Chat Completion Models vs OpenAI Assistance API
In this article, you will learn the key differences between chat completion (like those provided via the Chat Completions endpoint) and OpenAI's Assistance API.
Join the DZone community and get the full member experience.
Join For FreeIn this blog, we are going to explore some key differences between chat completion models (like those provided via the Chat Completions endpoint) and the more advanced OpenAI Assistance API. We will break down how these two approaches handle messages, conversation history, large documents, coding tasks, context window limits, and more. We will also look at how the Assistance API provides additional tools — such as code interpreters, document retrieval, and function calling — that overcome many limitations of chat completions.
Understanding Chat Completion Models
- You send a list of messages to the model.
- The model generates a response.
- You receive the response as output.
Example Flow of Chat Completions
You ask: “What’s the capital of Japan?”
- The model responds: “The capital of Japan is Tokyo.”
Then, you ask: “Tell me something about the city.”
- The model says it has no context and doesn’t know which city you mean because it does not inherently keep track of message history in the same conversation state.
Limitations of Chat Completion Models
1. No Persistent Message History
One drawback is the lack of message history. In chat completions, the model doesn’t automatically remember previous messages. For example, if you first ask, “What’s the capital of Japan?” and then simply say, “Tell me something about the city,” the model often cannot reference the city’s name unless you manually provide it again.
2. No Direct Document Handling
Chat completion models also do not directly support handling large documents. If you have a 500-page PDF and want to query something like, “How much profit margin did my company make in Q1 2023?” you would need a process called retrieval-augmented generation (RAG). This involves:
- Converting the document into text
- Splitting it into smaller chunks
- Converting those chunks to embeddings
- Storing them in a vector database
- Retrieving the relevant chunks at query time, then passing them as context to the model
3. Challenges With Coding Tasks
Another issue is handling computational tasks. If you ask chat completions to do something like reversing a string, the model might generate a wrong or incomplete answer. For instance:
# Example question to a Chat Completion model
reverse("Subscribetotalib")
# Hypothetical incorrect output
# "bilattoebircsubs"It may also give incorrect or outdated information about the current date, since it lacks real-time computational capabilities.
4. Limited Context Window
Chat completion models have a fixed maximum token limit. If you exceed this limit, you cannot pass all the necessary information into a single request. This limitation can disrupt the flow of large-scale conversations or context-heavy tasks.
5. Synchronous Processing
Finally, chat completion models are synchronous. Once you ask a question, you must wait for a single response. You cannot submit multiple requests in parallel and then combine the results without careful orchestration.
Introducing the Assistance API
The OpenAI Assistance API addresses the above challenges by allowing you to build AI assistants with additional capabilities. It provides:
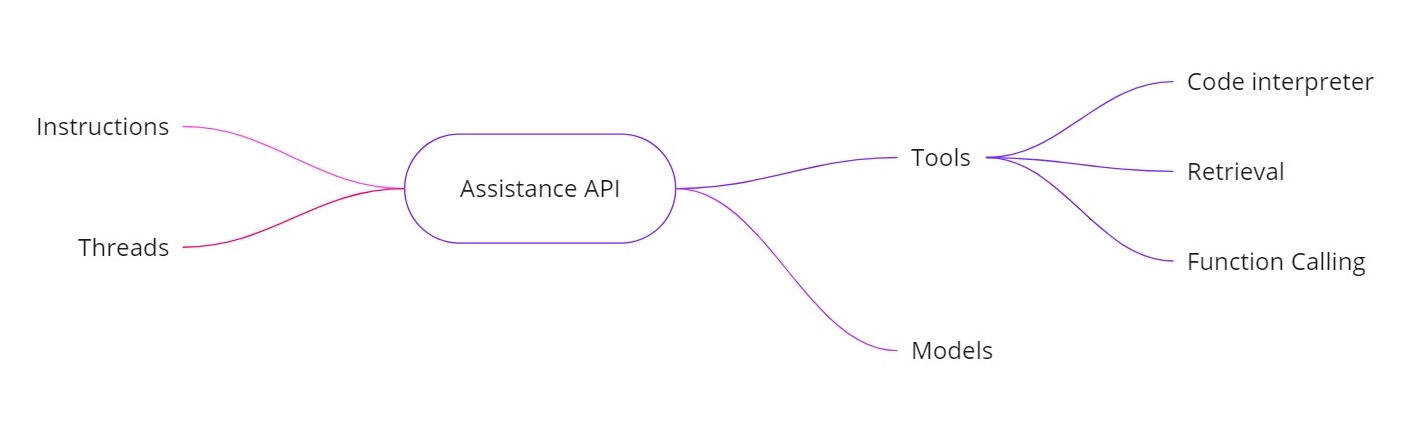
- Instructions. Similar to a system message, these define what your assistant is supposed to do.
- Threads. All previous messages are stored in threads, so the assistant can keep context over multiple turns.
- Tools. These include features like a code interpreter, retrieval for documents, and function calling.
- Models. It currently supports GPT‑4 (1106 preview) and will support custom fine-tuned models in the future.
Tools in the Assistance API
- Code interpreter. When a computational task is requested — like reversing a string or finding today’s date — the assistant can use a code interpreter tool to run Python code. The assistant then returns the correct result, rather than relying solely on token predictions.
- Retrieval. With retrieval, you can upload up to 20 files (each up to 52 MB and up to 2 million tokens per file). When you query, the assistant can reference those files directly, making large document handling much simpler.
- Function calling. You can define a function that queries your internal database (for tasks like checking sales figures). The assistant will request to call that function with the required arguments, and you then return the results to the assistant. This way, the model can utilize up-to-date data that it wouldn’t ordinarily have.
- Handling larger context windows. The threads in the Assistance API dynamically select which messages to include as context, helping it handle larger amounts of conversation. This means you are no longer strictly tied to a small context window.
Example Implementation
Below is a sample Python snippet showing how to create an assistant, set instructions, enable tools, and then run queries using threads. This code illustrates the asynchronous workflow and the usage of features like code interpretation.
Creating the Assistant
# Step 1: Create the Assistant
from openai import OpenAI
client = OpenAI()
my_assistant = client.beta.assistants.create(
instructions="You are a personal math tutor. When asked a question, write and run Python code to answer the question.",
name="Math Tutor",
tools=[{"type": "code_interpreter"}],
model="gpt-4-1106-preview",
)
print(my_assistant)Creating a Thread
# Step 2: Create a Thread
thread = client.beta.threads.create()
print(f"Thread ID: {thread.id}")
'''
Response
{
"id": "thread_abc123",
"object": "thread",
"created_at": 1699012949,
"metadata": {},
"tool_resources": {}
}
'''
print(json.dumps(run.model_dump(), indent =4))Asking a Question
# Step 3: Ask a Question
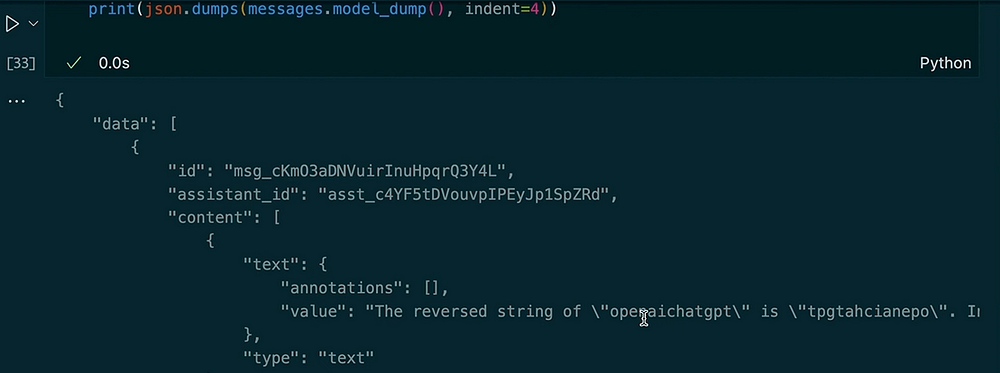
question_1 = "Reverse the string 'openaichatgpt'."
message_1 = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content=question_1
)Running the Query Asynchronously
# Run the Query Asynchronously
run_1 = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id
)
# Check the run status
current_run = client.beta.threads.runs.retrieve(run_id=run_1.id)
print(f"Initial Run Status: {current_run.status}")
# Once completed, retrieve the messages
messages = client.beta.threads.messages.list(thread_id=thread.id)
print(json.dumps(messages.model_dumps(), indent=4))Output:
Asking Another Question in the Same Thread
# Ask Another Question in the Same Thread
question_2 = "Make the previous input uppercase and tell me the length of the string."
message_2 = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content=question_2
)
# Run the second query
run_2 = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id
)
# Check the new run status
current_run_2 = client.beta.threads.runs.retrieve(run_id=run_2.id)
print(f"Second Run Status: {current_run_2.status}")
# Retrieve the new messages
messages_2 = client.beta.threads.messages.list(thread_id=thread.id)
for msg in messages_2:
print(msg.content)Output:

In this example, you can see how the thread persists context. When we ask the assistant to reverse the string, it uses the code interpreter tool. Next, we ask for an uppercase version of the previous input and get the length. The assistant remembers our prior question due to the stored thread messages.
The OpenAI Assistance API provides a robust set of features that extend beyond the typical chat completion models. It keeps track of message history, supports large document retrieval, executes Python code for computations, manages larger contexts, and enables function calling for advanced integrations. If you need real-time calculations, document-based Q and A, or more dynamic interactions in your AI applications, the Assistance API offers solutions that address the core limitations of standard chat completions.
Using these instructions, threads, tools (like code interpreter and retrieval), and function calling, you can create sophisticated AI assistants that seamlessly handle everything from reversing strings to querying internal databases. This new approach can transform how we build and use AI-driven systems in real-world scenarios.
Thank you for reading!
Let’s connect on LinkedIn!
Opinions expressed by DZone contributors are their own.
Comments