Database Dissection: How Are Fast Data Queries Implemented?
What's more important than the quick performance itself is the architectural design and mechanism that enable it. The rest will be easy.
Join the DZone community and get the full member experience.
Join For FreeIn data analytics, fast query performance is more of a result than a guarantee. What's more important than the result itself is the architectural design and mechanism that enables quick performance. This is exactly what this post is about. I will put you into context with a typical use case of Apache Doris, an open-source MPP-based analytic database.
The user, in this case, is an all-category Q&A website. As a billion-dollar listed company, they have their own data management platform. What Doris does is support the data filtering, packaging, analyzing, and monitoring workloads of that platform. Based on their huge data size, the user demands quick data loading and quick response to queries.
How To Enable Quick Queries on a Huge Dataset
- Scenario: user segmentation for the website
- Data size: 100 billion data objects, 2.4 million tags
- Requirements: query response time < 1 second; result packaging < 10 seconds
For these goals, the engineers have made three critical changes in their data processing pipeline.
1. Distribute the Data
User segmentation is when analysts pick out a group of website users that share certain characteristics (tags). In the database system, this process is implemented by a bunch of set operations (union, intersection, and difference).
Narration From the Engineers:
We realize that instead of executing set operations on one big dataset, we can divide our dataset into smaller ones, execute set operations on each of them, and then merge all the results. In this way, each small dataset is computed by one thread/queue. Then we have a queue to do the final merging. It's simple distributed computing thinking.

Example:
- Every 1 million users are put into one group with a
group_id. - All user tags in that same group will relate to the corresponding
group_id. - Calculate the union/intersection/difference within each group. (Enable multi-thread mode to increase computation efficiency.)
- Merge the results from the groups.
The problem here is since user tags are randomly distributed across various machines, the computation entails multi-time shuffling, which brings huge network overhead. That leads to the second change.
2. Pre-Bind a Data Group to a Machine
This is enabled by the Colocate mechanism of Apache Doris. The idea of Colocate is to place data chunks that are often accessed together onto the same node so as to reduce cross-node data transfer and, thus, get a lower latency.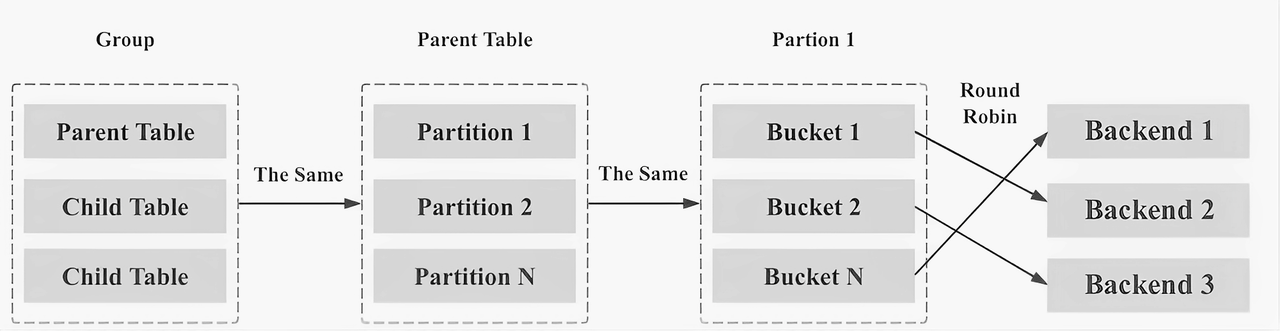
The implementation is simple: Bind one group key to one machine. Then naturally, data corresponding to that group key will be pre-bound to that machine.
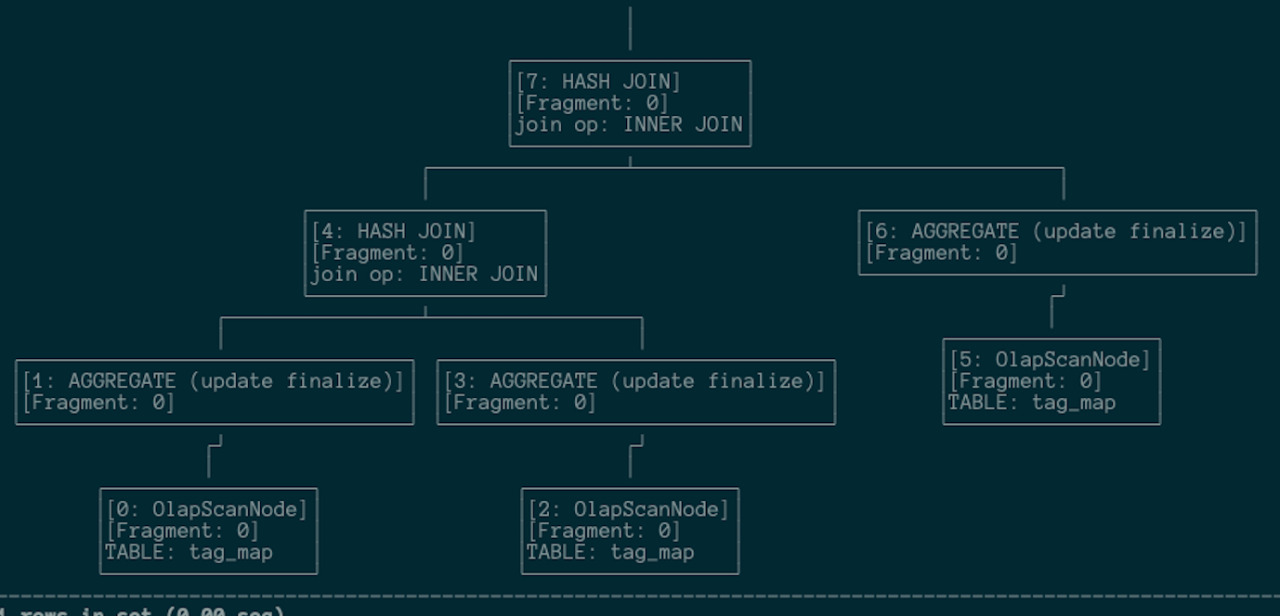
The following is the query plan before we adopted Collocate: It is complicated, with a lot of data shuffling.

This is the query plan after. It is much simpler, which is why queries are much faster and less costly.
3. Merge the Operators
In data queries, the engineers realized that they often use a couple of functions in combination, so they decided to develop compound functions to further improve execution efficiency. They came to the Doris community and talked about their thoughts. The Doris developers provided support for them, and soon the compound functions are ready for use on Doris. These are a few examples:
bitmap_and_count == bitmap_count(bitmap_and(bitmap1, bitmap2)) bitmap_and_not_count == bitmap_count(bitmap_not(bitmap1, bitmap_and(bitmap1, bitmap2)) orthogonal_bitmap_union_count==bitmap_and(bitmap1,bitmap_and(bitmap2,bitmap3)
Query execution with one compound function is much faster than that with a chain of simple functions, as you can tell from the lengths of the flow charts:
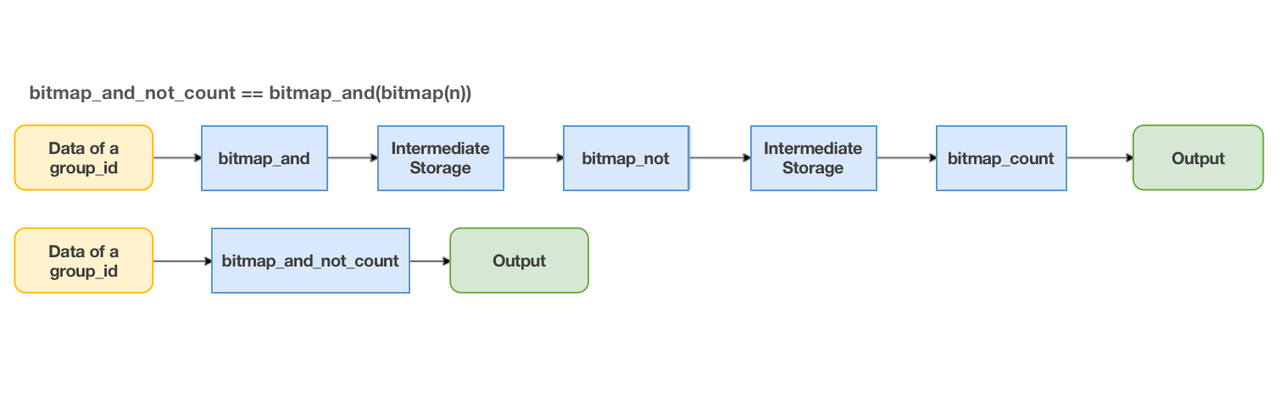
- Multiple Simple functions: This involves three function executions and two intermediate storage. It's a long and slow process.
- One compound function: Simple in and out.
How to Quickly Ingest Large Amounts of Data
This is about putting the right workload on the right component. Apache Doris supports a variety of data-loading methods. After trials and errors, the user settled on Spark Load and thus decreased their data loading time by 90%.
Narration From the Engineers:
In offline data ingestion, we used to perform most computations in Apache Hive, write the data files to HDFS, and pull data regularly from HDFS to Apache Doris. However, after Doris obtains parquet files from HDFS, it performs a series of operations on them before it can turn them into segment files: decompressing, bucketing, sorting, aggregating, and compressing. These workloads will be borne by Doris backends, which have to undertake a few bitmap operations at the same time. So there is a huge pressure on the CPU.
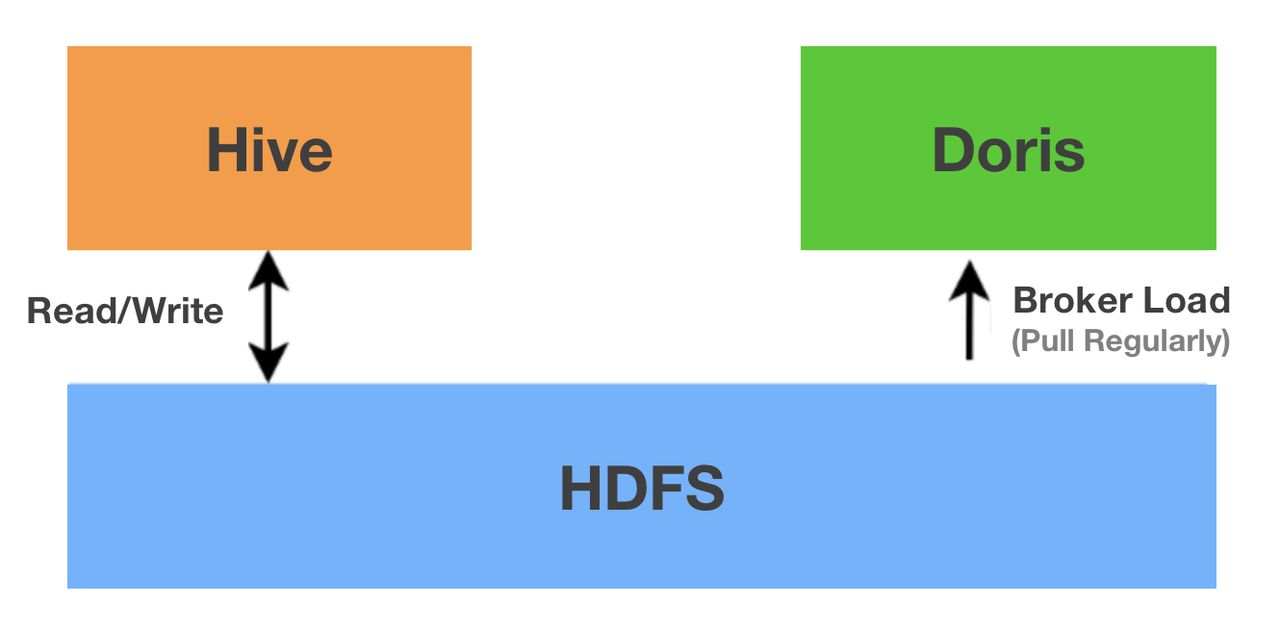
So, we decided on the Spark Load method. It allows us to split the ingestion process into two parts: computation and storage, so we can move all the bucketing, sorting, aggregating, and compressing to Spark clusters. Then Spark writes the output to HDFS, from which Doris pulls data and flushes it to the local disks.
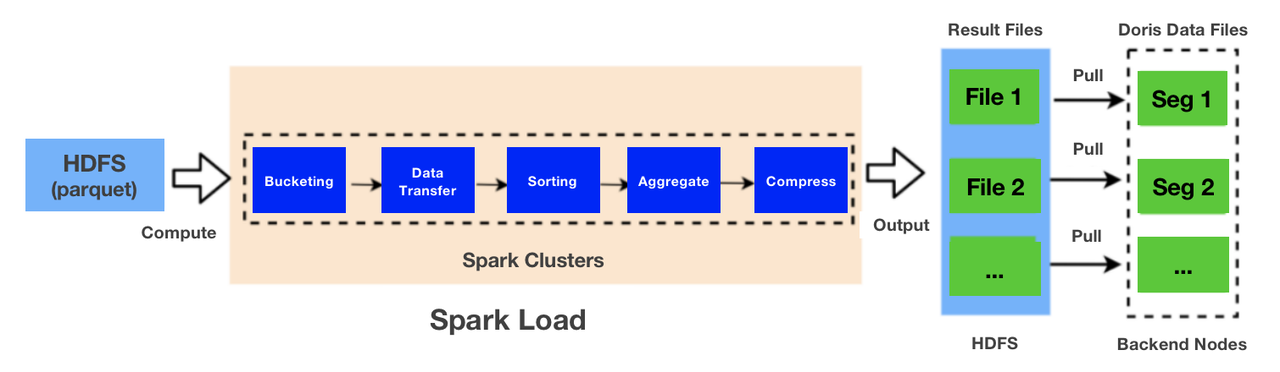
When ingesting 1.2 TB data (that's 110 billion rows), the Spark Load method only took 55 minutes.
A Vectorized Execution Engine
In addition to the above changes, a large part of the performance of a database relies on its execution engine. In the case of Apache Doris, it has fully vectorized its storage and computation layers since version 1.1. The longtime user also witnessed this revolution, so we invited them to test how the vectorized engine worked.
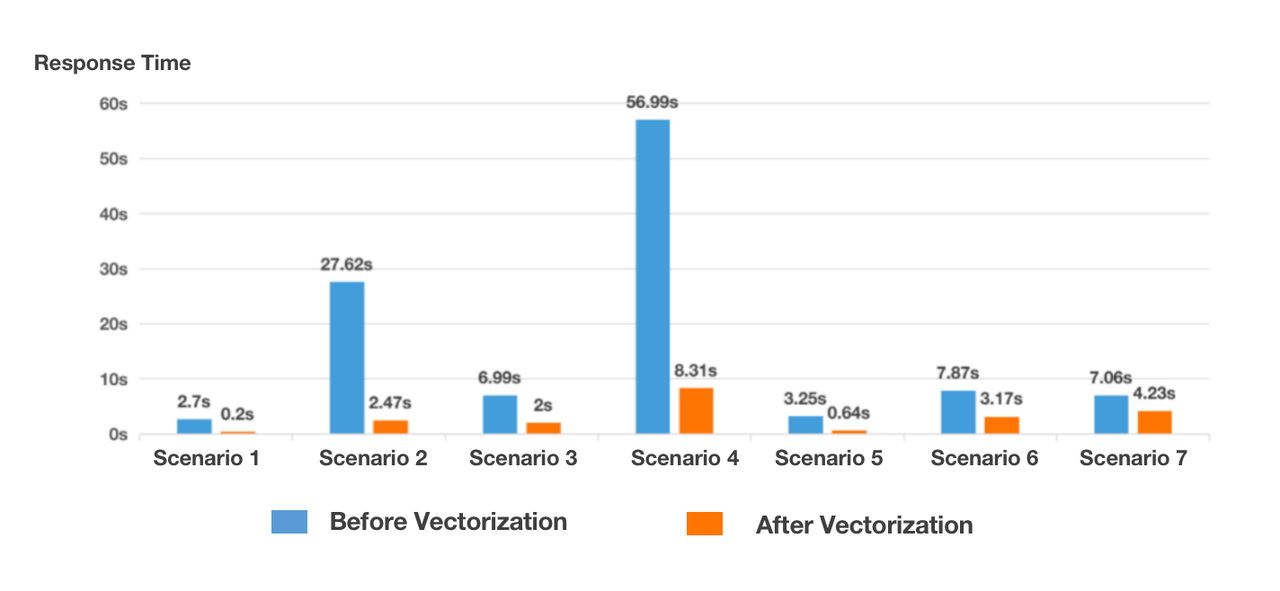
They compared query response time before and after the vectorization in seven of its frequent scenarios:
- Scenario 1: Simple user segmentation (hundreds of filtering conditions), data packaging of a multi-million user group.
- Scenario 2: Complicated user segmentation (thousands of filtering conditions), data packaging of a tens-of-million user group.
- Scenario 3: Multi-dimensional filtering (6 dimensions), single-table query, single-date flat table, data aggregation, 180 million rows per day.
- Scenario 4: Multi-dimensional filtering (6 dimensions), single-table query, multi-date flat table, data aggregation, 180 million rows per day.
- Scenario 5: Single-table query, COUNT, 180 million rows per day.
- Scenario 6: Multi-table query (Table A: 180 million rows, SUM, COUNT; Table B: 1.5 million rows, bitmap aggregation), aggregate Table A and Table B, join them with Table C, and then join the sub-tables, six joins in total.
- Scenario 7: Single-table query, 500 million rows of itemized data
The results are as below:
Conclusion
In short, what contributed to the fast data loading and data queries in this case?
- The Colocate mechanism that's designed for distributed computing
- Collaboration between database users and developers that enables the operator merging
- Support for a wide range of data loading methods to choose from
- A vectorized engine that brings overall performance increase
It takes efforts from both the database developers and users to make fast performance possible. The user's experience and knowledge of their own status quo will allow them to figure out the quickest path, while a good database design will help pave the way and make users' life easier.
Published at DZone with permission of Shirley H.. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments