CI/CD for Containerized Microservices
Learn the steps and requirements of integration testing for microservices, with best practices for each step, and tips about the QA environment.
Join the DZone community and get the full member experience.
Join For FreeThe benefits of microservices, such as shorter development time, small and independent releases, and decentralized governance introduce a set of challenges like versioning, testing, deployment, and configuration control.
This article can provide approach how to deal with a complex build, test and deploy procedures for microservices.
Problem Description
The build, test, and deploy procedures are pretty straightforward for projects which have only a few microservices or normal services. Very often, such a solution has two or three Docker images with services and UI, so it is easy to perform the integration and testing and make the conclusion that the services are compatible with each other and with the UI. A versioning strategy also can be simple; just version from the assembly (pom, nuget, or other) file. Even deployment to a staging or production environment can be done manually for each microservice.
The situation dramatically changes when
- The solution is divided into several independent "streams" and each "stream" has a set of microservices and UI.
- Each microservice has own life and release cycle.
- Different (even competing) teams work on the project.
- A microservice from one "stream" has a runtime dependency on a microservice from another "stream."
- Microservices depend on the ecosystem (the set of commonly used services, like AAA, logging, etc).
The situation becomes more complicated when each microservice has its own deploy and runtime configuration per environment, for example, no need to install multiple instances of a microservice in a test environment, but it is required for production. As a result, we need to deal at least with a 3-n dimensional array of:
- Containerized microservice Docker/LXC/OS images,
- Deploy configs, and
- Runtime configs,
which need to be managed.
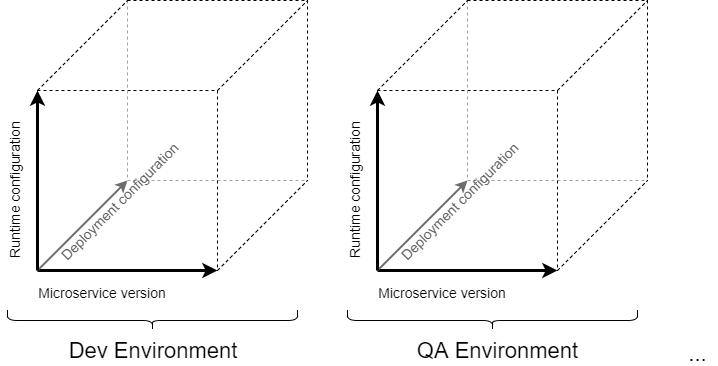
Also, some additional constraints and requirements can exist in the project. Some additional requirements we need take into account:
Immutable server paradigm.
Untested microservices must not be present in the repository.
Each build which passes testing procedures is potentially shippable.
Deploy/rollback procedure for the entire solution shall be as simple as possible and avoid the complexity of dealing with different microservices, that all have different versions.
Build Procedure
Pipeline for One Microservice
Microservices must continue to work when the rest of the world shuts down, so the following consequence is right - it must be built and tested separately first. The pipeline for one microservice would be similar to the one depicted below.
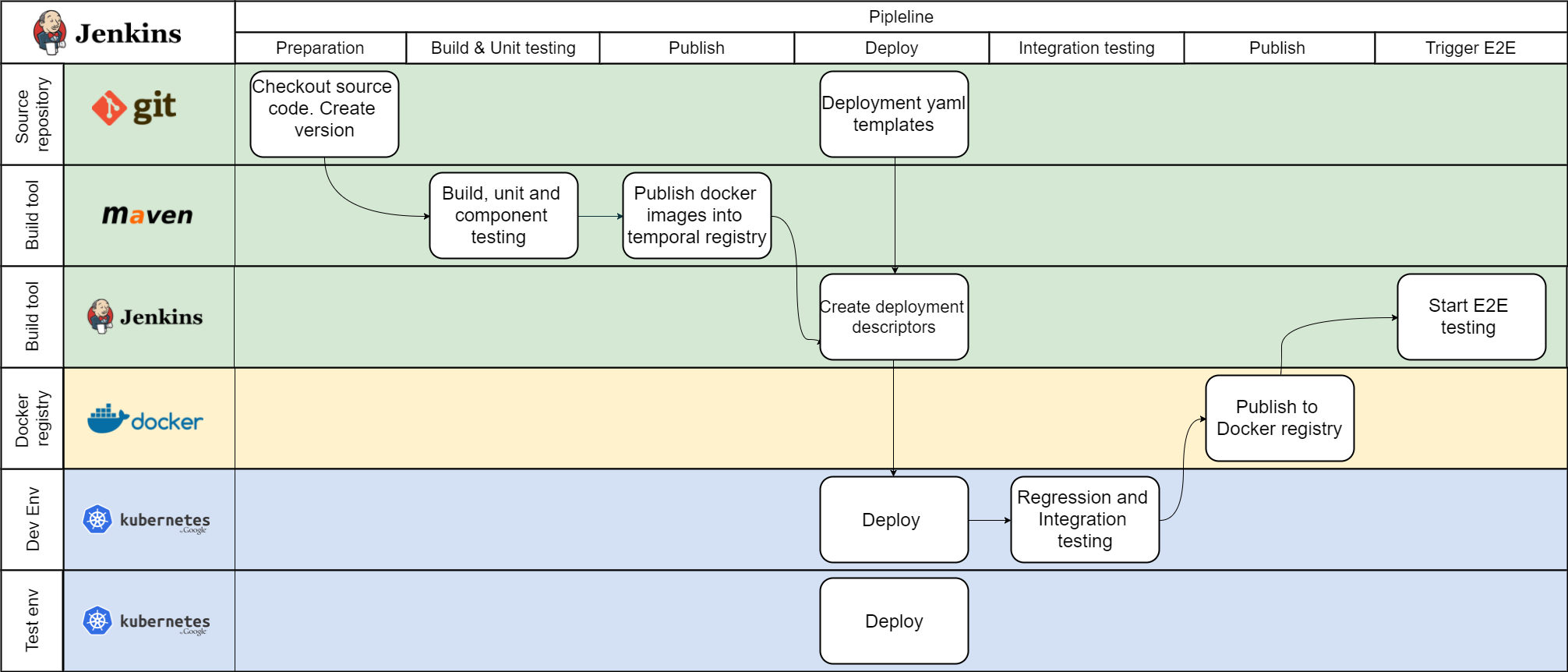
Steps:
Merging code changes into the master/build branch in SCM will trigger the build procedure.
Unit and component tests are performed during the build procedure. Static code analysis is also performed to pass the source code quality gate.
Publish the build artifact into the temporal repository.
Create temporal deployment descriptors from templates. Velocity, Groovy, or any other template can be used in case of Jenkins.
Deploy to the development environment, just to allow manual checks for developers regardless of integration testing result.
Deploy to the test environment and start integration testing. It's nice to have externalized test scenarios and procedures.
Publish into a repository in case integration testing is passed. Trigger integration with other microservices.
End-to-End Testing Pipeline
During this phase, a set of microservices will be integrated with the latest stable version of other microservices.
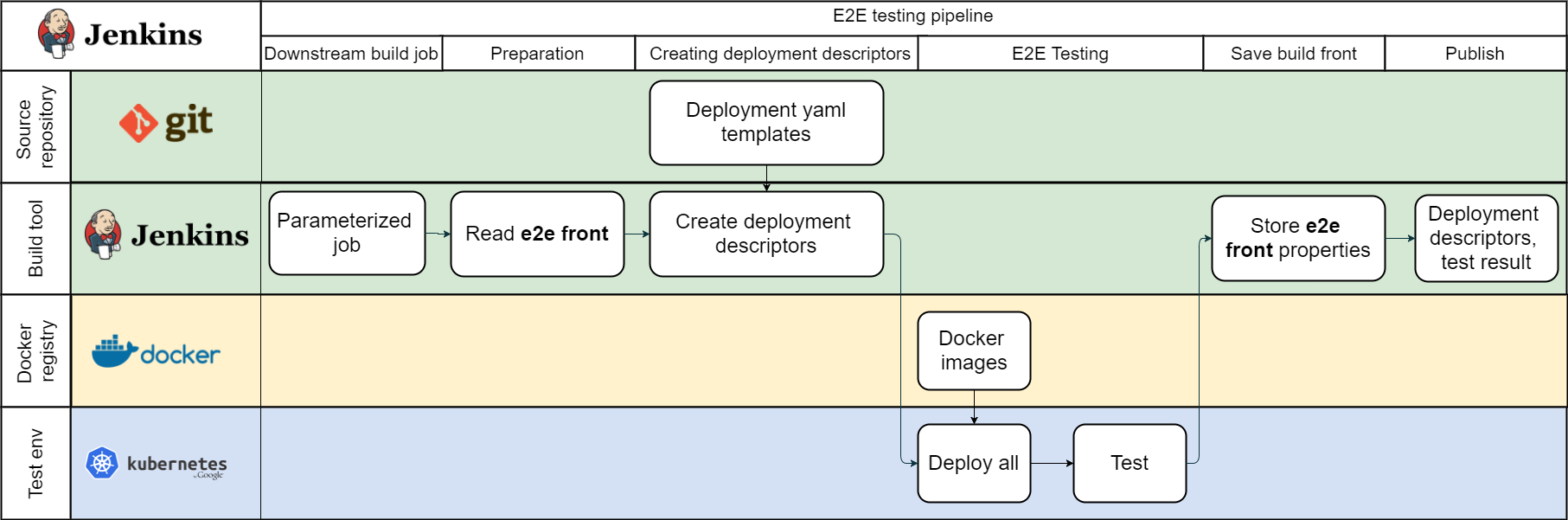
Steps:
The downstream build sends the names and version of microservices which have been changed.
The build server loads the latest version numbers of all existing microservices. The simple property file is enough.
Merge versions with the new one. The set of the versions and deployment templates are used to create deployment descriptors.
Deploy microservices using a set of deployment descriptors with the changed version and run integration tests.
If the testing procedure passes, the build server will persist the set of microservice versions as "Integration testing front" to use next time.
Compose configuration(s) and publish them. To simplify the deployment procedure, it makes sense to create one "uber" deployment descriptor, which will include all necessary microservices, configuration variables, etc.
Integration Testing Front
The end to end integration test job has the latest versions of all microservices, which have successfully passed integration testing. The “integration testing front” plus changes gives the set of microservice versions which must be tested.
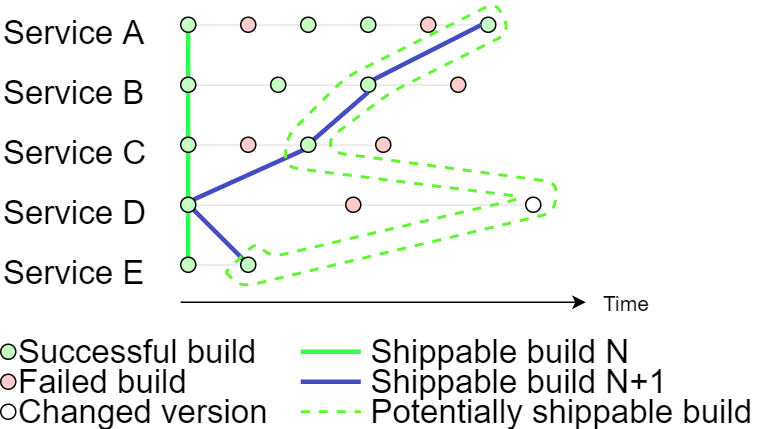
The integration testing across all microservices allows us to say that each build which passes integration testing is potentially shippable.
Hints and Gotchas
It is not a good idea to deploy services using the "latest" anti-pattern, and you need to specify the exact version of the microservice, because not all services are changed and require redeployment.
It is almost impossible to test all possible configurations of microservice versions for each environment, and is actually not required in most cases.
It's better to recreate test environments each time.
Keep the Jenkins pipeline as part of the source code.
Try to avoid usage of an externalized runtime configuration like Spring Cloud config server. Better to provide configuration values with deployment descriptors.
Opinions expressed by DZone contributors are their own.
Comments