Data Pipeline Orchestration
In this article, I share an idea of what a data pipeline orchestration model might look like.
Join the DZone community and get the full member experience.
Join For FreeThe spectrum of tasks data scientists and engineers need to do today is tremendous. The best description of it you will find in this article: The AI Hierarchy of Needs. A long road of technical problems needs to be completed before you can start working on the real business problem and build valuable data products. Most of the time is spent on infrastructure, data security, transition, processing, storing, provisioning, testing, and operational readiness/healthiness.
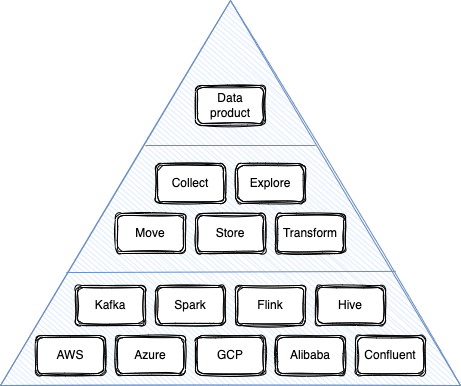
As a data engineer, I need a single interface or operating system with composable capabilities provided in distributed hybrids environments and extensible for future implementations.
Giving such a tool will help data scientists and engineers to keep the focus on business problem solving without diving into the technical complexity of the implementation details and operational readiness.
GOAL: Create a unified data pipelines orchestration interface for data engineers.
What Is a Data Pipeline?
The data derived from the user and applications activities can be categorized into two groups:
- Operational - internal system events and metrics. Used to optimize the performance and reliability of the application.
- Analytics - historical data created by users while using the application. Used to optimize the user experience.
This derived data brings many byproducts created by service operators, data engineers, and analytics such as KPI reports, monitoring dashboards, machine learning models, and so on. To create such data products, data need to be collected from the source, cleaned, processed as a stream, and send to a sink such as a data warehouse or data lake.
A Data Pipeline is a term used to describe a data flow consisting of reading, processing, and storage tasks that ingest, move, and transform raw data from one or more sources to a destination.
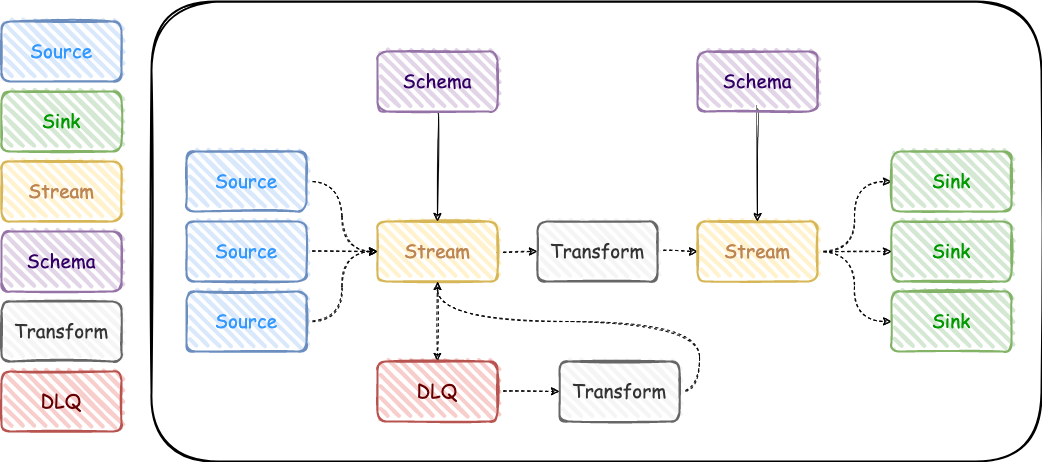
Each of the elements represents a task with resources responsible for one purpose in the pipeline body. For example, a source - provides capabilities to read data from other systems. It could be a Kafka connector, rest API poller, or webhook subscriber. It could also be a simple bash command in the Linux OS, but in the world of highly-intensive big data, it also needs resources provisioned in a distributed processing environment.
The element itself is responsible for:
- Input validation and acceptance (both from a user and other elements)
- Resources provision
- Tasks and services execution
- State management (scheduling, retrying, error handling)
- Output provision
There are also dependencies between them, and outputs from the single command or resource should be directed as input for other elements. Assuming the life cycle of components consists of different states(ex, provisioning, ready, healthy, error,) its handling requires a management process that can be automated.
Pipeline Orchestration
Single components by themselves don't solve complex data engineering problems. For example: to prepare data for ML model training, we likely need to read it from the source, validate and filter non-applicable outliers, perform aggregations with transformations and send it to the storage system. Orchestration is the process of composing or building complex structures from a single responsible block, element, or component.
Capabilities of orchestration layer:
- Connect components into workflows/chains of tasks/steps
- Provisioning resources into downstream systems
- Input/output and state management
Non-functional capabilities
- Extensible
- Observable
- Distributed processing in a hybrid environment
A similar analog is a system command line interface that allows you to combine single commands into a chain of functions via piping. The commands themselves are very restricted on responsibilities but quite stable and highly performant following Unix philosophy. Operating systems terminals in the early days were the single API or entry point for communication between users and technology. Today we have the same business needs but with data-intensive applications working in a distributed cloud environment.
Orchestration Products Available Today
AI&Data landscape provided by Cloud Native Computing Foundation shows a huge number of tools available today for data engineers, and it becomes enormous if we also add DevOps tools and services from cloud providers and SaaS companies. I'll be back with a detailed analysis and comparison of them later, maybe, if I have a time-stop machine :) For now, let's look into Apache Airflow and Terraform as the most popular for workflow tasks and infrastructure orchestrations.
Inside Apache Airflow, the DAG(Direct Acyclic Graph) is commonly used for connecting tasks into workflows. This solves the problem of connecting elements and defining dependencies used later for task execution. But how can the resources be provided in an external system? That is why Airflow has operators with a lot of providers available. This also solves the problem of extensibility.
Using Terraform, a DevOps engineer can orchestrate complex structures and use a single API interface for its provisioning. The declarative model is used for creating infrastructure as code in comparison with the Airflow imperative programming model in Phyton. The same as Airflow, there is a provider delegating and extension mechanism with a lot of vendors available.
All these tools have different interfaces and can hardly be called simple. There is no single unified model of how the orchestration element should look like…
Orchestration Model
Using these orchestration tools, let's try to define what should be the unified structure of orchestration components.
When we want to create smth, we need blocks. There are so many words that can be used for such a single unit of build: a component, a task, a block, a node, an object, a function, an entity, a brick, a resource, an atom, a quantum and so on. Having a block as the main build unit is used in many creative engineering games: For example, Minecraft, Lego bricks, or Puzzles.
Let's imagine we have such an element for data pipeline orchestration. What should it consist of?
{
"type": "source",
"version": "0.0.1",
"name": "exampleHttpSource",
"provider": "AWS",
"extension": "S3SourceExtension",
"state": "READY",
"configuration": {},
"outputs": {},
"dependsOn": []
}Type - is the client's property to help easily define the purpose or behavior of elements (source, stream, transform, sink, schema, etc.).
Provider - is a Cloud provider, SaaS service vendor, or downstream system o for delegating resources provisioning.
Extension - is an implementation class with all logic for resource creation. The idea for extensions comes from the microkernel pattern.
Configuration - is a placeholder for all properties required to provide the element in the downstream system or execute a command.
The purpose of the element is not only to provision the resource but also to provide feedback about it. The state will show if it was created successfully, is still in progress, or if some error happened.
At each step of the element life cycle, some outputs might be generated, such as id, name, or error message. All this meta information can be found in the outputs section.
The information in the element should be enough for clients to understand the purpose and how to use it. At the same time, the technical specifications encapsulated in the implementation class and configuration section will give providers instructions on how to execute it.
The life of a data scientist is hard today, and it takes more time to solve technical problems than business. The orchestration tools such as Airflow and Terraform help a lot, however, there is no single interface or standard of how the orchestration model should look like. In this article, I shared an idea of what such a unified model might look like. This might be helpful for data engineers and architects who want to build domain-driven solutions abstracted and agnostic to the fast-growing and changing development environment. It isn't a complete solution to the problem we have today but an intention towards where we can be tomorrow.
Opinions expressed by DZone contributors are their own.
Comments