What Is Reverse ETL? Overview, Use Cases, and Key Benefits
Looking to go beyond traditional analytics? Reverse ETL is a nuanced process for businesses aiming to leverage data warehouses and other data platforms.
Join the DZone community and get the full member experience.
Join For FreeIn the evolving landscape of data engineering, reverse ETL has emerged as a pivotal process for businesses aiming to leverage their data warehouses and other data platforms beyond traditional analytics. Reverse ETL, or “Extract, Transform, Load” in reverse, is the process of moving data from a centralized data warehouse or data lake to operational systems and applications within your data pipeline. This enables businesses to operationalize their analytics, making data actionable by feeding it back into the daily workflows and systems that need it most.
Enroll in Free Course: Data Models & Pipelines*
*Affiliate link. See Terms of Use.
How Does Reverse ETL Work?
Reverse ETL can be visualized as a cycle that begins with data aggregated in a data warehouse. The data is then extracted, transformed (to fit the operational systems' requirements), and finally loaded into various business applications such as a CRM, marketing platforms, or other customer support tools. These concepts can be further explored in this resource on the key components of a data pipeline.
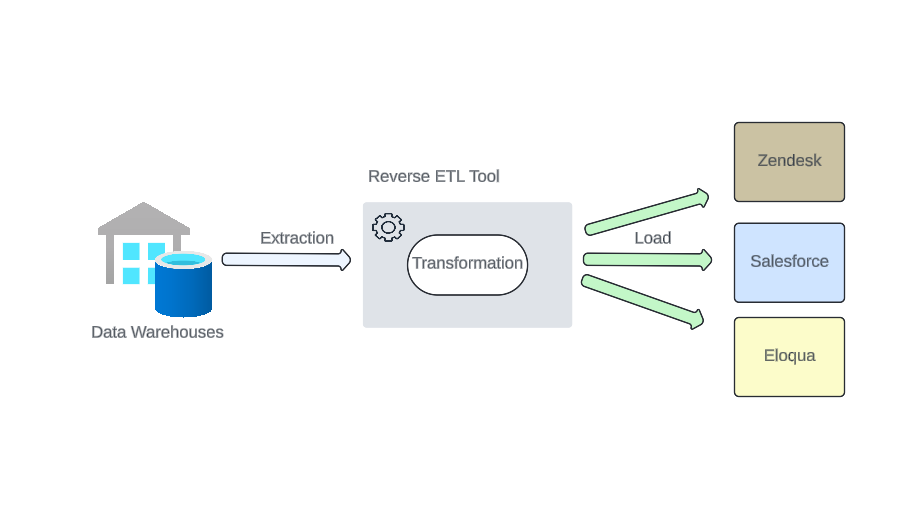
Key Components of Reverse ETL
To effectively implement reverse ETL, it's essential to understand its foundational elements. Each component plays a specific role in ensuring that the data flows smoothly from the data warehouse to operational systems, maintaining integrity and timeliness. Here's a closer look at the key components that make reverse ETL an indispensable part of modern data architecture.
- Connectors: Connectors are the bridges between the data warehouse and target applications. They are responsible for the secure and efficient transfer of data.
- Transformers: Transformers modify the data into the appropriate format or structure required by the target systems, ensuring compatibility and maintaining data integrity.
- Loaders: Loaders are responsible for inserting the transformed data into the target applications, completing the cycle of data utilization.
- Data quality: Data quality is paramount in reverse ETL as it ensures that the data being utilized in operational systems is accurate, consistent, and trustworthy. Without high-quality data, business decisions made based on this data could be flawed, leading to potential losses and inefficiencies.
- Scheduling: Scheduling is crucial for the timeliness of data in operational systems. It ensures that the reverse ETL process runs at optimal times to update the target systems with the latest data, which is essential for maintaining real-time or near-real-time data synchronization across the business.
Evolution of Data Management and ETL
The landscape of data management has undergone significant transformation over the years, evolving to meet the ever-growing demands for accessibility, speed, and intelligence in data handling. ETL processes have been at the core of this evolution, enabling businesses to consolidate and prepare data for strategic analysis and decision-making.
Understanding Traditional ETL
Traditional ETL (Extract, Transform, Load) is a foundational process in data warehousing that involves three key steps:
- Extract: Data is collected from various operational systems, such as transactional databases, CRM systems, and other business applications.
- Transform: The extracted data is cleansed, enriched, and reformatted to fit the schema and requirements of the data warehouse. This step may involve sorting, summarizing, deduplicating, and validating to ensure the data is consistent and ready for analysis.
- Load: The transformed data is then loaded into the data warehouse, where it is stored and made available for querying and analysis.
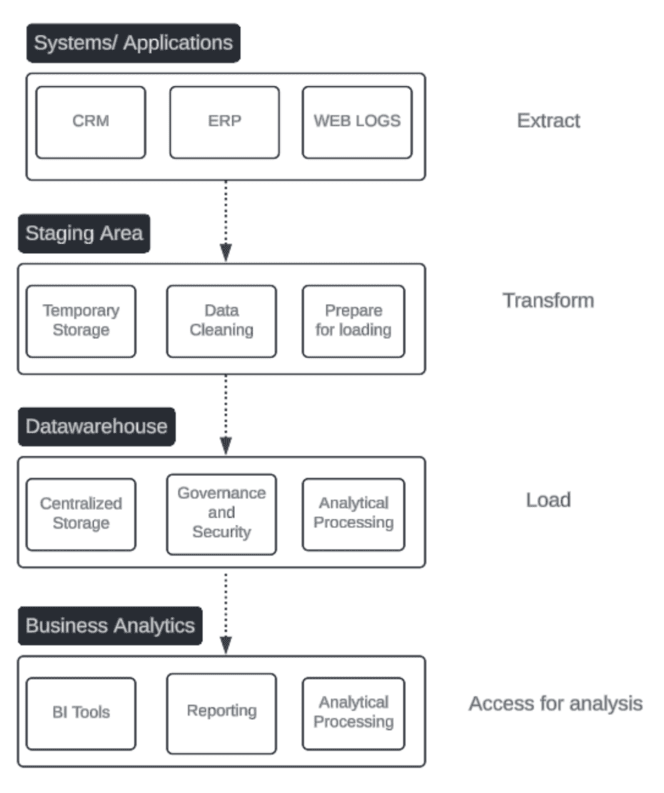
Challenges With Traditional ETL
Traditional ETL has been a staple in data processing and analytics for many years; however, it presents several challenges that can hinder an organization's ability to access and utilize data efficiently, specifically:
Data Accessibility
Efficient data access is crucial for timely decision-making, yet traditional ETL can create barriers that impede this flow, such as:
- Data silos: Traditional ETL processes often lead to data silos where information is locked away in the data warehouse, making it less accessible for operational use.
- Limited integration: Integration of new data sources and operational systems can be complex and time-consuming, leading to difficulties in accessing a holistic view of the data landscape.
- Data governance: While governance is necessary, it can also introduce access controls that, if overly restrictive, limit timely data accessibility for users and systems that need it.
Latency
The agility of data-driven operations hinges on the promptness of data delivery, but traditional ETL processes can introduce delays that affect the currency of data insights, exemplified by:
- Batch processing: ETL processes are typically batch-based, running during off-peak hours. This means that data can be outdated by the time it's available in the data warehouse for operational systems, reporting, and analysis.
- Heavy processing loads: Transformation processes can be resource-intensive, leading to delays especially when managing large volumes of data.
- Pipeline complexity: Complex data pipelines with numerous sources and transformation steps can increase the time it takes to process and load data.
An Introduction to Reverse ETL
Reverse ETL emerged as organizations began to recognize the need to not only make decisions based on their data but to operationalize these insights directly within their business applications. The traditional ETL process focused on aggregating data from operational systems into a central data warehouse for analysis. However, as the analytics matured, the insights derived from this data needed to be put into action; this birthed the differing methods for data transformation based on use case: ETL vs. ELT vs. Reverse ETL.
The next evolutionary step was to find a way to move the data and insights from the data warehouse back into the operational systems — effectively turning these insights into direct business outcomes. Reverse ETL was the answer to this, creating a feedback loop from the data warehouse to operational systems.
By transforming the data already aggregated, processed, and enriched within the data warehouse and then loading it back into operational tools (the "reverse" of ETL), organizations can enrich their operational systems with valuable, timely insights, thus complementing the traditional data analytics lifecycle.
Benefits of Reverse ETL
As part of the evolution of traditional ETL, reverse ETL presented two key advantages:
- Data accessibility: With Reverse ETL, data housed in a data warehouse can be transformed and seamlessly merged back into day-to-day business tools, breaking down silos and making data more accessible across the organization.
- Real-time data synchronization: By moving data closer to the point of action, operational systems get updated with the most relevant, actionable insights, often in near-real-time, enhancing decision-making processes.
Common Challenges of Reverse ETL
Despite the key benefits of reverse ETL, there are several common challenges to consider:
- Data consistency and quality: Ensuring the data remains consistent and high-quality as it moves back into varied operational systems requires rigorous checks and ongoing maintenance.
- Performance impact on operational systems: Introducing additional data loads to operational systems can impact their performance, which must be carefully managed to avoid disruption to business processes.
- Security and regulatory compliance: Moving data out of the data warehouse raises concerns about security and compliance, especially when dealing with sensitive or regulated data.
Understanding these challenges and benefits helps organizations effectively integrate reverse ETL into their data-driven workflow, enriching operational systems with valuable insights and enabling more informed decisions across the entire business.
Reverse ETL Use Cases and Applications
Reverse ETL unlocks the potential of data warehouses by bringing analytical insights directly into the operational tools that businesses use every day. Here are some of the most impactful ways that reverse ETL is being applied across various business functions:
- Customer Relationship Management (CRM): Reverse ETL tools transform and sync demographic and behavioral data from the data warehouse into CRM systems, providing sales teams with enriched customer profiles for improved engagement strategies.
- Marketing automation: Utilize reverse ETL's transformation features to tailor customer segments based on data warehouse insights and sync them with marketing platforms, enabling targeted campaigns and in-depth performance reporting.
- Customer support: Transform and integrate product usage patterns and customer feedback from the data warehouse into support tools, equipping agents with actionable data to personalize customer interactions.
- Product development: Usage-driven development that leverages reverse ETL to transform and feed feature interaction data back into product management tools, guiding the development of features that align with user engagement and preferences.
In each of these use cases, reverse ETL tools not only move data but also apply necessary transformations to ensure that the data fits the operational context of the target systems, enhancing the utility and applicability of the insights provided.
Five Factors to Consider Before Implementing Reverse ETL
When considering the implementation of reverse ETL at your organization, it's important to evaluate several factors that can impact the success and efficiency of the process. Here are some key considerations:
1. Data Volume
Assess the volume of data that will be moved to ensure that the reverse ETL tool can handle the load without performance degradation. Determine the data throughput needs, considering peak times and whether the tool can process large batches of data efficiently.
2. Data Integration Complexity
Consider the variety of data sources, target systems, and whether the reverse ETL tool supports all necessary connectors. Evaluate the complexity of the data transformations required and whether the tool provides the necessary functionality to implement these transformations easily.
3. Scalability
Ensure that the reverse ETL solution can scale with your business needs, handling increased data loads and additional systems over time.
4. Application Deployment and Maintenance
- Verify that the tool is accessible through preferred web browsers like Chrome and Safari.
- Determine whether the tool can be cloud-hosted or self-hosted, and understand the hosting preferences of your enterprise customers (on-prem vs. cloud).
- Look for built-in integration with version control systems like GitHub for detecting and applying configuration changes.
5. Security
When implementing reverse ETL, ensure robust security by confirming the tool's adherence to SLAs with uptime monitoring, a clear process for regular updates and patches, and compliance with data protection standards like GDPR. Additionally, verify the tool's capability for data tokenization, encryption standards for data-at-rest, and possession of key certifications like SOC 2 Type 2 and EU/US Privacy Shield.
By summarizing these factors, organizations can ensure that the reverse ETL tool they select not only meets their data processing needs but also aligns with their technical infrastructure, security standards, and regulatory compliance requirements.
Reverse ETL Best Practices
To maximize the benefits of reverse ETL, it's essential to adhere to best practices that ensure the process is efficient, secure, and scalable. These practices lay the groundwork for a robust data infrastructure:
- Data governance: Establish clear data governance policies to maintain data quality and compliance throughout the reverse ETL process.
- Monitoring and alerting: Implement comprehensive monitoring and alerting to quickly identify and resolve issues with data pipelines.
- Scalability and performance: Design reverse ETL workflows with scalability in mind to accommodate future growth and ensure that they do not negatively impact the performance of source or target systems.
Top Three Reverse ETL Tools
Choosing the right reverse ETL tool is crucial for success. Here's a brief overview of three popular platforms:
- Hightouch: A platform that specializes in syncing data from data warehouses directly to business tools, offering a wide range of integrations and a user-friendly interface.
- Census: Known for its strong integration capabilities, Census allows businesses to operationalize their data warehouse content across their operational systems.
- Segment: Known for its customer data platform (CDP), Segment provides Reverse ETL features that allow businesses to use their customer data in marketing, sales, and customer service applications effectively.
To help select the most suitable reverse ETL tool for your organization's needs, here's a comparison table that highlights key features and differences between example solutions:
|
Reverse ETL Tool Comparison |
|||
|
Feature |
Hightouch |
Census |
Segment |
|
Core Offering |
Reverse ETL |
Reverse ETL |
CDP + limited reverse ETL |
|
Connectors |
Extensive |
Broad |
Broad |
|
Custom Connector |
Yes |
Yes |
Yes |
|
Real-Time Sync |
Yes |
Yes |
Yes |
|
Transformation Layer |
Yes |
Yes |
Only available on customer data |
|
Security & Compliance |
Strong |
Strong |
Strong |
|
Pricing Model |
Rows-based |
Fields-based |
Tiered |
Bottom Line: Is Reverse ETL Right for Your Business?
Reverse ETL can be a game-changer for businesses looking to leverage their data warehouse insights in operational systems and workflows. If your organization requires real-time data access, enhanced customer experiences, or more personalized marketing efforts, reverse ETL could be the right solution. However, it's essential to consider factors such as data volume, integration complexity, and security requirements to ensure that a reverse ETL tool aligns with your business objectives and technical requirements.
Opinions expressed by DZone contributors are their own.
Comments