Production-Ready Multi-Agent Systems: From Theory to Enterprise Deployment
Learn in this article why single AI agents fail and how multi-agent systems used by Uber, LinkedIn, and Klarna achieve 3x faster performance and 40% lower costs.
Join the DZone community and get the full member experience.
Join For FreeYour single AI agent is about to become obsolete. While you're debugging prompt chains, your competitors are deploying agent teams that coordinate like human organizations — achieving 40% cost reductions and 3x faster execution. This guide reveals the production patterns that separate the 20% of successful multi-agent deployments from the 80% that fail. You'll learn why the supervisor/worker pattern dominates, how evaluator agents prevent million-dollar mistakes, and what Uber, LinkedIn, and Klarna learned the hard way.
The $5.4 Billion Reality Check
Something fundamental shifted in 2024. The AI agent market exploded to $5.4 billion, with the majority of enterprises deploying multi-agent systems. But here's the uncomfortable truth: while everyone talks about agents, most implementations are elaborate prompt chains pretending to be intelligent systems.
The difference between success and expensive failure isn't the AI models—it's understanding that production multi-agent systems require completely different thinking than single-agent applications.
Consider what's actually happening in production today:
- Klarna reduced customer support resolution time by 80% using specialized agent teams
- Uber migrates entire codebases in days instead of months with coordinated agents
- LinkedIn achieves 95% accuracy in converting natural language to SQL queries
- Manufacturing giants reduce unplanned downtime by 30% through predictive agent networks
Yet Gartner predicts 40% of these projects will fail by 2027. Why? Because teams focus on agent intelligence instead of system resilience.
Why Your Single Agent Strategy Is Already Dead
Let me paint you a picture of single-agent failure. You've built an impressive AI assistant that handles customer queries. It works beautifully in demos. Then production happens:
- Monday: Your agent encounters a complex refund request requiring both policy knowledge and transaction analysis. It hallucinates a policy that doesn't exist. Cost: $10,000 in incorrect refunds.
- Tuesday: Traffic spikes. Your single agent becomes a bottleneck. Response times balloon from 2 seconds to 2 minutes. Customer satisfaction plummets.
- Wednesday: An edge case causes an infinite loop. Your agent burns through $5,000 in API costs before someone notices.
- Thursday: You try to add new capabilities. Everything breaks. You can't isolate the problem because everything runs through one agent.
- Friday: Your competitor announces their multi-agent system. It's faster, cheaper, and more reliable. Your CEO wants to know why you're behind.
This isn't hypothetical. This is happening right now across thousands of companies. The solution isn't a better prompt or a larger model — it's architectural.
The Supervisor/Worker Pattern: Why It Dominates Production
After analyzing dozens of production deployments, one pattern consistently succeeds while others fail spectacularly: supervisor/worker architecture. It's not the most sophisticated pattern, but it's the most reliable.
Think of it like a restaurant kitchen. The head chef (supervisor) doesn't cook every dish. They coordinate specialists: the saucier handles sauces, the poissonnier manages fish, and the pâtissier creates desserts. Each specialist excels in their domain. The head chef ensures everything comes together.
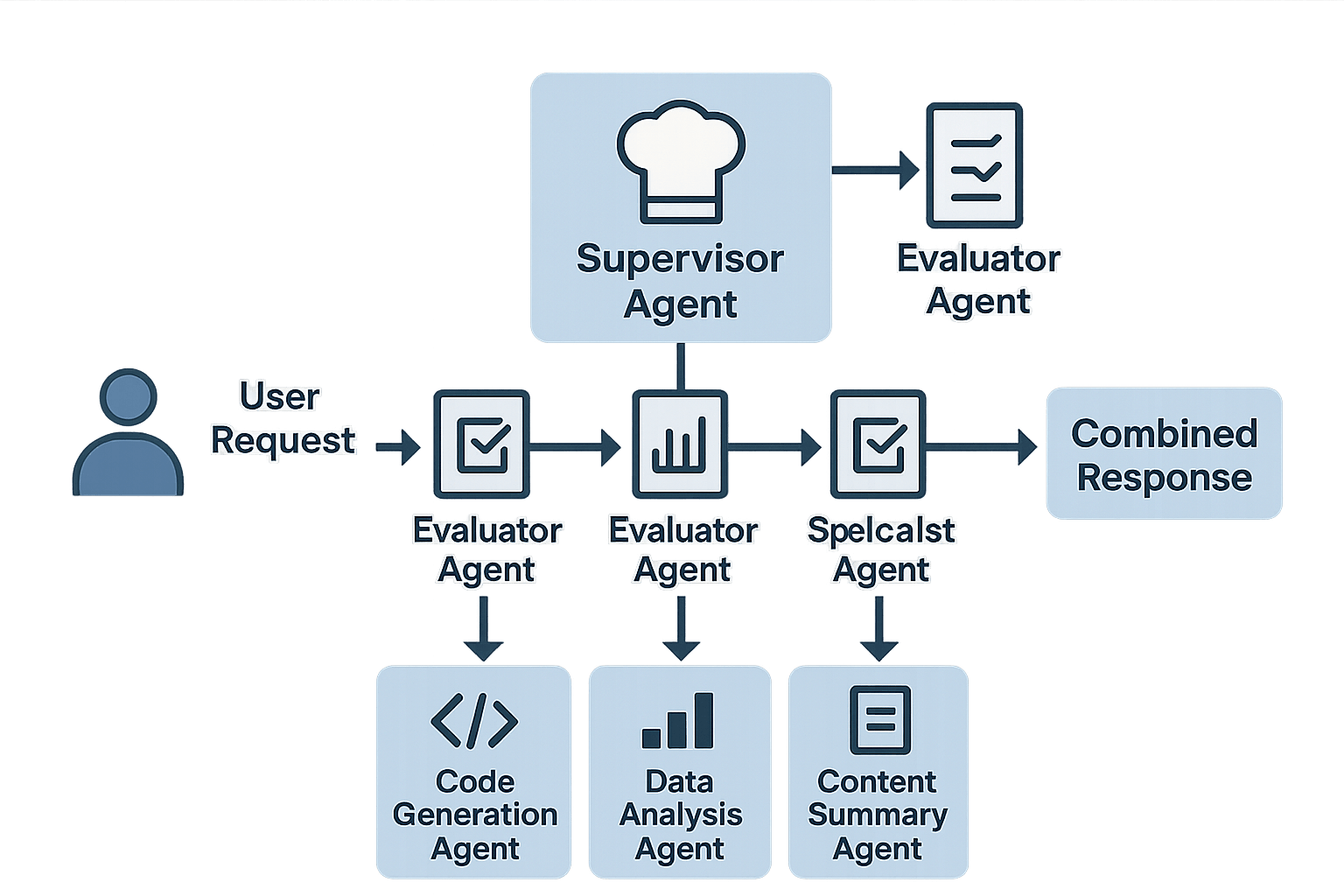
Here's what this looks like in practice:
# The surprisingly simple pattern that powers billion-dollar systems
class SupervisorAgent:
def orchestrate(self, request):
# 1. Understand the request
plan = self.analyze_request(request)
# 2. Delegate to specialists
results = []
for task in plan.tasks:
specialist = self.select_specialist(task)
result = specialist.execute(task)
# 3. Validate results (THE CRITICAL STEP)
if not self.validator.check(result):
result = self.handle_failure(task, result)
results.append(result)
# 4. Synthesize and return
return self.combine_results(results)The magic isn't in the code—it's in the separation of concerns. The supervisor never touches business logic. Specialists never make routing decisions. The validator (more on this critical component later) ensures quality gates.
The Evaluator Agent: Your Secret Weapon Against Chaos
Here's the pattern most teams miss, and it costs them millions: the evaluator agent. Also called a gatekeeper, this specialized agent has one job: to prevent chaos.
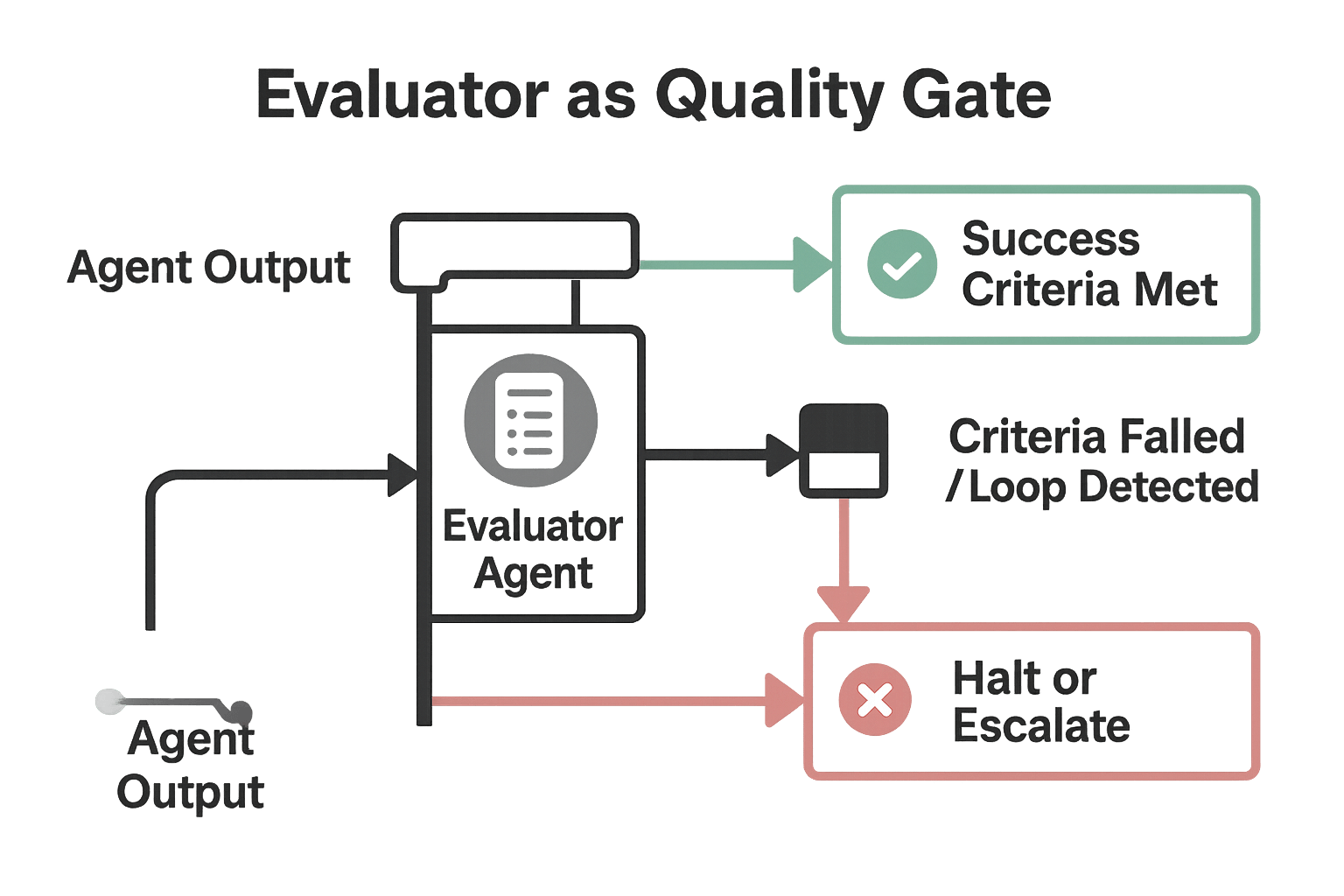
Without an evaluator, multi-agent systems develop three fatal problems:
- Infinite loops: Agent A asks Agent B for clarification. Agent B asks Agent A for context. They dance forever, burning money with each step.
- Cascade failures: One agent's bad output becomes another's input. Errors compound exponentially. A small mistake becomes a system-wide disaster.
- Success ambiguity: Agents complete tasks, but did they succeed? Without clear success criteria, you're flying blind.
The evaluator pattern is deceptively simple but incredibly powerful:
- Define explicit success criteria before execution starts
- Check every agent output against these criteria
- Halt execution when loops are detected
- Escalate when the success criteria can't be met
One Fortune 500 company reduced its error rate by 94% just by adding evaluator agents. They prevented a potential $2M loss from a runaway agent loop that would have processed incorrect financial transactions.
Framework Face-Off: LangGraph vs. AutoGen vs. CrewAI
Choosing a framework is like choosing a programming language — pick based on your problem, not the hype. Here's what actually matters:
LangGraph: When Control Is Everything
LangGraph treats your system as a state machine. Agents are nodes, communication flows are edges. You get deterministic execution and complete visibility.
Choose LangGraph when:
- You need audit trails for compliance
- Deterministic execution is non-negotiable
- You want to visualize and debug agent interactions
- Your system requires rollback capabilities
Real-world proof: Elastic uses LangGraph for security threat detection, where false positives cost millions and missed threats cost even more.
AutoGen: The Collaboration Framework
Microsoft's AutoGen excels at conversation-driven collaboration. Agents discuss, debate, and reach consensus. It's particularly strong when you need human oversight.
Choose AutoGen when:
- Agents need to negotiate solutions
- Human-in-the-loop is required
- You're already in the Microsoft ecosystem
- Complex multi-turn reasoning is core to your use case
Real-world proof: A major consultancy uses AutoGen for contract analysis, where lawyers collaborate with AI agents to review complex agreements.
CrewAI: Role-Based Simplicity
CrewAI mirrors organizational structures. You define roles, goals, and workflows. Agents understand their place in the hierarchy.
Choose CrewAI when:
- You want the fastest path to production
- Your workflow maps to human organizational patterns
- You need built-in approval chains
- Simplicity trumps flexibility
Real-world proof: A logistics company deployed CrewAI in two weeks for shipment optimization, cutting deployment time by 80% compared to custom solutions.
| Feature | LangGraph | AutoGen | CrewAI |
|---|---|---|---|
| Core Concept | State Machine (Graphs) | Conversation & Collaboration |
Organizational Hierarchy (Roles) |
| Best For | Deterministic, auditable workflows | Human-in-the-loop, negotiation |
Rapid development, role-based tasks |
| Analogy | A flowchart that executes | A committee meeting |
A company org chart |
| Strength | Control & Visibility | Flexibility & Human Oversight |
Simplicity & Speed |
The Three Pillars of Production Resilience
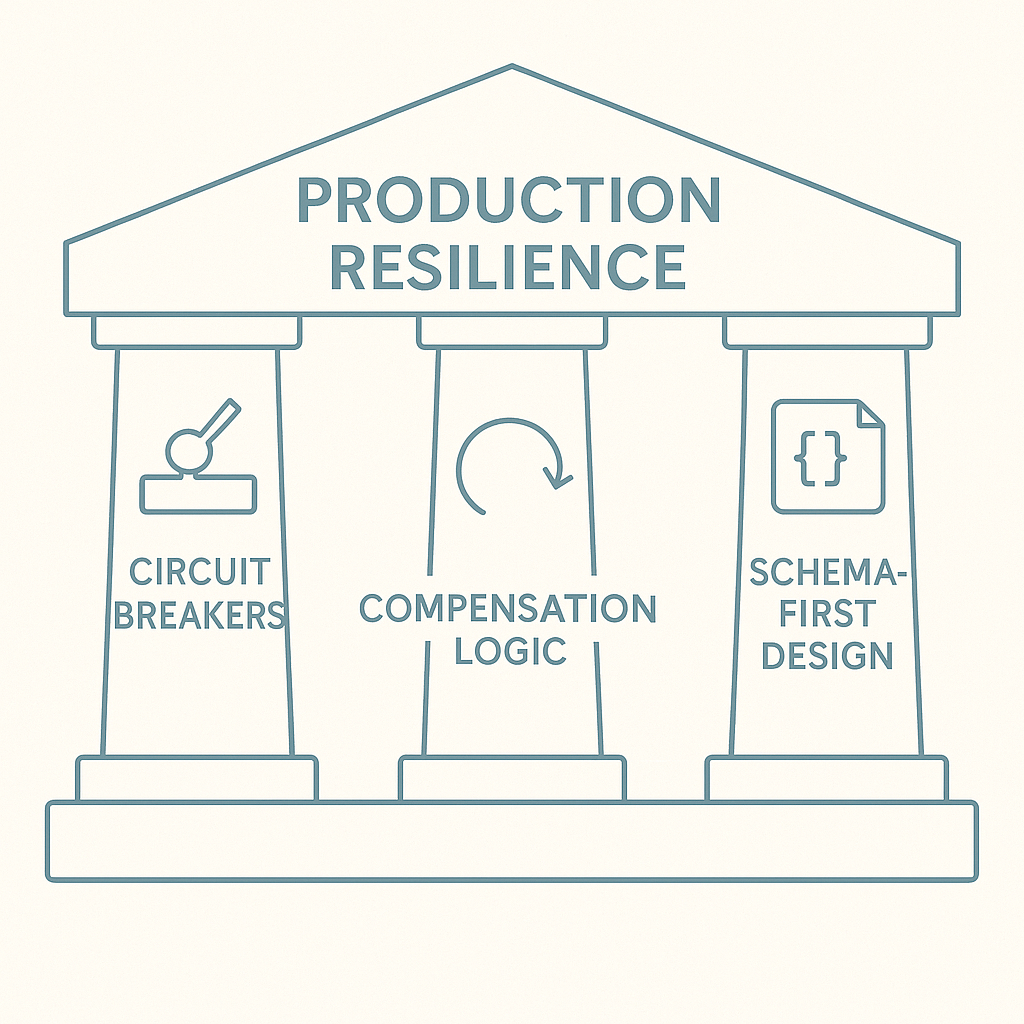
Pillar 1: Circuit Breakers That Actually Work
Circuit breakers prevent cascade failures. When an agent fails repeatedly, the circuit "opens," stopping further calls. After a cooldown period, it enters a "half-open" state for testing.
The pattern is simple, but the impact is massive. One e-commerce platform prevented a Black Friday disaster when its recommendation agent started failing. The circuit breaker isolated the failure, allowing core purchasing to continue. Revenue impact: zero instead of a potential $10M loss.
Pillar 2: Compensation Logic
Not every action can be undone, but many can be compensated for. When an agent creates a database record and then fails, compensation logic removes it. When an agent sends an email and then encounters an error, compensation logic sends a correction.
Think of compensation as "Ctrl+Z" for distributed systems. It's not perfect, but it prevents partial states that corrupt your entire system.
Pillar 3: Schema-First Design
This is where engineering discipline meets AI creativity. Every agent input and output follows a strict schema. No exceptions.
Why this matters: A financial services company lost $100K because an agent returned "1,000" instead of 1000 (note the comma). Their payment system interpreted it as a string, failed silently, and processed default amounts. Schema validation would have caught this instantly.
The Hidden Cost Killers
Token Consumption Spirals
Multi-agent systems can burn through tokens faster than a startup burns through VC funding. The multiplication effect is vicious: each agent consumes tokens, generates output that becomes another agent's input, and consumes more tokens.
The solution: Token budgets at three levels:
- Per-task budgets: No single operation exceeds limits
- Per-user budgets: Prevent individual users from consuming unfair resources
- System-wide budgets: Circuit breaker for your entire deployment
Model Selection Intelligence
Not every task needs GPT-4. A classification agent can use GPT-3.5-turbo. A summarization agent might work with Claude Haiku. Dynamic model selection can reduce costs by 70% without impacting quality.
The key insight: measure quality requirements per task type, then automatically route to the cheapest model that meets the threshold.
Caching Strategies
The most expensive API call is the one you make twice. Intelligent caching at the agent level can reduce costs by 40%. Cache validation responses, cache classification results, cache anything deterministic.
Common Failure Modes (And How to Avoid Them)
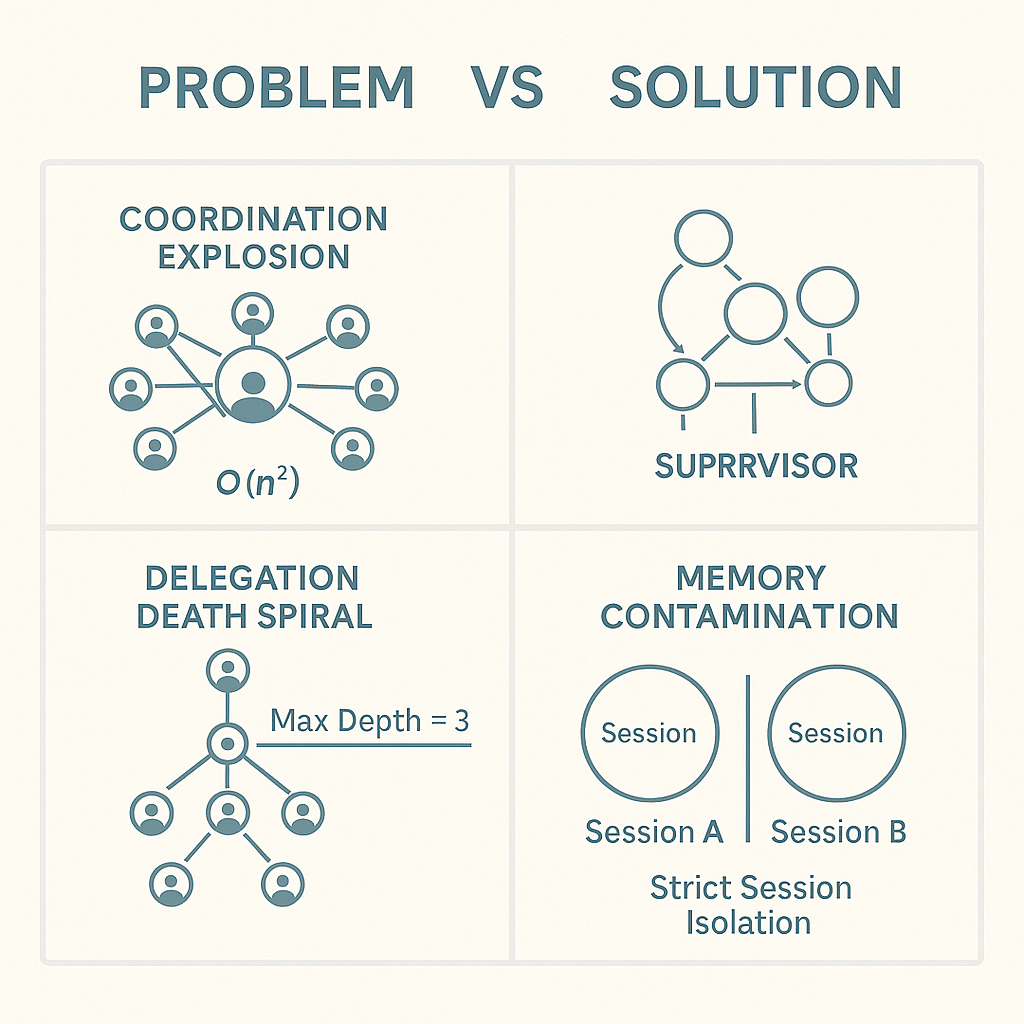
The Delegation Death Spiral
The Problem: Agents create sub-agents to handle complex tasks. Those agents create more agents. Soon, you have an exponential explosion of agents, costs, and complexity.
The Solution: Hard delegation limits. Maximum depth of 3. Maximum agents per task of 10. No exceptions. When limits are reached, escalate to humans instead of creating more agents.
Memory Contamination
The Problem: Context from User A's session leaks into User B's session. User B gets personalized recommendations based on User A's data. Privacy nightmare, potential lawsuit.
The Solution: Strict session isolation. Each user interaction gets a fresh memory context. Global knowledge is read-only. Session cleanup is mandatory, not optional.
The Coordination Explosion
The Problem: As the agent count increases, the coordination overhead grows exponentially. Ten agents require 45 potential communication paths. Twenty agents require 190.
The Solution: Hub-and-spoke architecture. Agents communicate through the supervisor, not with each other. This reduces communication paths from O(n²) to O(n).
Real-World Implementation Roadmap
Week 1: Proof of Value
Start with one workflow. Pick something painful but not critical. Implement the supervisor/worker pattern with just two specialized agents. Add basic monitoring. Measure success.
Week 2: Add Safety
Implement your evaluator agent. Add circuit breakers. Set up token budgets. Create your first compensation logic. This is where you prevent future disasters.
Month 1: Production Hardening
Deploy with canary releases — start with 5% of traffic. Add comprehensive monitoring. Implement schema validation. Set up distributed tracing. Create runbooks for common failures.
Month 2: Scale Intelligence
Add more specialized agents. Implement dynamic model selection. Optimize token usage. Add caching layers. You should see costs drop while performance improves.
Month 3: Advanced Patterns
Implement event-driven coordination for true scale. Add predictive scaling. Build self-healing capabilities. Consider multi-region deployment for global systems.
The Success Stories You Can Replicate
Uber's Codebase Migration
Challenge: Migrate millions of lines of code from deprecated frameworks.
Solution: Specialized agents for parsing, transformation, testing, and validation. The supervisor agent coordinates the pipeline.
Result: Migration time reduced from 6 months to 1 week. Accuracy improved from 85% manual migration to 99.5% automated.
Key Lesson: Specialization beats generalization every time.
LinkedIn's Natural Language to SQL
Challenge: Convert natural language queries to complex SQL across hundreds of tables.
Solution: Planner agent decomposes queries. Schema agent maps to the database structure. SQL agent generates queries. Validator ensures safety and accuracy.
Result: 95% accuracy on complex queries. 100% prevention of destructive queries.
Key Lesson: The validator agent prevented every potential data disaster.
Klarna's Customer Support Revolution
Challenge: Scale customer support without proportionally scaling human agents.
Solution: Intent classifier agent, solution retrieval agent, response generation agent, and quality assurance agent work in concert.
Result: 80% reduction in resolution time. 35% improvement in customer satisfaction. 60% reduction in cost per ticket.
Key Lesson: Multi-agent systems can exceed human performance when properly orchestrated.
Your Decision Framework
Here's how to decide if you're ready for multi-agent systems:
You're ready if:
- You have workflows with clear subtasks
- Single-agent solutions are hitting performance walls
- You need specialized expertise for different domains
- Scale and reliability matter more than simplicity
- You have an engineering discipline for monitoring and testing
You're not ready if:
- You haven't mastered single-agent patterns
- Your use case is simple, prompt-and-respond
- You lack observability infrastructure
- You can't define clear success criteria
- You're looking for magic rather than engineering
The Path Forward
Multi-agent systems aren't just an evolution of single-agent AI — they're a revolution in how we build intelligent systems. The patterns are proven. The frameworks are mature. The business value is undeniable.
But success requires more than just connecting agents together. It demands:
- Architectural thinking over prompt engineering
- Engineering discipline over AI enthusiasm
- Systematic monitoring over hope-based deployment
- Clear success criteria over vague objectives
Start with the supervisor/worker pattern. Add an evaluator agent. Implement circuit breakers. Monitor everything. Scale gradually.
The organizations winning with multi-agent systems share one trait: they treat agents as distributed systems requiring serious engineering, not as magic boxes that solve themselves.
Your competition is already building these systems. The question isn't whether you'll adopt multi-agent architectures — it's whether you'll do it right the first time or learn these lessons the expensive way.
The blueprint is here. The patterns are proven. The only thing standing between you and production-ready multi-agent systems is the decision to start building.
What workflow will you transform first?
Opinions expressed by DZone contributors are their own.
Comments