Beyond Data Silos: Data Mesh, Game Changer for Enterprises
This article explains data mesh, a data architecture that gives more power and flexibility to data domains. It shows why data mesh is a good option for data management.
Join the DZone community and get the full member experience.
Join For FreeIn today's data-driven world, organizations are grappling with managing the ever-increasing volume of data they collect. In order to derive insights and make informed decisions, businesses must break down data silos and create a unified view of their data. This is where Data Mesh comes in - a revolutionary new approach to data architecture that is changing the game for enterprises.
What Is Data Mesh?
Data Mesh is a decentralized approach to data architecture that promotes the autonomy and scalability of data domains within an organization. It is a response to the traditional centralized data architecture, which relies on a single data platform and a centralized team to manage all data-related activities.
In a Data Mesh architecture, data is treated as a product and is owned by the domain that generates it. Each domain has its own team responsible for collecting, processing, and analyzing data. These domain teams operate autonomously and have the freedom to choose the tools and technologies that best fit their needs. The teams are also accountable for the quality and accuracy of their data.
Why Data Mesh and Why Now?
Traditional centralized data management approaches typically involve a single team or department responsible for managing all the data across an organization. This centralized team is often responsible for designing and managing a shared data architecture, defining data models, and ensuring data quality.
However, this approach can result in siloed data because each team or department has its own unique data needs and requirements. As a result, teams may create their own data sets and systems that are not integrated with the centralized data architecture. This can lead to duplication of data, inconsistencies, and errors across different data sets.
Additionally, traditional centralized approaches can lead to slow decision-making processes because data requests and analysis often need to be routed through the centralized team. This can create bottlenecks, delays, and frustration for teams who need to access data quickly to make informed decisions.
One of the main benefits of Data Mesh is that it enables organizations to scale their data infrastructure in a more efficient and effective way. With traditional centralized data architecture, scaling can become a bottleneck due to the need for a centralized team to manage everything. This can slow down data processing and limit the organization's ability to extract insights in a timely manner. Data Mesh, on the other hand, allows for independent scaling of data domains, making it easier to scale data infrastructure as the organization grows.
Data Mesh also promotes collaboration and cross-functional teams within an organization. By breaking down data silos, different teams can share data more easily and collaborate on data-related projects. This can lead to faster innovation and improved decision-making.
What Changes With Data Mesh?
Data mesh revolutionizes the landscape of analytical data management, introducing multidimensional transformations in both technical and organizational aspects. This paradigm calls for a fundamental reevaluation of assumptions, architecture, technical solutions, and social structures within organizations, reshaping how analytical data is managed, utilized, and owned.
From an organizational perspective, data mesh drives a shift away from centralized data ownership, previously held by specialized professionals managing data platform technologies. Instead, it advocates for a decentralized data ownership model, empowering business domains to assume ownership and accountability for the data they generate or utilize.
Architecturally, data mesh moves away from the conventional approach of collecting data in monolithic warehouses and lakes. Instead, it embraces a distributed mesh framework that interconnects data through standardized protocols, fostering a more agile and adaptable data ecosystem.
Technologically, data mesh departs from treating data as a byproduct of pipeline code execution. Instead, it promotes solutions that treat data and the code responsible for its maintenance as a cohesive and dynamic unit, recognizing the intrinsic relationship between the two.
Operationally, data governance undergoes a profound transformation. The traditional top-down, centralized operational model with manual interventions is replaced by a federated model, incorporating computational policies embedded in the nodes of the data mesh. This approach ensures more efficient and autonomous data governance.
At its core, data mesh redefines the value system associated with data. Rather than viewing data as a mere asset to be collected, it embraces the perspective of data as a product designed to serve and delight data users, both within and outside the organization.
Furthermore, data mesh extends its influence to the infrastructure level. It transcends the fragmented and point-to-point integration of infrastructure services, previously segregated into separate realms for data and analytics and applications and operational systems. Instead, data mesh advocates for a comprehensive and well-integrated infrastructure that caters to both operational and data systems promoting synergistic efficiency.
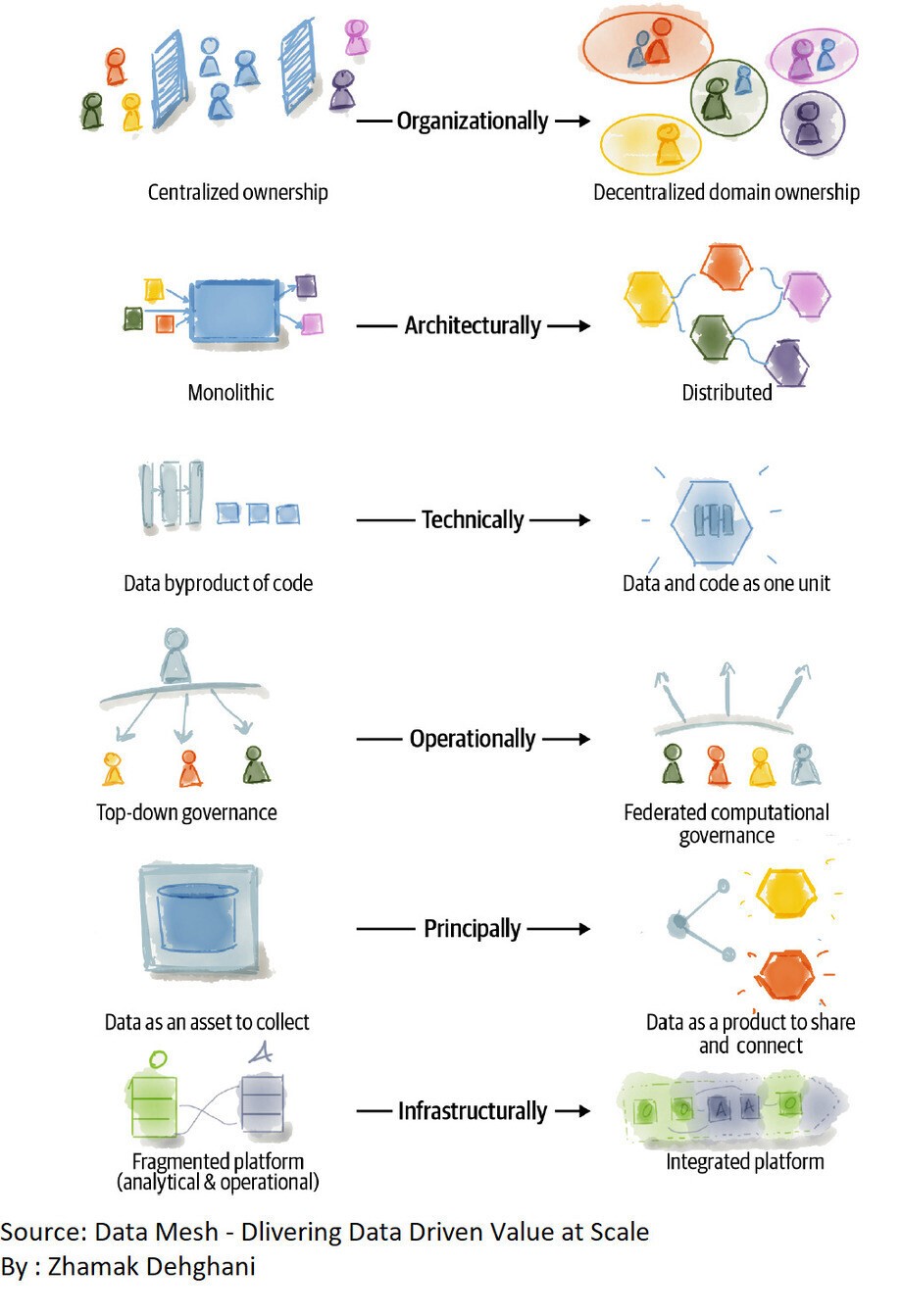
Data Mesh: What it changes
Data Mesh Building Blocks
- Domain-oriented data ownership: In Data Mesh, data ownership is decentralized and distributed across different domains or business units. Each domain has its own unique data needs and requirements and is responsible for managing its own data. This ensures that data is more aligned with business needs and can be managed more efficiently.
- Data products and services: Data Mesh treats data as a product that can be consumed by other teams and domains. Each domain is responsible for creating and managing its own data products and services, which can be consumed by other domains. This creates a more modular and scalable approach to data management.
- Federated data governance: Data Mesh decentralizes data governance, with each domain responsible for defining its own data policies and standards. However, a federated data governance model is still maintained, which ensures that data is managed consistently across domains and is compliant with relevant regulations and policies.
- Self-service data infrastructure: Data Mesh promotes a self-service approach to data infrastructure, with each domain responsible for managing its own data infrastructure needs. This includes selecting and managing relevant data storage, compute, and processing tools. This enables teams to select the tools that best fit their specific needs and requirements.
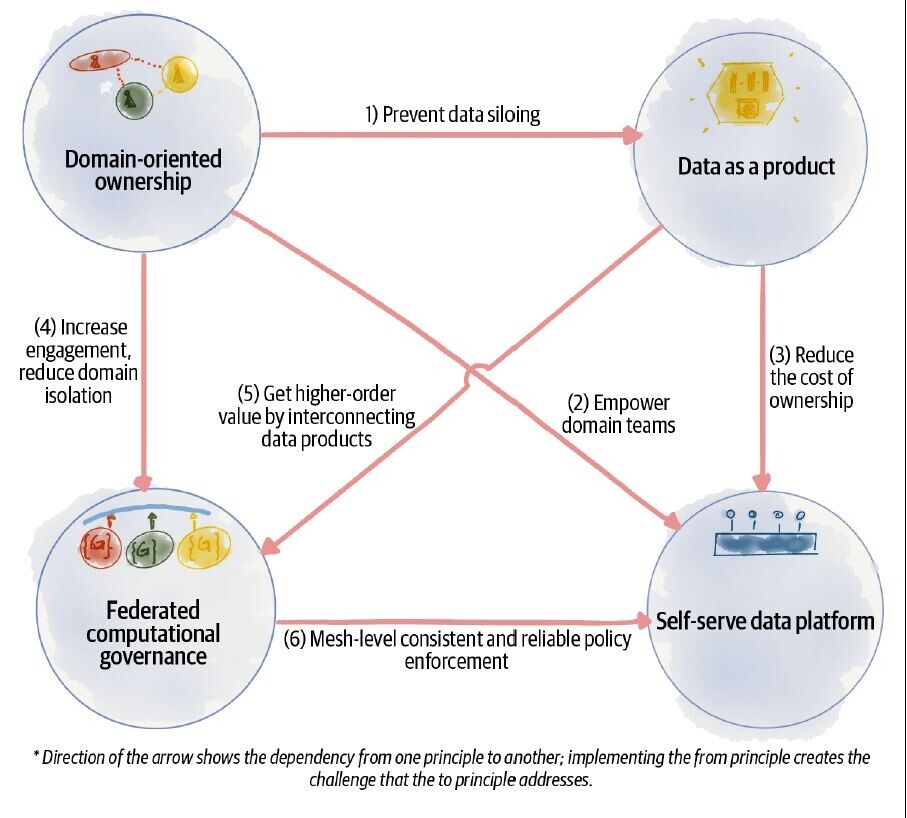
Data Mesh: Building blocks
Implementation of Data on AWS
- Identify data domains: The first step is to identify the different data domains within your organization. Each domain represents a distinct area of business focus with its own unique data needs and requirements. You can use tools such as AWS Glue to discover and catalog data assets across your organization.
- Decentralize data ownership: In Data Mesh, each domain is responsible for managing its own data. To implement this on AWS, you can use AWS Organizations to create separate accounts for each domain, with each account having its own unique set of permissions and access controls.
- Define data products and services: Each domain is responsible for creating and managing its own data products and services. To do this on AWS, you can use tools such as AWS Lambda and AWS API Gateway to create serverless APIs that expose data products and services to other domains.
- Federated data governance: Although data ownership and management are decentralized in Data Mesh, a federated data governance model is still maintained. To implement this on AWS, you can use AWS Lake Formation to define data policies and standards that are consistent across domains.
- Self-service data infrastructure: Each domain is responsible for managing its own data infrastructure needs. To implement this on AWS, you can use tools such as Amazon S3, Amazon Redshift, and Amazon EMR to create scalable and flexible data storage, compute, and processing infrastructure.
- Mesh architecture: In Data Mesh, data is managed through a mesh architecture that connects different domains and teams. To implement this on AWS, you can use AWS App Mesh to create a service mesh that connects different data products and services across domains.
Challenges of Data Mesh
While Data Mesh has many benefits, it is not without its challenges. One of the main challenges is that it requires a significant cultural shift within an organization. The domain teams must have a high level of autonomy and accountability, which may be difficult for some organizations to embrace.
Another challenge is that Data Mesh can be more complex to set up and manage compared to traditional centralized data architecture. Each domain team may have different data requirements, tools, and technologies, which can create additional complexity.
Conclusion
In summary, Data Mesh is a new approach to data architecture that is changing the game for enterprises. By promoting autonomy and scalability of data domains, Data Mesh enables organizations to scale their data infrastructure more efficiently and effectively. However, implementing a Data Mesh architecture requires a significant cultural shift and can be more complex to manage compared to traditional centralized data architecture. Despite the challenges, the benefits of Data Mesh are compelling, and organizations that embrace it are likely to be more successful in the long run.
Published at DZone with permission of Kshitiz Jain. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments