Circuit Breaker Implementation in Resilience4j
In this article, we show you how a circuit breaker implementation can increase the performance of your Resilience4j application.
Join the DZone community and get the full member experience.
Join For FreeThis is the second article of a short series about the Resilience4j library. If you are not familiar with the library itself, please read this first. Also, I want to discuss specific implementation details of the circuit breaker pattern inside Resilience4j, so if this pattern is new for you, check out this wonderful article about the main concept behind it.
Currently, the most popular circuit breaker implementation on JVM is Hystrix, but of course, it has its own limitations and capabilities dictated by its core design. Resilience4j is built with other design priorities in mind, so while the main pattern remains the same, some features are different.
Main Ingredients of "Circuit Breaker" Dish
In Resilience4j, the circuit breaker is implemented via a finite state machine with three states: CLOSED, OPEN, and HALF_OPEN. Each state has its own, independently configurable, metrics storage, used to track failure rate and check it against a configured threshold.
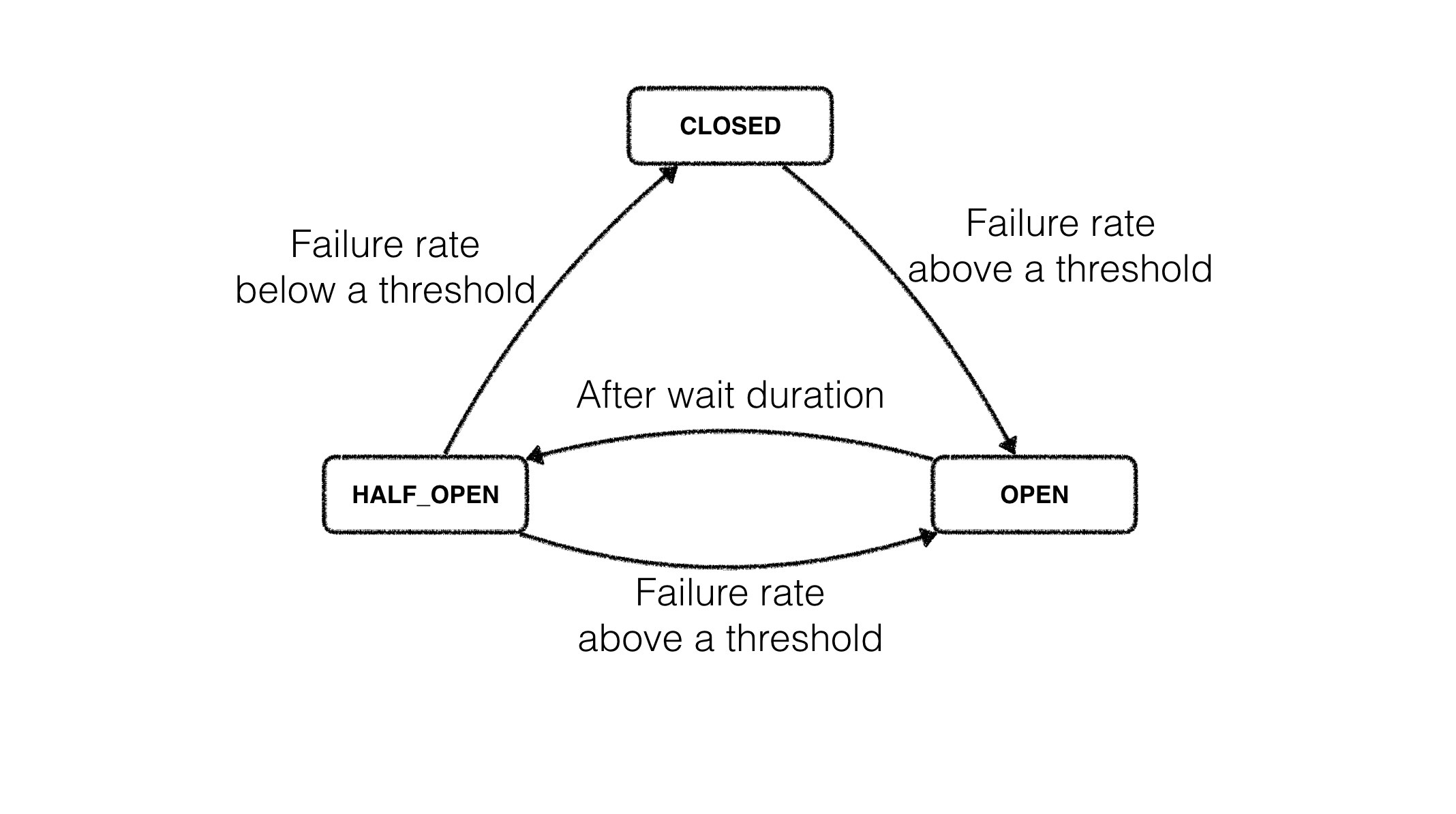
The CircuitBreaker does not know anything about the backend’s state by itself but uses the information provided by the decorators CircuitBreaker::onSuccess via and CircuitBreaker::onError. Decoration example:
static <T> Supplier<T> decorateSupplier(CircuitBreaker circuitBreaker, Supplier<T> supplier){
return () -> {
CircuitBreakerUtils.isCallPermitted(circuitBreaker);
long start = System.nanoTime();
try {
T returnValue = supplier.get();
long durationInNanos = System.nanoTime() - start;
circuitBreaker.onSuccess(durationInNanos);
return returnValue;
} catch (Throwable throwable) {
long durationInNanos = System.nanoTime() - start;
circuitBreaker.onError(durationInNanos, throwable);
throw throwable;
}
};
}The state of the circuit breaker changes from CLOSED to OPEN when the failure rate is above a (configurable) threshold. Then, all access to the protected operation is blocked for a (configurable) time duration. CircuitBreaker::isCallPermitted throws a CircuitBreakerOpenException if the circuit breaker is OPEN.
As you can see from the example, you can protect any functional interface with no need to implement some library specific interfaces like HystrixCommand. Other key differences from Hystrix is that there is no separate thread pool to execute your operations. All operations will be executed within the current thread, so you have more granular control over resources or use our circuit breaker in a non-blocking style within actors/coroutines/fibers, etc.
So we have only two main problems to solve:
How to manage state transitions in a thread-safe manner.
How to track the failure rate within some sliding window of recent operations.
Atomic State Transitions
All transitions' logic is encapsulated within the CircuitBreakerStateMachine class, it has
private final AtomicReference<CircuitBreakerState> stateReference;so the atomic transition can be implemented like this
public void transitionToClosedState() {
CircuitBreakerState previousState = stateReference.getAndUpdate(currentState -> {
if (currentState.getState() == CLOSED) {
return currentState;
}
return new ClosedState(this, currentState.getMetrics());
});
if (previousState.getState() != CLOSED) {
publishStateTransitionEvent(
StateTransition.transitionToClosedState(previousState.getState())
);
}
}CircuitBreakerState is an abstract class with 3 implementations

As you can see, all of them have a CircuitBreakerMetrics instance, as that is a place where all failure rate tracking happens. You can actually configure the number of executions and compare the result against a configurable threshold for each state separately. CircuitBreakerMetrics should be updated after each operation execution. Potentially, these updates can happen from different threads, so it can easily become a bottleneck.
Store Thousands of Operations' Statuses and Not Blow Up the Heap
Unlike the Hystrix implementation, the Resilience4j circuit breaker is not time-related, you can configure it to calculate the current failure rate upon the last N recorded operations. We are using a RingBitSet data structure to store successful calls as 0 bit and failed calls are stored as 1 bit.

RingBitSet has a configurable size and uses a modified version of BitSet to store the bits which are saving memory, compared to a boolean array. The BitSet uses a long[] array to store the bits. That means that the BitSet only needs an array of 16 long (64-bit) values to store the status of 1024 calls.
In our first implementation, we've used BitSet from the standard library and it gave us reasonable performance, with a few consecutive operations of BitSet::set, BitSet::cardinality and CircuitBreakerState::checkFailureRate. But we've decided to optimize these operations even further, just to be sure that we're introducing as little overhead as possible.
And this is a place where we created a small modification of standard BitSet implementation. The key differences are:
In our case BitSet size, is static and it doesn't change after creation, that's why we can eliminate some bounds checks and capacity ensuring the code from our hot path.
The circuit breaker algorithm requires failure rate checking after every BitSet modification, so in our case, we can maintain pre-calculated cardinality in a separate volatile int field and avoid full recalculations.
After all changes, the following methods
public void set(int bitIndex) {
if (bitIndex < 0)
throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);
int wordIndex = wordIndex(bitIndex);
expandTo(wordIndex);
words[wordIndex] |= (1L << bitIndex);
checkInvariants();
}public void clear(int bitIndex) {
if (bitIndex < 0)
throw new IndexOutOfBoundsException("bitIndex < 0: " + bitIndex);
int wordIndex = wordIndex(bitIndex);
if (wordIndex >= wordsInUse)
return;
words[wordIndex] &= ~(1L << bitIndex);
recalculateWordsInUse();
checkInvariants();
}/**
* @return the number of bits set to {@code true} in this {@code BitSet}
*/
public int cardinality() {
int sum = 0;
for (int i = 0; i < wordsInUse; i++)
sum += Long.bitCount(words[i]);
return sum;
}were replaced by one method that can return the previous state of the target bit:
/**
* Sets the bit at the specified index to value.
* @return previous state of bitIndex that can be {@code 1} or {@code 0}
*/
int set(int bitIndex, boolean value) {
int wordIndex = wordIndex(bitIndex);
long bitMask = 1L << bitIndex;
int previous = (words[wordIndex] & bitMask) != 0 ? 1 : 0;
if (value) {
words[wordIndex] |= bitMask;
} else {
words[wordIndex] &= ~bitMask;
}
return previous;
}This simple tricks made us free from cardinality recalculations and now our circuit breaker update operations have O(1) complexity.
Opinions expressed by DZone contributors are their own.
Comments