Challenges to Designing Data Pipelines at Scale
In this article, take an in-depth look into assessing key challenges and solutions to effective data management.
Join the DZone community and get the full member experience.
Join For FreeThis is an article from DZone's 2022 Data Pipelines Trend Report.
For more:
Read the Report
The current challenge in the world of data is no longer in the processing capacity of volumes of data. Because of the performance of modern current streaming platforms and owing to a new generation of data repositories that allow decoupling computation from the storage layer, we can improve scalability with very low operational effort.
However, if we remember the famous 5 Vs of big data (volume, value, variety, velocity, and veracity), veracity and value are still a challenge for most companies today.
Data pipelines are fundamental to solve that challenge. Designing and building data pipelines at scale not only leads to more speed but doing so is maintainable and comprehensible through whole teams.
Processing Capacity for Data Volumes
A few years ago, the main technological challenges were in the following areas:
- Data repositories (volume and velocity) – Ingesting and managing huge volumes of data.
- Data processing compute layer (velocity) – Having a high-performance compute layer to launch thousands of data pipelines that allow ingesting a huge amount of data in a very fast way.
- Integration adapters (variety) – Developing adapters to integrate with the different components.
IT teams spent years building data platforms that allowed for those capabilities before starting to develop the first data pipelines. After that, all efforts went into ingesting huge volumes of data in a short period of time. But it all happened without focusing on real business value. Additionally, operating these data platforms required huge amounts of effort.
Now, with cloud adoption, the open-source community, the latest generation of cloud software, and new data architecture patterns, implementing those features is no longer a challenge.
Data Repositories
There are multiple ways of providing a high-performance data repository to manage a huge volume of data in real time with low operational effort.
- Data warehouses – The new generation of data warehouses decouple storage from the compute layer, providing new, scalable capabilities based on different technologies, such as NoSQL, data lakes, or relational data warehouses with AI features.
- Relational databases – The latest relational databases that use sharding and in-memory features, providing OLTP and OLAP capabilities.
- Streaming platforms – Platforms such as Apache Kafka or Apache Pulsar provide the capacity to process millions of events per second and build real-time pipelines.
In this case, the key to success is to choose the best option for your use case.
Compute Layer
The following capabilities enable the execution of a large number of concurrent pipelines:
- Serverless – Cloud platforms provide easy, on-demand scaling.
- New data repositories' computation layer – Decoupling from storage allows delegating a large part of operations to be performed on the database without risking impacting other loads or scaling limitations, as with older, on-premises systems.
- Kubernetes – We can use the Kubernetes API to dynamically create job containers as Kubernetes pods.
Integration Adapters
The open-source community, together with new cloud software vendors, provides a variety of data adapters to quickly extract and load data. This simplifies the integration between different software components, such as data repositories, ERP, and many others.
Current Data Challenges
The current challenge is providing data in a more comprehensive and reliable way. Data processes are one of the main factors of complexity. As a data or business analyst, in addition to having the information at the right time, we need to know the metadata about the data we are analyzing in order to make decisions.
- What does the data mean and what value does it provide? (Value)
- How is the data calculated? (Value)
- What are the sources of the data? (Value)
- How up to date is the data? (Veracity)
- What is the quality of the data? (Veracity)
In large enterprises, there is a lot of data, but also a lot of departments that sometimes work with similar, but different, data. For example, retail companies have two kinds of stock:
- Countable stock – This stock is theoretical and based on purchase orders and delivery notes.
- Real stock – This stock represents the items they have in their warehouses and stores.
Usually, these values do not match for many reasons, such as delivery delays or other human errors. However, the stock data is the source for calculating indicators, such as sales, sales forecasts, or stock replenishment. The decision to purchase a new shipment of items based on the theoretical stock can cause thousands of dollars in losses and lead to a less sustainable world. We can only imagine the impact of these decisions on other sectors, such as healthcare.
When analysts make a decision, they need to know what data they are working with to assess the risks and make conscious choices. In the end, we are talking about transforming data into business value.
What Role Do Data Pipelines Play?
When we imagine data or read high-level articles, we visualize a very simple world with a few data domains:
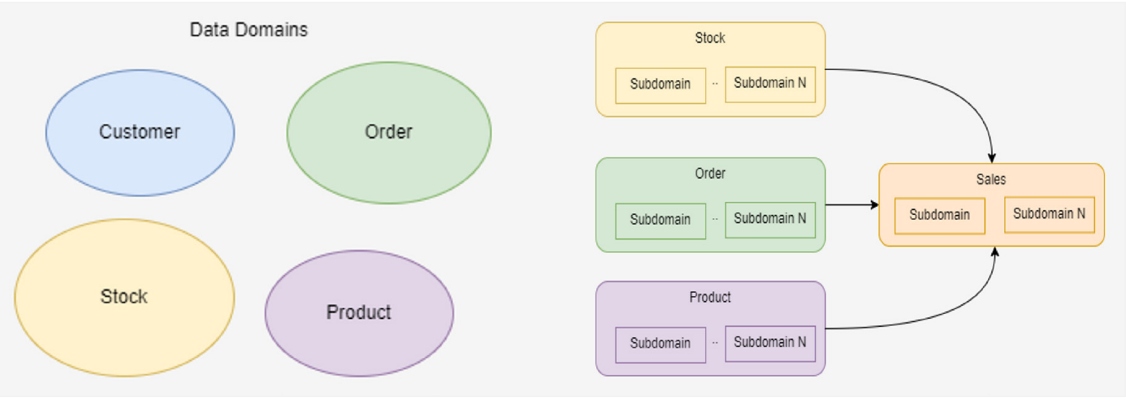
But the reality is more complex than that:
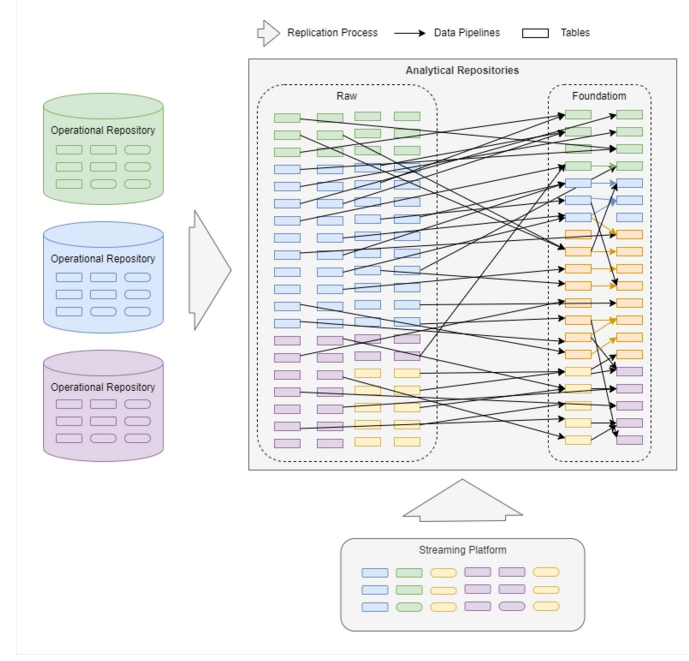
In big data scenarios, there are thousands of data pipelines at different levels that are continuously ingesting and consolidating data between data domains or data repositories. Data pipelines are among the most important components to provide a successful data platform, but it seems that, even today, we have some of the same challenges of building data pipelines at scale that we did many years ago, including:
- Providing metadata, such as the data lineage, in a dynamic and agile way
- Enabling easy collaboration between data analysts, data engineers, and business stakeholders
- Providing information to data analysts and stakeholders about data quality and freshness easily

What Is the Challenge of Building Data Pipelines at Scale?
It seems the goals of data pipelines are focused on four main areas:
- Team collaboration and comprehension
- Dynamic data lineage
- Observability
- Data quality
Team Collaboration and Comprehension
The rules change quickly, and companies have to adapt fast. Data and information are more important than ever.
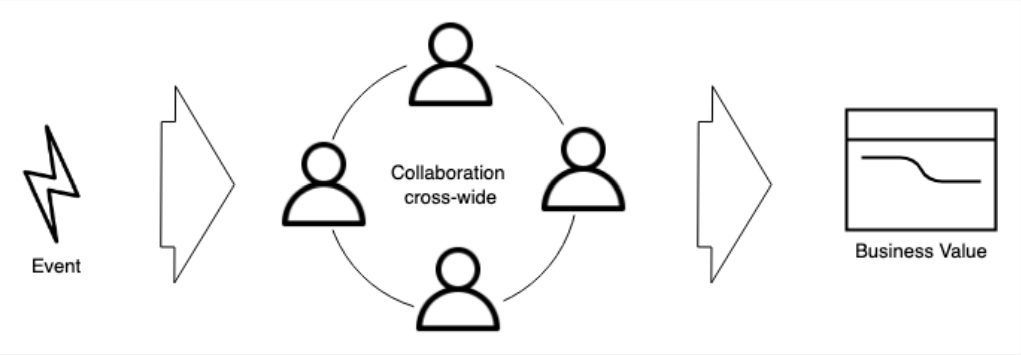
To provide value quickly, we need a heterogeneous team composed of data scientists, data engineers, analysts, and business stakeholders working together. They need to talk a similar language to be agile. When all our data pipelines are built with technologies such as Spark or Kafka streams, it is too complex to have agile communication between technical and non-technical people.
The journey from data to information starts with data pipelines.
Data Lineage
Metadata is important to allow the transformation of the data into business information. It provides a summary lineage accessible to everyone, increasing visibility, comprehension, and confidence in the data. We have to provide this information dynamically and not through static documentation that never changes or a complex inspection process that never ends.
Observability
The observability of data pipelines is a major challenge. Usually, observability is oriented toward technical teams, but we need to raise this visibility to all stakeholders (business analysts, data analysts, data scientists, etc.).
Data Quality
We need to evolve how we work with data and start applying the best practices of traditional software development. From data to Data as Code, we can use methodologies such as version control, continuous integration, or testing.
How Are Data Pipelines Evolving?
When we observe new data trends, we can see initiatives in the open-source community or startups with commercial software, such as Airbyte, Meltano, dbt-labs, DataHub, or OpenLineage.
These examples show how the world of data processing is evolving to:
- Take advantage of new data repository enhancements and move from an ETL (extract, transform, load) to an ELT (extract, load, transform) model
- Provide capabilities to manage Data as Code
- Improve data comprehension and observability
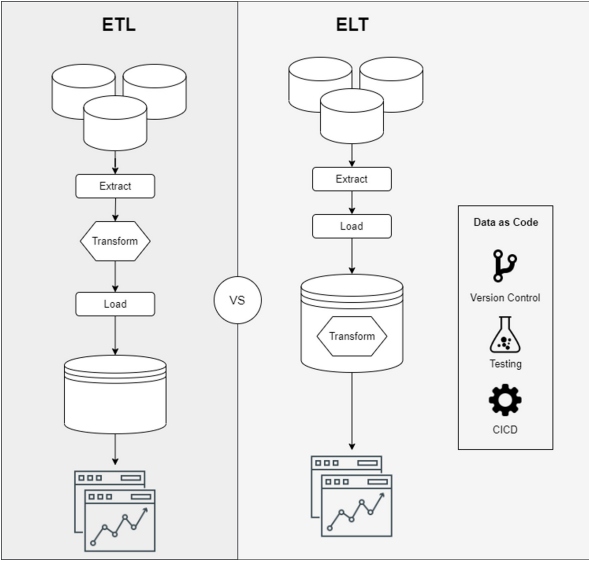
These capabilities are the keys that will allow us to build data pipelines at scale while also providing business value.
The Journey From Data Preparation to Data Comprehension
Comprehension is the first step to convert data into information. The transformation layer plays a key role in this process. Usually, the transformation layer is the bottleneck because data engineers and business analysts do not talk the same language, so collaborating is complex. However, new tools such as dbt are trying to improve that.
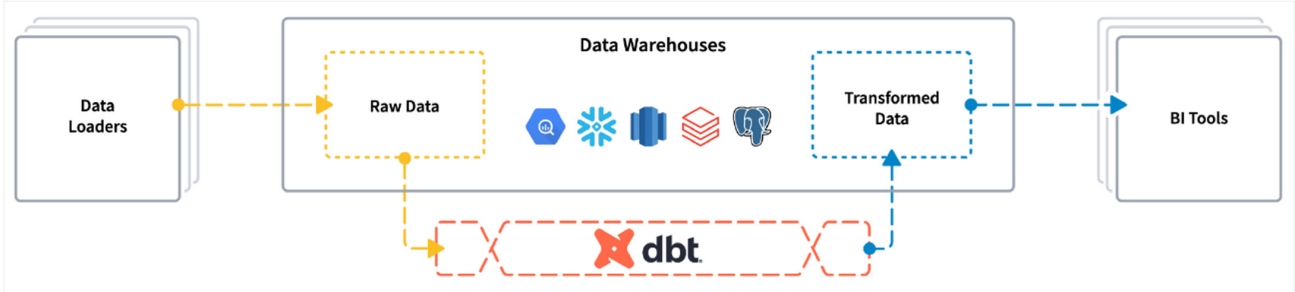
What Is dbt?
dbt (data build tool) is an open-source CLI tool for the transformation layer that enables collaboration between business data analysts and engineers during the data lifecycle using a common language as well as software development best practices, such as version control, continuous integration/deployment, and continuous testing.
Common Language Company-Wide
SQL is a common language throughout companies that allows all stakeholders to engage in discussion throughout the entire data lifecycle. SQL enables data and business analysts to collaborate on writing or modifying transformation through SQL statements using version control tools.
ELT
The world of data has changed a lot. Right now, most data repositories are performant and scalable. New scenarios have changed the rules of the transformation process. In many cases, data repositories are better suited for the work than external processes. dbt performs the transformation of the ELT process, taking advantage of new data repositories’ features and running data transformation queries inside your data warehouse.
Data as Code
dbt allows managing data transformation as code in your Git repository and applying continuous integration best practices. It provides testing capabilities to include unit testing modules based on SQL queries or extending them with macros to increase coverage in more complex scenarios.
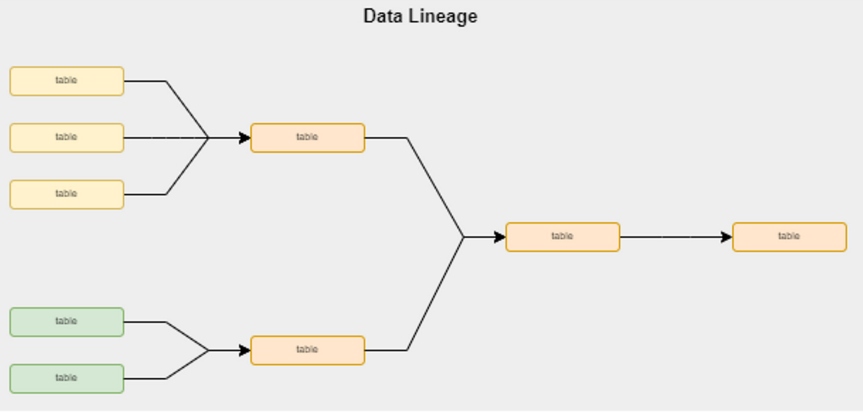
Lineage and Metadata
dbt allows us to generate data lineages and metadata dynamically in each run of data transformations. There are many integrations with platforms, such as DataHub or OpenLineage, that provide enterprise visibility.
Conclusion
In recent years, a great deal of effort has been put into improving data processing performance and ingestion capacity, but quality and comprehension are still problematic areas that make decision-making difficult. It doesn't matter if we receive a lot of data very quickly if we don't understand it, or the data is of poor quality. Having a layer of data pipelines that is scalable, maintainable, and comprehensible is a must in order to provide information that adds business value.
Remember: Not making a decision is better than making a decision based on inaccurate data — especially when you are not aware that the data is wrong.
This is an article from DZone's 2022 Data Pipelines Trend Report.
For more:
Read the Report
Opinions expressed by DZone contributors are their own.
Comments