Convolutional Neural Networks vs. Cascade Classifiers for Object Detection
Convolutional neural networks largely outperform cascade classifiers. It's ideal to choose CNNs if you have enough time for training and your objects don’t scale much.
Join the DZone community and get the full member experience.
Join For FreeHave you ever thought about how many times a day we are watched by surveillance cameras? Every time we enter a public area, there is a high probability "Big Brother" is watching. But it’s not as bad as it may seem. Remote monitoring technologies along with photo and video capturing systems are making our lives safer by detecting crimes and accidents. The surveillance market nowadays is experiencing rapid growth, and developers are looking for new ways to capture and process visual data.
Digital image processing has to deal with object detection, localization, and recognition. These are the tasks we had to complete when working on road sign recognition. This time, we would like to share our experience in detecting objects in images using convolutional neural networks.
If you don’t have enough time for a whole article, we’ve boiled it down into a couple of slides here.
Why Do We Compare These Methods?
Haar cascade classifiers and the LBP-based classifiers used to be the best tools for object detection. When computer vision met convolutional neural networks, cascade classifiers became the second best alternative. But we always think it’s not true unless proven with a test. This was the reason why we tested convolutional neural networks. We wanted to prove they are truly the number-one alternative for object detection.
During the research, we detected objects on car license plates and road signs using convolutional neural networks and cascade classifiers to find the best option.
1. How We Detected License Plate Key Points Using a Convolutional Neural Network
Previously, we used a dataset of license plate numbers as the learning base for image recognition. This time, we decided to use the very same base, as it was a perfect match.
We started by training our convolutional neural network to find key points of license plates. In our case, pixels of the image were independent input parameters while the coordinates of object key points were the dependent output parameters.

In fact, our network required at least 1,000 images of the object to learn how to find key points. Coordinates of key points have to be designated and located in the same order.
Our dataset included only a couple of hundred images, and this wasn’t enough to train the network. Therefore, we decided to increase the dataset by augmenting available data. Before the augmentation, we designated key points in the images and divided our dataset into training and control groups.
During image augmentation, we performed the following transformations:
Shifts.
Resize.
Rotations relative to the center.
Mirror.
Affine transformations (they allowed us to rotate and stretch the picture).
We also resized all images to 320*240 pixels.

We used the Caffe framework as one of the most flexible and fastest frameworks to experiment with convolutional neural networks.
To solve a regression task in Caffe, we used the special file format HDF5. After we normalized pixel values from 0 to 1 and coordinated values from -1 to 1, we packed the images and coordinates of key points in HDF5. You can find more details in the Slideshare presentation below.
First, we tried large network architectures (from four to six convolutional layers and a lot of convolution kernels). However, the performance was very low. To boost performance and keep the quality on the same level we simplified the neural network architecture.
That’s what we ended up with:

We used the optimization method called Adam to train our network. It managed to find the key points quite well when the plates were not very close to the borders.

To understand the convolutional neural network principle better, we studied the obtained convolution kernels and feature maps on different layers of the neural network. On the final model, convolution kernels showed that the network learned to respond to the sudden swings of brightness, which appear in the borders and symbols of a license plate. Feature maps on the images below show the received model.
The trained kernels on the first and second layers are in the following pictures.


For the feature maps in the final model, we took the car picture and transformed it into a grayscale image. Then, we compared maps processed by the first and the second convolutional layers.

The car picture that is given to the network for viewing feature maps.

The feature map after the first convolutional layer.

The feature maps after the second convolutional layer.
Finally, we designated the received keypoint coordinates and got the desired image.

Takeaways
Convolutional neural networks work very well, as the license plates key points were recognized correctly in most cases.
Check this video to see how we detected plates using an iPhone.
2. How We Detected Speed Limit Signs Using a Convolutional Neural Network
To detect road signs, we also used the Caffe framework. To train the network, we used a dataset with nearly 1,700 pictures, and then augmented them up to 35,000.
We successfully trained a neural network to find road signs on 200х200 pixels images. Images of other sizes didn’t work well. To manage this, we experimented with simplified conditions and made our network find a white circle on a dark background. The image size remained 200x200, while the circle size varied from 1x to 3x. In other words, the largest circle's radius was three times bigger than smallest circle's radius.
The network learned to differentiate even similar signs. If the network is pointing at the image center, it means it didn’t find an object.


Takeaway
CNN works great for speed limit sign detection if all signs have a similar size.
3. How We Detect Road Signs Using a Fully Convolutional Neural Network
This part is about how we trained a fully convolutional neural network without fully connected layers to find road signs. This type of network has an image of a specific size at the input and transforms it into a smaller-sized image at the output. Actually, the network is a non-linear filter with resizing. In other words, the neural network increases the sharpness by removing noise from particular image areas. The image edges do not smear but the image size reduces.
The pixel brightness equals 1 in the output image, where an object is. And any pixel outside the image has zero brightness. Therefore, the pixel brightness of the output image is the probability of that pixel belonging to the object.
Note that the output image is smaller than the input image. That’s why the object coordinates have to be scaled in accordance with the output image size.
We chose the following architecture to train the network: four convolutional layers, max-pooling (reducing the size by choosing the biggest one) for the first layer only. We trained the network on speed limit signs. When we finished training and applied the network to our dataset, we binarized it and found the connected components. Every component represented a hypothesis about the sign location.

We divided images into three groups of three pictures each (see the image above). The left row represents input images. The right row is the output. We labeled the central image manually to show the ideal results we would like to have.
We binarized the input image with a threshold of 0.5 and found the connected components. As a result, we found the desired rectangle that designates the location of a road sign. The rectangle is clearly visible in the left image and the coordinates are scaled back to the input image size.
This method showed both good results and false positives:

Takeaways
We considered the results to be positive since the fully convolutional network correctly found signs with a probability of 80%.
The biggest benefit of this model is that you can find two similar signs and label them with a rectangle. If there are no signs in the picture, the network won’t mark anything.
4. How We Decided Which Method Is Better for License Plate Recognition
Previously, we concluded that convolutional neural networks are fully comparable with cascade classifiers and even outperform them for some parameters.
To evaluate the quality and performance of different methods for detecting objects on images, we use the following characteristics:
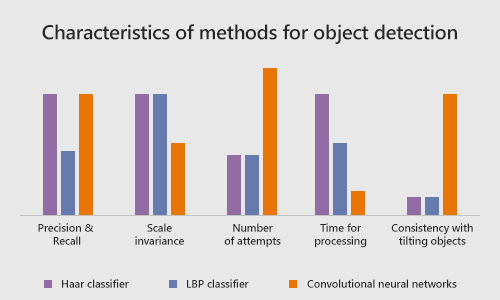
Precision and Recall
Both CNN and Haar classifier have a relatively high level of precision and recall when detecting objects in images. At the same time, the LBP classifier has a high rate of false positives and low precision.
Scale Invariance
Haar cascade classifier and LBP cascade classifier easily manage scaling objects due to strong invariance. However, CNN cannot manage scaling objects well due to low scale invariance.
Number of Attempts Required to Receive a Working Model
Cascade classifiers require only a few attempts to get a working model for object detection. CNN is not so fast and requires dozens of experiments.
Processing Time
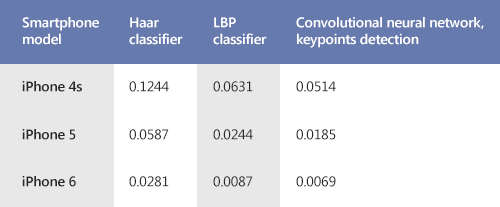
A convolutional neural network does not require much time for processing. Same goes for the LBP classifier. As for the Haar classifier, it takes much longer to be processed.
The average time in seconds spent to process one picture (excluding the time for capturing and displaying video):
Consistency With Tilting Objects
Another great advantage of the convolutional neural network is the consistency with tilting objects. Cascade classifiers are not consistent in these cases.
Summing Up
Convolutional neural networks outperform cascade classifiers in a number of cases. It is more than just reasonable to choose CNN if you have enough time for training and your objects don’t scale much.
We would be happy to learn about your experience. Have you ever chosen between cascade classifiers and CNN for object detection? What other methods have you used for this purpose?
Published at DZone with permission of Ivan Ozhiganov. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments