Database Scaling Made Simple
For every problem technology poses, it offers many possible solutions. Here's how to take much of the sting out of scaling databases.
Join the DZone community and get the full member experience.
Join For FreeYour database scaling strategy should match the way the system is used and the extent to which the database's nodes are distributed.
Not so long ago, the solution to bulky database performance was to throw more hardware at it — faster servers and memory, more network bandwidth, and boom! Your database is back to bullet-train speeds.
Any system administrator will tell you that databases aren't what they used to be. For one thing, today's databases are much more widely distributed, reaching end points of all types: phones, tablets, controllers, sensors, even appliances. For another thing, a single database is more likely to run on multiple platforms and interface with systems of all types. Last but not least, the amount of data stored in a typical production database dwarfs the typical storage of just a few years ago.
So, you've got more data than ever that's integrating with more devices and platforms than ever and reaching more device types than ever. Add to this the modern demands of real-time analysis and zero downtime. It's enough to make a DBA consider a midlife career change.
But before you start thinking about life as a karaoke repairman, remember that for every problem technology poses, it offers many possible solutions. The trick is to find the answer for your technical predicament and apply it to best effect. The solution to many database performance glitches is scalability. The challenge is that traditional RDBMSs are easy to scale up by adding more and faster CPUs and memory, but they're notorious for not scaling out easily, which is a problem for today's widely distributed systems. Here's how to take much of the sting out of scaling databases.
The prototypical example of a scale-out system is a web app, which expands across low-cost servers as the number of users increases. By contrast, an RDBMS is designed to scale up: improve performance by adding processing power and more/faster memory.
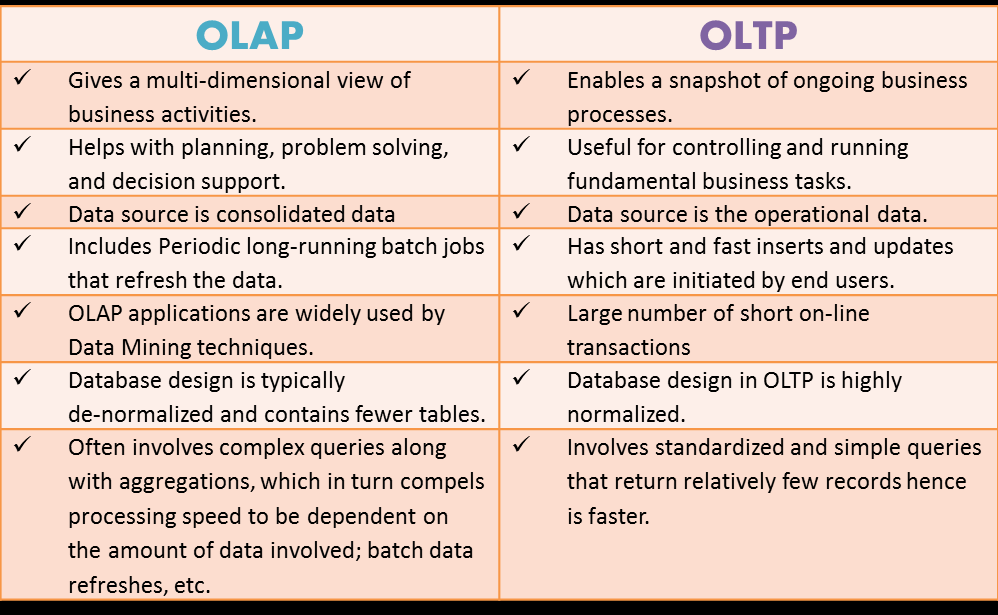
Web apps are noted for scaling out to commodity servers as demand increases, while RDBMSs scale up by adding more and faster processor and memory, but less well as the number of users goes up. Source: Couchbase.
Forget the Backend; Analytics Now Happen in the Real-Time Data Stream
If you're still analyzing data in batch mode on the back end, you could be further behind the competition than you think. InfoWorld's Andrew C. Oliver explains in a July 25, 2015 article that systems based on streaming analytics may cost more initially, but over time they make much better use of resources. One reason real-time analytics is more efficient is that you're not re-analyzing historic data the way you do with batch-mode analysis.
In a Dr. Dobbs article from November 2012, Nikita Shamgunov distinguishes the scale-out requirements of OLTP and OLAP databases: OLTP is used for real-time transaction processing, and OLAP accommodates analysis of large amounts of aggregate data.
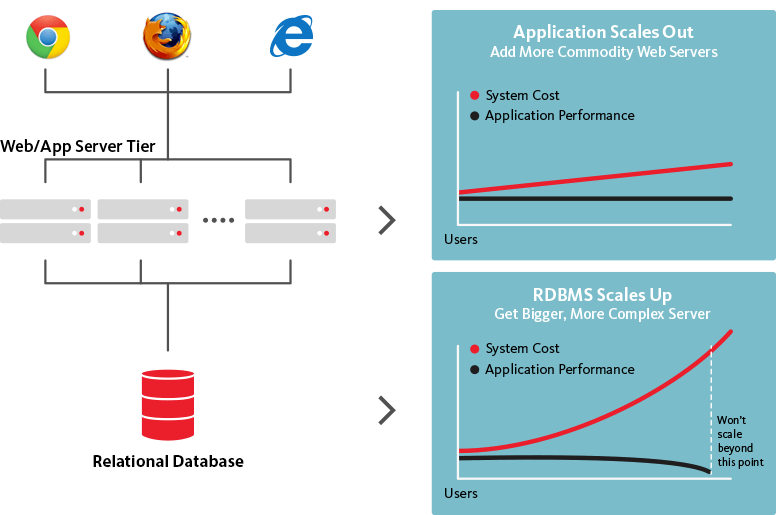
Online analytical processing emphasizes deep dives into large pools of aggregate data, while online transaction processing focuses on many simultaneous data transactions with fewer data demands and shorter durations. Source: Paris Technology.
Scaling OLAP databases relies on these four characteristics:
- Columnar indexes and compression (not specifically scaling out, but they reduce CPU cycles per node).
- Intra-parallel query execution (a scale-up partitioning technique that executes subqueries in parallel).
- Shared-nothing architecture (prevents a single point of contention).
- Distributed query optimization (sends a single SQL query to multiple nodes).
Here are the four considerations for ensuring OLTP databases scale well:
- Don't rely on columnar indexes because OLTP is real-time, and its data records are accessed randomly, which reduces the effectiveness of indexes.
- Parallel query execution is likewise less effective in OLTP because few queries require processing large amounts of data.
- Data in OLAP systems is generally loaded in batch mode, but OLTP data is ingested in real-time, so optimizing bursty traffic is less beneficial in OLTP.
- In OLTP, uptime is paramount; OLAP systems are more tolerant of downtime.
Simple management of SQL, NoSQL, and in-memory databases is a key feature of the Morpheus next-gen Platform as a Service software appliance built on Docker containers. Morpheus supports management of the full app and database lifecycle in a way that accommodates your unique needs. Provisioning databases, apps, and app stack components is simple and straightforward via the intuitive Morpheus interface.
The range of databases, apps, and components you can provision includes MySQL, MongoDB, Cassandra, PostgreSQL, Redis, ElasticSearch, and Memcached databases; ActiveMQ and RabbitMQ messaging; Tomcat, Java, Ruby, Go, and Python application servers and runtimes; Apache and NGINX web servers; and Jenkins, Confluence, and Nexus app stack components.
Published at DZone with permission of Darren Perucci. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments