Context Engineering: The Missing Layer for Enterprise-Grade AI
Your RAG PoC shows potential; context engineering unlocks real performance by shaping data, policies, memory, and tone so you can scale your prototype.
Join the DZone community and get the full member experience.
Join For FreeEnterprises are eager to develop RAG systems, chatbots, and AI copilots, yet many encounter a similar challenge: while the system performs well in demonstrations, it struggles with the complexities of real-world scenarios.
Inconsistencies arise in responses, the tone can shift unexpectedly, hallucinations emerge, and accuracy diminishes as the number of documents increases. The underlying issue isn't the model, the vector database, or the retrieval strategy. Rather, it lies in the absence of context engineering, which involves the deliberate design of what information the model accesses, how it interprets it, and the constraints under which it reasons. By implementing context engineering, AI evolves from an unpredictable text generator into a dependable, policy-aware, role-sensitive intelligence layer that functions like a true enterprise system. This distinction separates a superficial proof of concept from a trustworthy, production-ready AI platform.
What Is Context Engineering?
Many teams assume prompt engineering is enough to control an LLM. But prompts are only a single message. Context engineering is the entire machinery that shapes every message the model produces. At its core, context engineering is the discipline of curating, constraining, structuring, and dynamically adapting all the information the model consumes before generating a response.
If RAG is responsible for finding the right data, context engineering is responsible for shaping the right state. It’s best understood as the AI equivalent of DevOps. DevOps manages how code flows into production. Similarly, context engineering manages how information flows into the model. Instead of “configuration as code”, you now have “context as code” structured, versioned, testable, and governed.
This discipline operates across three coordinated layers:
Static Context - Static context is the unchanging foundation of the AI system. It defines identity, boundaries, compliance posture, and tone, ensuring the model behaves consistently no matter who asks questions or what is retrieved. It includes:
- Instructions - System’s operating manual
- Business Rules - Domain-specific constraints
- Compliance Restrictions - Guardrails for the system
- Enterprise Persona & Voice - Tone, Terminology and Communication Style
Dynamic Context - Dynamic context adapts based on who the user is, what they’re doing, and how the conversation evolves. This is where an AI system stops being generic and starts acting like a genuine domain expert. It includes:
- Retrieved Documents - Policy-aware, reranked, and filtered content
- User Profile - Department, permissions, expertise level, preferences
- Session Memory - Previous queries, corrections, draft progress, feedback
- Location, Time, Role
- Task Progress - Multi-step workflows, approvals, and document creation crucial for agent-driven systems
Behavioral Context - This is the subtle but transformative layer that is responsible for how the model thinks, reasons, and interacts. It governs:
Tone: Should the response be formal? Technical? Conversational? Supportive?
Reasoning Strategy: Should the agent:
- Think step-by-step?
- Validate through a critic?
- Query tools first?
- Enforce citations?
Safety Constraints: Hallucination prevention, disclaimers, verification rules.
Tool-Usage Policies: When and how the system should call retrievers, calculators, planners, validators, generators, etc.
Static context ensures the AI behaves predictably even when retrieval gets noisy or prompts vary. Dynamic context enables the AI to reason continuously rather than treating each message as a blank slate. Behavioral context is what converts an LLM into a deliberate agent.
When you combine all three layers:
- Tone stays consistent and on-brand
- Responses become relevant and precise
- Outputs are explainable and traceable
- Safety and compliance are enforced by design
- Users receive role-aware, policy-aware, context-aware intelligence
Your AI stops behaving like a demo chatbot and starts functioning like a real enterprise system. In short, context engineering makes the LLM behave like your system, not a random internet model.
Why Enterprises Can’t Ignore It
Context is the driving force behind every LLM response, yet many organizations often overlook its importance. They allocate millions to embeddings, retrieval engines, and finely tuned models, only to find that accuracy, tone, and trust falter in real-world conditions. The reality is straightforward:
Enterprises don’t fail due to poor RAG; they fail because their context is unmanaged.
Even with flawless embeddings, incorrect answers can still arise. Despite having the most robust model, responses may come across as generic or misaligned with the brand. Even with a well-structured vector database, retrieval can falter beyond a few hundred documents.
What's lacking is the discipline that governs:
- The information that is included in the prompt
- The structuring and ranking of retrieved content
- The preservation of essential metadata signals (dates, roles, jurisdictions)
- The adaptation of tone, persona, and reasoning to the user, role, and location
- The appropriate timing for switching retrieval strategies (broad/narrow/graph-based)
- The management of memory, goals, and constraints in multi-turn conversations
Context engineering is the process of controlling reasoning before generation, ensuring that the model thinks and communicates like the enterprise it represents, rather than a random internet-trained LLM.
In summary, enterprises require context engineering as it provides a dependable means to ensure accuracy, safety, consistency, and scalability. It offers the structure that makes LLMs reliable and lays the groundwork for advanced agentic systems.
The Enterprise Context Engineering Stack
Many organizations settle for a basic RAG pipeline, merely ingesting some PDFs, embedding them, conducting vector searches, and calling it a day. However, genuine enterprise AI demands a comprehensive context engineering architecture in which each layer influences how the LLM interprets data, enforces policy, preserves memory, and reasons safely.
Here’s what a fully operational context engineering system truly entails.
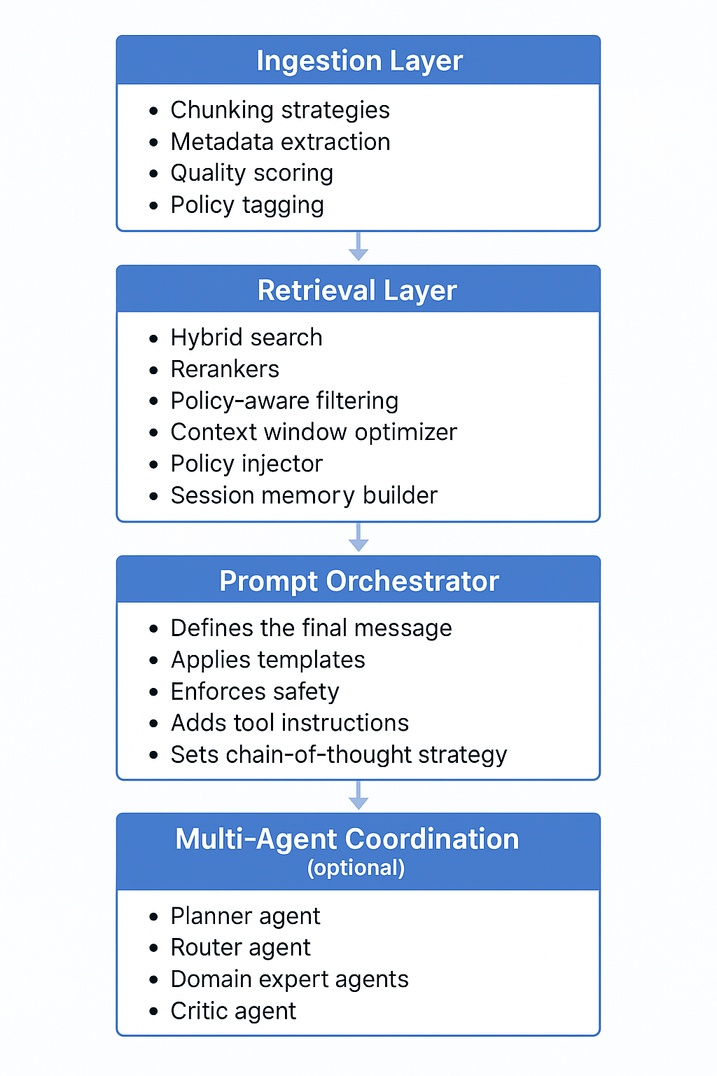
Each layer adds structure, control, and intelligence to the system.
Ingestion Layer - Builds Clean, Structured, Policy-Aware Knowledge
This layer turns raw enterprise content into structured, high-quality knowledge objects. It’s not “upload docs” but a full data engineering pipeline. It includes:
Advanced Chunking Strategies: Chunking determines how well the AI understands your documents. Good chunking reduces hallucinations because the AI receives complete information, not chopped-up fragments.
- Semantic chunking – uses embeddings to split based on meaning
- Recursive chunking – breaks content into logically nested units (e.g., chapter → section → paragraph)
- Hierarchical chunking – preserves structure for tree-like retrieval
Metadata Extraction: After chunking, each chunk becomes enriched with metadata such as:
- Document type
- Version
- Publication date
- Department owner
- Legal jurisdiction
- Keywords and taxonomy tags
Quality Scoring: Scoring is done on the chunks since not all chunks are equal. High-quality chunks get prioritized during retrieval. Chunks can be scored using:
- Completeness
- Readability
- Policy relevance
- Recency
Policy Tagging: The final step would be to tag content with compliance rules so as to allow policy-based retrieval and context filtering. Compliance rules can be:
- Budget-sensitive
- Legal-reviewed
- Public-facing
- Internal-only
Retrieval Layer - Get the Right Context, Not Just “Similar Text”
Most RAG failures happen in this layer. Retrieval must be designed, not improvised. This layer includes:
Hybrid Search: A robust retrieval system blends multiple retrieval styles. Combining these avoids cases where semantic search alone misses critical facts.
- Vector search (semantic similarity)
- Keyword search (BM25, exact matches)
- Graph search (relationships, dependencies, citations)
Rerankers: Use transformer-based rerankers to evaluate the top 50 retrieved chunks and reorder them based on:
- Relevance
- Policy fit
- Intent match
- Factual accuracy
Policy Aware Filtering: This is where enterprise accuracy is won or lost. Context should be filtered before it reaches the model. Example:
- If query relates to law, only show legal-reviewed documents
- If user is finance department, hide non-finance content
- If topic is housing subsidies, rank infra documents higher than older policy docs
Context Builder Layer - The Brain of the System
This layer dynamically constructs the precise state in which the LLM should function. It encompasses:
Intent Classifier: This element focuses on understanding the user’s objective by identifying:
- What to retrieve
- Which policies are applicable
- Which persona to engage
Context Router: Directs the query to the appropriate retrieval strategy, such as:
- Narrow search (specific topic)
- Broad search (exploratory)
- Structured search (tables, forms, laws)
- Graph search (relationships, hierarchies)
Persona & Tone Selector: Adjusts the response tone based on user role, location, seniority, department, and task intent.
Context Window Optimizer: Optimizes the amount of context for the model by:
- Removing redundant information
- Merging short, related segments
- Prioritizing recency or authority
- Reducing noise and performing deduplication
Policy Injector: Dynamically incorporates enterprise or business rules by adding jurisdiction-specific guidelines and disclaimers, while ensuring compliance. This helps prevent hallucinations at the source.
Session Memory Builder: This component fosters continuity across conversational turns by utilizing:
- Past actions
- Earlier clarifications
- Intermediate steps
- Previous failures
Prompt Orchestrator - The Final, Controlled Input to the LLM
This layer is responsible for crafting the exact prompt that engages the model according to established roles and rules. It includes:
Prompt Template Application: This component employs role-specific, version-controlled templates that cover formats for Q&A, summarization, classification, extraction, planning, critique, and reasoning.
Safety Enforcement: This aspect integrates rules designed to prevent hallucinations, unverified claims, harmful instructions, and the revealing of internal systems.
Tool Instructions: This module guides the agent on when to search, calculate, verify, and generate responses.
Reasoning Style Selection: This functionality assists in determining the desired chain-of-thought strategy, which may include:
- Step-by-step
- Reasoning with constraints
- Planning-first
- Critic-validation
- Debate agent mode
Multi-Agent Coordination - Optional, But the Future of Enterprise AI
Once the system has established a controlled context, you can safely introduce multiple agents, such as:
- Planner Agent - Breaks down the user’s query into manageable steps.
- Router Agent - Determines which specialist agent or tool to utilize.
- Domain Expert Agents - Include housing advisors, legal reviewers, finance validators, and engineering analysts, each with their own static context.
- Critic Agent - Validates correctness, consistency, safety, and references sources.
Multi-agent systems demand robust context engineering to avoid disarray. When executed effectively, they become reliable, explainable, and extraordinarily powerful.
From PoC to Full-Fledged Enterprise System: The Roadmap
Most enterprises embark on their AI journey with a basic RAG demo, only to discover how quickly it falters in the face of real-world complexities. To develop a production-ready, policy-compliant, multi-agent AI system, organizations generally adhere to a four-phase maturity curve. Each phase adds new layers of control, reasoning, safety, and context.
Phase 1: Basic RAG PoC Is the “It Works on My Laptop” Stage
This initial phase is where most teams begin. The objective is to demonstrate that retrieval-augmented generation is feasible for your documents.
Typical characteristics of this stage include:
- Documents → chunks → embeddings
- A single vector search pipeline
- One generic prompt template
- One foundational model (GPT, Claude, Llama, etc.)
- No user differentiation
- No policy awareness
- No memory or tone control
- Works reasonably well with 30–50 documents but struggles at scale
Common symptoms:
- Answers drift into hallucinations
- Tone is inconsistent
- Irrelevant chunks appear
- Lack of citations or source alignment
- The system does not comprehend roles or departments
Phase 2: Context-Aware Retrieval Is the First Real Upgrade
As teams encounter the limitations of a basic PoC, they begin to introduce structure and intelligence into the retrieval process. This is where RAG becomes more precise and predictable. The new enhancements encompass:
- Metadata Filtering
- Rerankers
- Domain-Specific Search Profiles
- Query Rewriting
- Intent Classification
The outcome of Phase 2? Hallucinations decrease, retrieval sharpens, and answers become significantly more relevant.
Phase 3: Full Context Engineering Is When the System Starts Thinking Intentionally
In this phase, teams transition from RAG to an enterprise AI system. The LLM no longer receives raw chunks; instead, it is fed curated, policy-aware, role-aware context built according to enterprise rules. This includes capabilities such as:
- Dynamic Context Windows
- Tone & Persona Adaptation
- Session-Level Memory
- Policy Injection
- Response Style Enforcement
- Role-Based Access Control
Phase 3's outcome sees the system becomes predictable, safe, contextual, and aligned with enterprise needs.
Phase 4: Enterprise Multi-Agent Orchestration Is Where Real Autonomy Begins
Companies that reach this stage unlock the full potential of enterprise AI. Rather than relying on a single model for all tasks, multiple agents collaborate as a cohesive team. Commonly introduced agents may include:
- Planner Agent
- Retrieval Specialist Agent
- Fact Check Agent
- Safety-Critic Agent
- Output Validator
All agents share memory, policies, and a central context builder, making reasoning both explainable and auditable.
Phase 4's outcome is an autonomous, explainable, chain-of-command AI that reliably executes multi-step enterprise tasks.
Final Thoughts
Enterprises don't fail because RAG is ineffective; they fail due to uncontrolled context.
Context engineering is what elevates your AI from a mere prototype to a dependable, enterprise-grade system. It introduces precision, governance, and intelligence into every LLM interaction, shaping what the model sees, how it reasons, and how it responds.
If RAG is the engine driving your AI, context engineering serves as the steering system, transmission, and GPS combined. It aligns every response with your tone, policies, and purpose, ensuring your AI operates as a trusted advisor rather than just a clever chatbot.
Accuracy, explainability, safety, and scalability all begin with engineered context. Without it, you're simply prompting in the dark.
Opinions expressed by DZone contributors are their own.
Comments