript api nor does it help you build your rest apis much more easily. for now, javascript clients running in a web browser can make only limited use of the new capabilities. however, for server-to-server communication, http/2 provides a lot of ways to go beyond existing rest apis.
furthermore, the downside of http/2's network friendliness is that it makes tcp congestion control more noticeable; now that browsers only use one connection per host, the initial window and packet losses are a lot more apparent.
just as http has undergone a period of scrutiny, experimentation, and evolution, it's becoming apparent that the community's attention is turning to tcp and its impact upon performance; there's already been early discussion about tweaking and even replacing tcp in the ietf.
Published at DZone with permission of Guy Levin. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments