The Big Data Architecture Blueprint: Core Storage, Integration, and Governance Patterns
This comprehensive technical guide breaks down the essential architectural, storage, and integration patterns required to scale enterprise big data platforms.
Join the DZone community and get the full member experience.
Join For FreeBuilding scalable data systems often feels like navigating an endless sea of shifting paradigms. Engineers and architects are constantly forced to choose between centralizing data or distributing it, processing in batches or streaming in real time, and enforcing strict compliance or enabling rapid self-service analytics. Without a structured taxonomy, engineering teams risk building fragmented pipelines that accumulate technical debt.
The following comprehensive blueprint serves as a definitive Data Patterns and Practices Library to help you align your infrastructure with proven engineering methodologies.
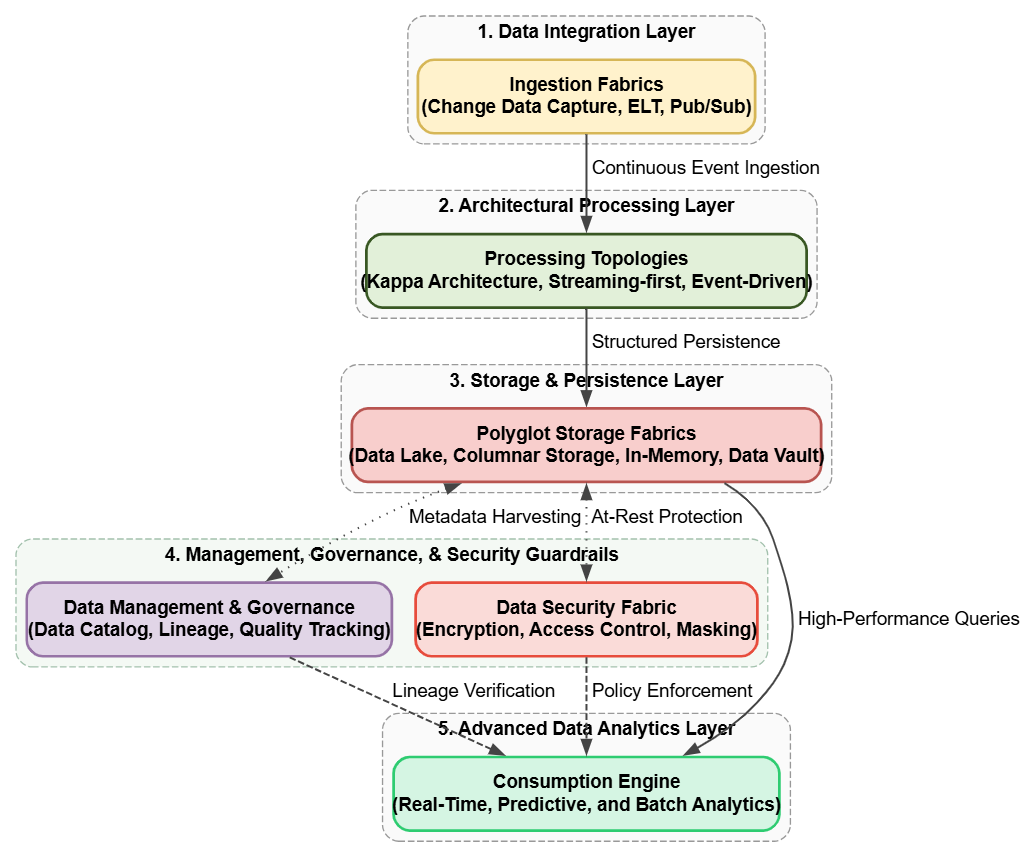
Architectural Patterns
- Data lake: A centralized repository that allows storing structured and unstructured data at any scale, enabling raw data storage for various analytics purposes.
- Data warehouse: A large, centralized repository for storing and managing structured data, optimized for high-performance analytics and reporting.
- Lambda architecture: A data processing architecture that combines batch and stream processing for fault-tolerant, scalable, and real-time data analytics.
- Kappa architecture: A data processing architecture that simplifies Lambda Architecture by only using stream processing for both real-time and historical data.
- Microservices architecture: A design approach that structures applications as a collection of small, independently deployable services, allowing for greater flexibility and scalability.
- Event-driven architecture: A software design pattern that promotes the production, detection, and reaction to events, enabling loose coupling and high scalability in distributed systems.
- Polyglot persistence architecture: A data storage strategy that uses multiple types of databases to store and manage data according to its specific needs.
- Data mesh: A decentralized approach to data architecture focusing on domain-oriented data ownership, self-serve data infrastructure, and product-oriented data delivery.
- Data vault: A hybrid data modeling and storage methodology that combines aspects of 3NF and star schema to create a scalable, flexible, and auditable solution.
- Streaming-first: An approach that prioritizes real-time data processing and analysis utilizing event streaming technologies.
Storage Patterns
- Sharding: A method of distributing data across multiple database servers to improve performance and scalability.
- Partitioning: The process of dividing a large table into smaller, more manageable pieces to improve query performance.
- Replication: The process of copying data from one database to another to ensure availability, redundancy, and load balancing.
- Federated storage: A storage architecture that integrates multiple storage systems under a unified management framework.
- Object storage: A scalable architecture that manages data as objects rather than files or blocks, providing high performance for unstructured data.
- Columnar storage: A format that stores data by column rather than row, which is particularly suited for analytics workloads.
- Time-series: A specialized storage system designed to handle time-stamped data, such as sensor data or stock prices, efficiently.
- Graph storage: A system optimized for storing and querying graph data, representing entities and their relationships in an interconnected structure.
- In-memory storage: A storage architecture that stores data in RAM instead of on disk for significantly faster processing.
- Hybrid storage: A solution that combines different storage types, such as on-premises and cloud, to optimize cost and performance.
Integration Patterns
- Extract, transform, load (ETL): A process of extracting data from source systems, transforming it, and loading it into a target system.
- Extract, load, transform (ELT): A variation of ETL where data is first loaded into the target system and then transformed using the target's processing power.
- Change data capture (CDC): A technique for capturing and processing changes in source data to enable incremental updates to target systems.
- Data federation: A technique for integrating data from disparate sources without physically moving or copying it, providing a unified view.
- Data visualization: An approach that abstracts underlying data sources, allowing users to access and manipulate data without knowing its physical location.
- Data replication: The process of copying data from one database to another to ensure data availability and redundancy.
- Data synchronization: The process of keeping data in multiple locations consistent and up-to-date by propagating changes.
- Data preparation: The process of cleaning, transforming, and enriching data to make it suitable for analysis or processing.
- Publish/subscribe: A messaging pattern that decouples data producers and consumers using an intermediary message broker.
- Request/reply pattern: A messaging pattern where a data consumer sends a request and waits for a response, allowing for synchronous communication.
Data Analytics
- Descriptive analytics: The analysis of historical data to understand past events and trends, often presented through reports or dashboards.
- Diagnostic analytics: The process of examining data to determine the causes of past events using techniques like data mining or correlations.
- Predictive analytics: The use of data, statistical algorithms, and machine learning to predict future events based on historical data.
- Prescriptive analytics: The process of recommending actions or decisions based on data analysis using optimization or simulation algorithms.
- Real-time analytics: The analysis of data as it is generated or received to provide immediate insights and rapid decision-making.
- Batch analytics: The processing and analysis of large volumes of data in batches, often scheduled at regular intervals.
- Text analytics: The process of extracting meaningful information from unstructured text using natural language processing.
- Geospatial analytics: The analysis of geographically referenced data to interpret spatial relationships and patterns.
- Sentiment analytics: A technique using NLP to determine the sentiment or emotion expressed in textual data.
- Network analytics: The analysis of network data to uncover patterns and interactions between nodes (entities) in a network.
Data Management
- Master data management (MDM): The process of creating a single, authoritative source of truth for critical business data.
- Reference data management (RDM): The practice of managing shared data (like codes or categories) used across multiple systems for consistency.
- Metadata management: The process of creating and maintaining data about data to facilitate discovery and governance.
- Data catalog: A searchable inventory of an organization's data assets, including datasets and reports.
- Data lineage: The practice of tracking the flow of data through systems, including its origin and transformations.
- Data versioning: The process of tracking and managing changes to data over time for recovery and auditing.
- Data performance: The process of documenting the origin, history, and processing of data to ensure trustworthiness and traceability.
- Data lifecycle management: A comprehensive approach to managing data from creation to archival or deletion.
- Data virtualization: A technique that abstracts underlying data sources to allow access without knowledge of physical location or structure.
- Data profiling: The process of assessing data quality by collecting statistics and identifying patterns or anomalies.
Data Governance
- Data stewardship: The practice of overseeing an organization's data to ensure quality, consistency, and compliance.
- Data quality management: The process of measuring and improving the accuracy, completeness, and consistency of data.
- Data policy management: The development and enforcement of standards and procedures that govern data use.
- Data classification: The process of categorizing data based on sensitivity or risk to implement appropriate security measures.
- Data retention and archival: Defining policies for storing and disposing of data based on legal and business requirements.
- Data privacy compliance: Ensuring data practices adhere to laws and regulations like GDPR or CCPA.
- Data lineage and provenance: Tracking the origin and flow of data through systems to ensure accuracy and compliance.
- Data cataloging and discovery: Maintaining a searchable repository that provides an inventory of an organization's data assets.
- Data risk management: Identifying and mitigating data-related risks such as breaches or corruption.
- Data ownership: Assigning accountability for data assets to specific individuals or teams to ensure proper management.
Data Security
- Data encryption: Encoding data to protect it from unauthorized access both at-rest and in-transit.
- Data masking: Obscuring sensitive data by replacing it with fictitious data to prevent exposure to unauthorized users.
- Data tokenization: Substituting sensitive data with non-sensitive tokens while still enabling some operations and analytics.
- Data access control: Defining policies that determine who can access or modify data based on roles and security requirements.
- Data auditing: Monitoring and recording data activities to detect unauthorized access or compliance violations.
- Data anonymization: Removing personally identifiable information (PII) from datasets to protect individual privacy.
- Data pseudonymization: Replacing sensitive data with artificial identifiers to reduce re-identification risk.
- Data security monitoring: Continuously analyzing systems and networks for potential security threats or breaches.
- Data activity monitoring: Continuous analysis of database transactions to detect unauthorized access or policy violations.
- Data loss prevention: Tools and practices designed to protect sensitive data from unauthorized leakage or theft.
Key Use Cases and Architectural Examples
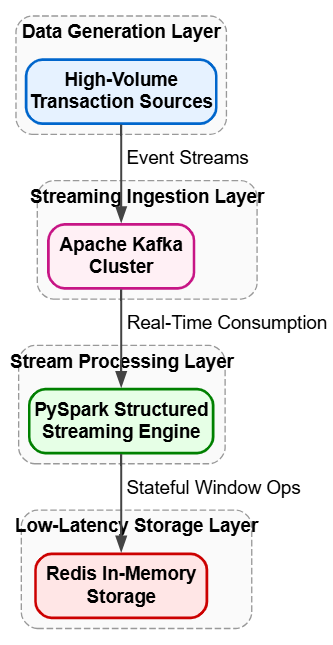
1. Real-Time Distributed Processing for High-Velocity Streams
For platforms requiring immediate analytical insights, minimizing architectural complexity while handling large-scale data streams is a primary challenge.
Core patterns: Kappa Architecture, Streaming-first, and In-Memory Storage.
Production tech stack: Apache Kafka, PySpark, Structured Streaming, and Redis.
Specific example: In a high-volume financial transaction system, implementing a Kappa Architecture simplifies the processing pipeline by routing both real-time logs and historical data events through a single stream engine. By prioritizing a streaming-first approach using an Apache Kafka cluster, the platform eliminates the complex dual-pipeline maintenance found in traditional Lambda setups.
A PySpark Structured Streaming application consumes these event streams directly, executing stateful window transformations on the fly. To achieve microsecond latency for immediate fraud lookups, the working state or frequently queried reference tables are held in an In-Memory Storage layer like Redis, ensuring rapid access speeds that disk-based alternatives cannot match.
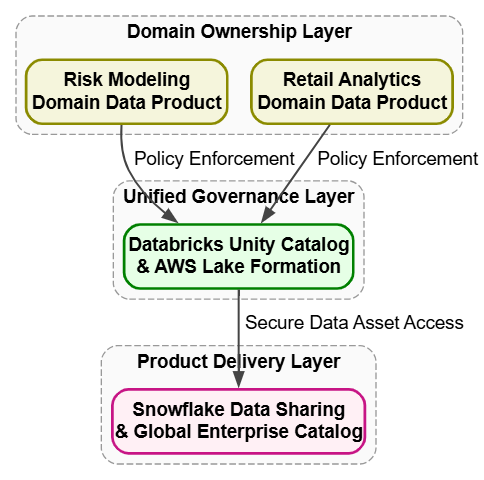
2. Decentralized Architecture for Enterprise Scaling
Large organizations often face engineering bottlenecks when a single, centralized team manages a massive monolithic data lake.
Core patterns: Data Mesh, Data Governance, and Data Cataloging and Discovery.
Production tech stack: Databricks Unity Catalog, AWS Lake Formation, and Snowflake Data Sharing.
Specific example: A multi-national banking entity transitions to a Data Mesh framework, shifting data asset ownership away from a centralized team to domain-oriented groups, such as Risk Modeling and Retail Analytics, which deliver data as independent products.
To maintain unified compliance, the infrastructure relies on strict Data Governance policies managed through Databricks Unity Catalog and AWS Lake Formation, enforcing centralized data stewardship, role-based access control, and automated data classification. These localized datasets are then securely exposed across departments via Snowflake Data Sharing. A centralized Data Catalog runs continuously on top of these endpoints, providing developers across the entire enterprise a single, searchable inventory to securely discover, audit, and consume cross-domain data products.
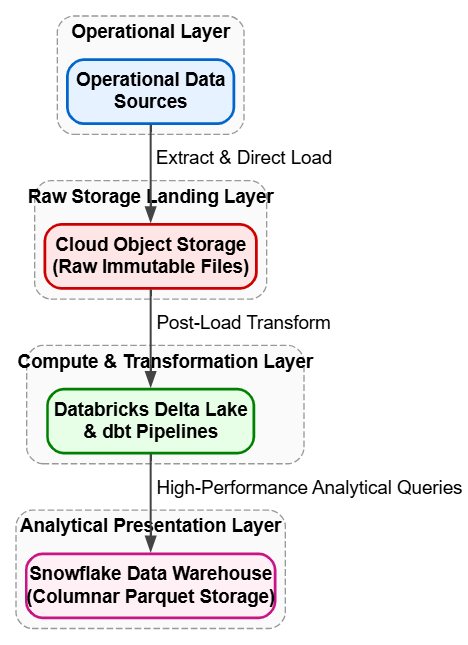
3. High-Performance Cloud Analytics and Reporting
To optimize modern cloud infrastructure, data pipelines must maximize query performance while containing compute and storage costs.
Core patterns: Extract, Load, Transform (ELT) and Columnar Storage.
Production tech stack: dbt (Data Build Tool), Delta Lake, Snowflake, and Apache Spark.
Specific example: A modern enterprise analytics platform ingests massive volumes of raw operational data into cloud object storage, choosing a flexible ELT pipeline over traditional ETL frameworks. Raw files are loaded directly into a target data platform like Snowflake or Databricks Delta Lake, leveraging cloud elasticity to execute complex transformations post-load using dbt or optimized Spark SQL queries.
To maximize business intelligence performance, the underlying files are stored using highly optimized Columnar Storage formats like Parquet. This structures data by column rather than row, ensuring that analytical queries only read the specific columns requested for a report. This optimization cuts down disk I/O operations and speeds up complex calculations across billions of historical records.
Conclusion
Successfully implementing a modern data infrastructure is never about finding a single pattern to solve every corporate challenge. True architectural maturity lies in knowing how to weave these paradigms together. By mapping tactical storage choices directly to overarching governance and integration frameworks, software architects can build resilient environments capable of evolving alongside business demands.
Which of these three architectural focus areas aligns best with your specific narrative or current production environment? Let me know in the comments below.
Opinions expressed by DZone contributors are their own.
Comments