Building Real-Time Data Systems the Hard Way
In this article, explore an in-depth discussion of real-time data, real-time data services, and how this affects data validation.
Join the DZone community and get the full member experience.
Join For FreeWhat Is Real-Time Data?
Datasets are getting hard to extract information day by day. Real-time data proves to be beneficial for businesses. They use real-time data throughout the organization to derive useful information from it and extract better insights. Real-time data is helpful for monitoring and maintaining IT infrastructure. Real-time data enables businesses and organizations to get better visibility and understanding of the operation of their intricate networks.
It is crucial to have a better grip on concepts related to real-time data. These might include data velocity, the choice of processing, and an unavoidable problem of maintaining and monitoring systems for creating and consuming real-time data.
This article discusses real-time data, real-time data services, how this affects data validation, and how you can choose a solution that will lessen your expense.
Real-time data is generated and provided as it is required. It is sent for quick processing from sources, including sensors, applications, cellular devices, and social media. Examples of real-time data are telemetry readings, locating objects, and warnings or alerts when a system is not working.
One key factor of real-time data is that it is never saved in silos. The user can get the data when it is acquired. Real-time data means that the information is not withheld after it has been gathered. Today, cab drivers can get data about maps, traffic systems, and situations. Being able to access data whenever needed helps in several business activities and other analytic projects. The data transmission can vary based on factors like bandwidth and weak data infrastructure between sender and receiver.
Types of Real-Time Data
There are two types of real-time data: event data and stream data. The common feature of both these types is to process data rapidly.
1. Event Data
This type generates discrete data. The alerts are generated in predefined specific conditions, For example, a fire alarm or a vehicle accident. These single instances produce event data.
2. Stream Data
This type generates continuous data. High volumes of small-sized data have no specific starting and ending. For example, measuring water level or locating a moving object.
Building Real-Time Data Systems, the Hard Way
Developing the system is not a one-day process. It has a complete life cycle that starts from requirement gathering to deployment. Because it will be used for a long time by multiple users, there are many things that need to be kept in mind when developing a system. Every system has its scope and boundaries, so each system works differently. Some systems run offline, while some work online. Some systems work offline and online, so the mechanism, architecture, scope, and requirements for each system should not be the same as the other one. It has similarities in many features, such as profile settings, user settings, etc.
Due to the increase in shifting towards online and global interaction, which demands that data should always be actual and available online so that connectivity globally will not go down. After introducing different sensors, another demand is initiated to make these types of sensor part of the system to store hardware and other devices’ data into the system. It is observed that data is received continuously from devices, hardware, and sensors which makes the system busy processing continuous data streams and update into the system accordingly. So, users get updated results and face no delay in getting actual information. It is already a huge job for the system to receive a continuous data stream from multiple resources such as different devices, sensors, and hardware and store each data timely without creating any deadlock. But it makes it more difficult when applying processing after storing data and performing classification, transformation, cleansing, and transmitting that data to the user end without taking much time. It involves multiple types of techniques, algorithms, and methods to tackle every scenario because if anything is mishandled by the system, then the overall system goes down. As per statistics and forecast, there is an estimation of 79.4 ZB data generated in which approx. 30% use into real-time system and processing. An increase in robotics development and usage in different domains and business build an intense level of demand and supply of real-time data, application, and processing units.
Another key factor is smoothly managing the workload of the whole system either it has a continuous data stream from multiple resources or observes off-time hours where the data stream rate eventually goes down at least or idle values. For instance, currently, the automotive industry inducted robots in their production department for the assembling process of vehicles. Major activities in the production and assembling section are drilling, welding, and safety inspections which is a very hectic job nature for normal humans because of a high level of precision and time constraints. So, in replacement, humans from robots diverted the crucial workload on real-time application, data, and processing. So, the system not only receives a huge amount of data stream from robots to apply classification, cleansing, transformation, filtration, computation, and applying models on it for prediction, but the decision of safety inspections is also based on validation rules and check in such time-period so that no one part move from one side to another in elevator installed in the production and assembling section. These checks, inspections, and applying machine learning techniques for prediction and decision are not easy to handle everything into one system.
The real-time data system is the actual implementation of real-time data processing. Real-time data processing refers to the completion of a task within the shortest period with the possible outcome. The whole process always has output depending upon the data stream, so changes are reflected in the system and observed by the user; at the same time, banking transactions always have input but can’t complete their transaction till output not generated. In banking, if someone does a transaction with cash withdrawal, then the bank provides you cash till it has not deducted the same amount from your bank account. This deduction is the output of cash withdrawal in the banking scenario. Similarly, real-time data processing follows it. Real-time processing arises when the world moves to data science and big data because this huge data consume much time, and waiting for output makes the system slow down even if the system can be put on the shelf. So there is a dire need for real-time processing, which works on the input data stream and gives an output stream at the same time after successful processing.
Real-time data system, A system for future and huge volumes of data and its processing, including classification, transformation, cleansing, and transmitting results in such a short period.
Real-time data processing architecture consists of four units. The Figure illustrates the overall interaction of each component with each other in the real-time data system.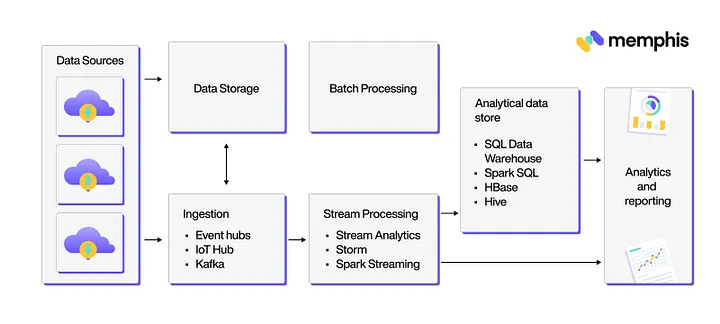
Real-Time Message Ingestion
The message Ingestion system takes input data stream from various resources, which are further processed by the Stream Processing Consumer unit. In simpler words, it acts to store new data streams, which can be a buffer for further processing.
Stream Processing
Stream processing process the data stream by applying operation as requested, such as filtration, sorting, transformation, classification, cleansing, and so on. Stream processing comes under the big data category. In stream processing, every processing data stream has time constraints that count from data source to data destination. Stream data processing consists of sub-modules that work upon parallel processing and communicate with the centralized channel. Each module has its specialties, such as one module for data capturing while another module for applying filters on data, and another module for synchronization of data from both ends, i.e., consumer and receiver ends.
Analytical Data Store
Analytical data stores can manage and store huge data streams. It mainly focuses on working big data manipulation, analytics, and optimization of large datasets so response time can be minimized as possible.
Analysis and Reporting
Analysis and Reporting focus on the actual representation of data with deep insight capabilities so that it will give more help in decision-making.
Through real-time data processing, the system can make changes in the database with a timely response to user request in terms of output; whether there is little changes or huge changes, timing will not be compromised in real-time processing. User experience increases too much high because data loading and storing are done at the same time without any wait and loss of data. In real-time processing and system, it always keeps in mind while developing a system that data transfer should be minimum and transferred when required, even when data is required. No extra data is transferred in the whole system, which causes the application performance to slow down. A real-time data-based system means whenever any user performs any activity, it will reflect the concerned person or user to take action against that activity. These reflections can be done in various manners, but the most standard technique used for this purpose is a notification that notifies the user that someone is performing this activity so that the user knows instantly and take prompt action against this activity by performing any other activity using available events or actions. Another method to do it is by using a trigger that generates another system activity against that user activity so that the user receives a notification and does whatever he wants. Another way to implement it is to maintain activity log records whenever the user performs any activity and shows user notification from activity log records accordingly. But all these methods rely upon system requirements, architecture, and platforms. Every method will not be implemented due to architecture limitations, and support such as geo-location via GPS cannot be implemented in desktop systems, so there should be another workaround for it. While building a real-time data-based system, many risks, issues, and limitations have to be faced from time to time according to system requirements, but it doesn’t mean that a real-time-based system cannot be developed. The key point is that standard practice is always a priority, but it will never be implemented in every scenario.
Tools for Using Notifications in Real-Time System
There are various tools come into the market due to extensive usage of notification in the building system. Many give the flexibility to customize system behavior according to your desire. Some of them are market leaders and are considered as introducing notification in the system by providing features of integration. Firebase FCM is a renowned notification service provider. Firebase FCM services are consumed in many applications because of the ease of integrating multiple features and online management for different systems. In contrast, others are not compatible with each type of application, platform, and architecture, such as Airship is compatible with iOS, Android, Windows, and Web, while Apple push work only for Mac-related platform. AWS SNS have different language compatibility ranges.
In developing a real-time system, the key point is that data should maintain its integrity, consistency, isolation, durability, and atomicity, which is referred to as ACID. The difference between a non-real-time system and the real-time system is that data is reflected in the system and each user side simultaneously, while in real-time, it is reflected in the overall system, including users. In a real-time system, the system looks like it will tell the user by itself that someone acts, and now you can do it or do something against that action via providing different options in terms of actions or events rather than the user check itself who performs which action and think about it that now what can I do after it. The main purpose of developing the system is to make your work and life easy, and the system should be smart to do most of the work itself rather than having the user perform it. No one has enough time to check and search what activities have been done and what things are pending. Real-time custom applications or operating systems only act as real-time systems till the whole architecture, environment, and platform should be operated in real-time. Everything depends upon the other to give real-time data, quality, and performance.
Another aspect of any system is how recovery is possible in case of any downtime or disaster. In developing any type of system, the backup and recovery in the system should always be countered so that system will go live again after performing some restoration and recovery. In a real-time system, it can be solved by a programmatic approach because it is not possible to build up from scratch in a short time. Programmatically, this can be solved by using Haskel2 features, which are renowned for rollback, recovery, and restoration of the data stream. Haskel2 works on producing aggregation. Each aggregation setup and configuration itself is a crucial job that takes a huge amount of memory to complete its operation. Now let’s take an overview of operational activities and what happens if the whole server restarts its operation either for any reason for installing new updates or restoring from accidental downtime. Everything is lost, so reinitiating every process step by step. As there is no incoming data stream and real-time processing does not take place, so reinitiating activities are performed quickly if done while running a real-time system. For this reason, many systems take snapshots of the running system at that time, which means that it takes a backup of the running system, which can help restore and recover. Some of the measures include Single Source of Truth (SSOT) and real-time data migration can be done by building data pipeline solutions that overcome data transmission issues and decrease the risk of data loss.
The real-time system consumes too much memory because of the heavy volume of data received and its manipulation. So proper memory management should be necessary to reduce the facing issues of a page fault. As page fault pause CPU utilization, computation, loading page allocation, and fetching data from disk into RAM and cache. Because of the huge volume of data, loading data from disk into memory takes a lot of time, and sometimes it is highlighted that not responding to messages. Page faults consider deadlocks which will clean all memory and heap data. So, while developing a real-time system, it should be handled and controlled by proper memory management. Dynamic memory allocation is the way to handle age fault issues, but it will badly affect system performance. Heaping techniques will freeze the memory blocks by fragmenting the memory, which reduces the performance of reading and writing operations. Another way to handle page fault problems during running systems is by building a custom real-time safe memory allocator, as the default memory allocator is not considered for the real-time system in most operating systems. Two Level Segregate Fit is one of the memory allocators in which free memory time and align operation are the foundation of the Two-Level Segregate Fit memory allocator. It builds low-level memory fragmentation, but it has its pros and cons, such as it is not safe for threading and it is based upon architecture. It has a limitation of Bytes align access. Interacting with physical devices, i.e., disk input and output operations, contain unrealistic latency in a real-time system. Normally, every system waits till physical activity is performed, so that’s why page faults are caused in many disk input and output operations. Real-time systems are unable to carry on their processing without using multithreading while developing the system. For parallel processing, it is very necessary to implement a multithreading paradigm. Any processing may not stop or block its activities while using asynchronous calls. Threading will generate another process to divide the huge job into many chunks and process them individually to speed up processing and utilize full CPU power.
Currently, everyone demands automation from the system so that system will not rely on user input. Automation in the system is only possible when the system can manage the whole data in real-time. Because any type of automation can be done based on data, if data is not reflected simultaneously, then questions will arise on automation, system data integrity, consistency, and isolation.
Use Case for Real-Time System
Let’s consider the current use case belongs to the real-time systems according to different domains and businesses. Via the real-time system, it is possible to provide strategic insights into different departments such as sales and marketing, finance and operation, customer relationship, and service to smoothly run your business routine in a timely manner. Due to real-time processing, real-time systems reduce the chances of fraud and risk of information mishandling that badly affect your whole business. In finance trading, real-time forecasting of stock rates and their rise and fall can only be possible by building a real-time system. Real-time systems will reduce the loss and risk in trading and provide actual information on stock rates and the ups and downs of the global market. The real-time system synchronizes data based on any changes made to the system so it can provide any type of data either related to news or weather. Because of it, everyone knows the current index and starting index of the day, including the end index rate. In customer relationship, service, and support, your customer enjoys and never feels hesitant to ask any query because the customer knows that response to any query acts simultaneously. From a sales and marketing point of view, marketing professionals are aware of their leads, customer queries, and customer frequency about their campaigns, so they know which audience and region should need more attention and can make a roadmap accordingly. They also approach client directly to make sales lead successful and convert a prospective client into regular one after reaching out to client in a timely and sharing an overview of products.
Tools in Real-Time System and Processing
It is the industry demand which increases the rate of research and development related to real-time systems and processing, algorithm, techniques, tools, and languages. After analyzing the growth and increased demand, multiple solutions come into the market that either help in developing real-time systems, help in real-time data processing, integrate with the system, increase optimization level and security, improve analytics and reporting, and so on. Some of these solutions have become stable, and some of them are still in the stabilization phase. Some of them directly use real-time data for integration and transformation and make business intelligence more powerful, while some give extensibility features in the form of libraries and SDKs. Each solution has its implementation mechanism, which makes differ from others, and that’s why they are still alive in the market. Some of the reliable and stable solutions are Memphis, Apache Spark, Apache Kafka, Apache Flink, Apache Kinesis, Azure Stream Analytics, Google Cloud Dataflow, RabbitMQ, and others.
Challenges in Building a Real-Time Data System and Processing
You can face some challenges while building a real-time data system and in its processing:
Huge Data – Rapid Data Intake
Consuming huge amounts of data on a real-time basis is mainly a possibility for the modern form of data. Gathering, processing, classifying, transforming, transferring, and storing is a time-taking activity that can be implemented by a data pipeline that breaks data into different chunks so that other modules start their operation whenever data arrives. Data storage capacity in bulk volume can be supported by architecture via different parallel processing algorithms.
Operational Analytics
Analytics and data visualization for business intelligence purposes is another challenge for real-time systems and processing. Because all these reports, visuals, and analyses directly utilize the main data source for business intelligence and decision making
Categories of Real-Time Data Systems
The real-time data system is categorized based on computation, time, and priority, i.e., hard real-time, soft real-time system, and firm real-time system. The real-time system is associated with two different latencies. Some of them are associated with low latency, such as autopilot makes activate changes suddenly, while high latency has a defined and scheduled approach. Latency in a real-time system is measured in terms of tasks.
Hard Real-Time System
Hard real-time systems focus on a time constraint to meet strict deadlines because in this category, if time doesn’t meet according to the deadline, it means failure of the system such as the airplane control system and sensor, space shuttle, and autopilot system.
Soft Real-Time System
Soft real-time systems have no priority of time constraints which goes towards system failure, but it is to be considered in performance aspects and quality of service because of delay in response such as audio and video system.
Firm Real-Time System
Firm real-time systems do not have strict time constraints but it makes degrade the system quality and performance. In this system, computation is also done after the deadline is over, such as in financial forecasting.
Conclusion
A real-time system is based on data and its processing techniques, mechanism, architecture, tools, algorithm, operating system, connected devices, and hardware that makes it successful in operation. Real-time inform you whenever something happens. The real-time system provides you with real-time analytics that transforms big data for operational activities and infrastructure development and improvement. Because no improvement and development is stopped, the growing process is intentionally shifted towards the end. It is not sure that real-time is the only option for business, but the right decision in choosing the right method of data processing and consuming data makes a market leader. Choosing the right method and system depends upon requirements. There are multiple alternative options available such as batch processing, scheduling, and so on. So always think beyond the boundaries.
Published at DZone with permission of Idan Asulin. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments