DDD, Part 2: DDD Building Blocks
Learn about the most important things you need to know about DDD: entities, value objects, aggregate roots, repositories, factories, and services.
Join the DZone community and get the full member experience.
Join For FreeIt’s been a while since I wrote the first part of my DDD series. In this second part, I will continue with one of the most important things to know about DDD before you go further with your implementation. First things first: you must know the DDD building blocks below:
- Entities
- Value objects
- Aggregate roots
- Repositories
- Factories
- Services
Fasten your seatbelts!. We’re going through the details of those blocks now.
1. Entities
An entity is a plain object that has an identity (ID) and is potentially mutable. Each entity is uniquely identified by an ID rather than by an attribute; therefore, two entities can be considered equal (identifier equality) if both of them have the same ID even though they have different attributes. This means that the state of the entity can be changed anytime, but as long as two entities have the same ID, both are considered equal regardless what attributes they have.
2. Value Objects
Value objects are immutable. They have no identity (ID) like we found in entity. Two value objects can be considered equal if both of them have the same type and the same attributes (applied to all of its attributes).
There are often uses for a thing like message passing and in fact, this is particularly useful in the API layer within an onion architecture to expose your domain concepts without necessarily exposing the immutable aspect.
Some benefits of value objects:
- The compound of value objects can swallow lots of computational complexity.
- Entities can be released from logic complexity.
- Improve extensibility, especially for testability and concurrency issues if using correctly.
3. Aggregate Roots
Aggregate root is an entity that binds together with other entities. Moreover, aggregate root is actually a part of aggregate (collection/cluster of associated objects that are treated as a single unit for the purpose of data changes). Thus, each aggregate actually consists of an aggregate root and a boundary. For example, the relationship between Order and OrderLineItem within SalesOrderDomain can be considered as an aggregate where Order acts as the aggregate root, while the OrderLineItem is the child of Order within SalesOrder boundary.
One of the key features of an aggregate root is that the external objects are not allowed to holds a reference to an aggregate root child entities. Thus, if you need access to one of the aggregate root child entities (AKA aggregate), then you must go through the aggregate root (i.e. you can’t access the child directly).
The other thing is that all operations within the domain should, where possible, go through an aggregate root. Factories, repositories, and services are some exceptions to this, but whenever possible, if you can create or require that an operation goes through the aggregate root, that’s going to be better.
4. Repositories
Repositories are mostly used to deal with the storage. They are actually one of the most important concepts on the DDD because they have abstracted away a lot of the storage concerns (i.e. some form/mechanism of storage).
The repository implementation could be a file-based storage, or database (SQL-/NoSQL-based), or any other thing that is related to storage mechanism, such as caching. Any combination of those is also possible.
A repository should not be confused with the data store. A repository job is to store aggregate roots. Underneath that, repositories implementation may actually have to talk to multiple different storage locations in order to construct the aggregates. Thus, a single aggregate root might be drawn from a REST API, as well as a database or files. You may wrap those in something called the data store, but the repository is sort of a further layer of an abstraction on top of all those individual data stores. Usually, I implement the repository as an interface within the domain/domain services layer within onion architecture, and then the implementation logic of the repository interface is going to be defined in the infrastructure layer.
5. Factories
The factories are used to give an abstraction to the object construction (see factory design pattern from GOF).
A factory can also potentially return an aggregate root or an entity, or perhaps a value object.
Often times, when you need a factory method for an aggregate root, it will be rolled into the repository. So, your repository might have a finder create method on it.
Usually, factories also implemented as an interface within the domain/domain services layer with the implementation logic will be defined in the infrastructure layer.
6. Services
A service basically exists to provide a home for operations that don’t quite fit into an aggregate root. As an example, when you have an operation and don’t know which aggregate root it goes into, perhaps it operates on multiple aggregate roots or maybe it doesn’t belong to any existing aggregate root. Then, you can put the logic into a service. However, don’t be rushed to put everything into a service. First and foremost, it's better to carefully analyze whether the operation fits into one of the existing aggregate roots. If you couldn’t find the aggregate root, it's subsequently better to ask yourself if you have missed one aggregate root, or perhaps there are domain concepts that you haven’t considered that should be brought into your domain before you put the operation into a service.
Other Important Things
I often found that many developers use term VO (value objects) and DTO (data transfer object) interchangeably. They think both are just the same. This is quite annoying for me. I’d like to clarify here that both refer to the different things.
As depicted in the picture below, VO and DTO are subsets of a POJO/POCO. An entity is also a subset of POJO/POCO.
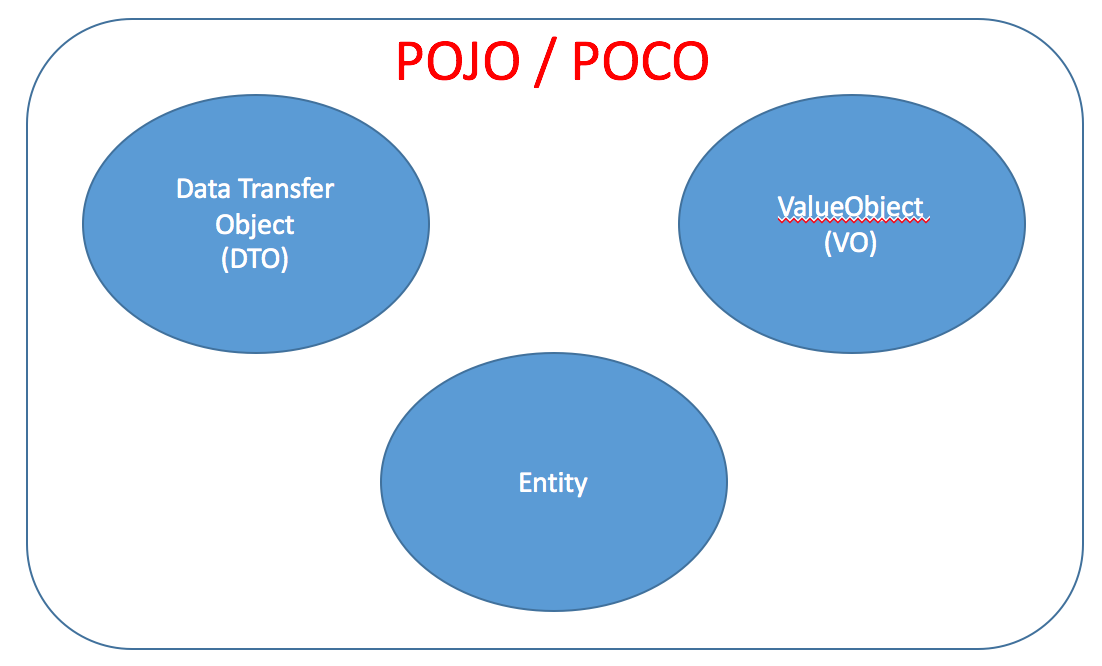
In the above depiction, POJO and POCO can be interchangeably used. Both are referring to similar things. Both are just domain objects that mostly represent the domain/business object within the business application.
The term POJO (plain old Java object) was coined by Martin Fowler and very popular in the Java community, while POCO (plain old CLR object/plain old class object) is widely used in the dotNet.
As mentioned earlier, DTO, VO, and entity are just a subset of POJO/POCO. However, they are really different things as described below:
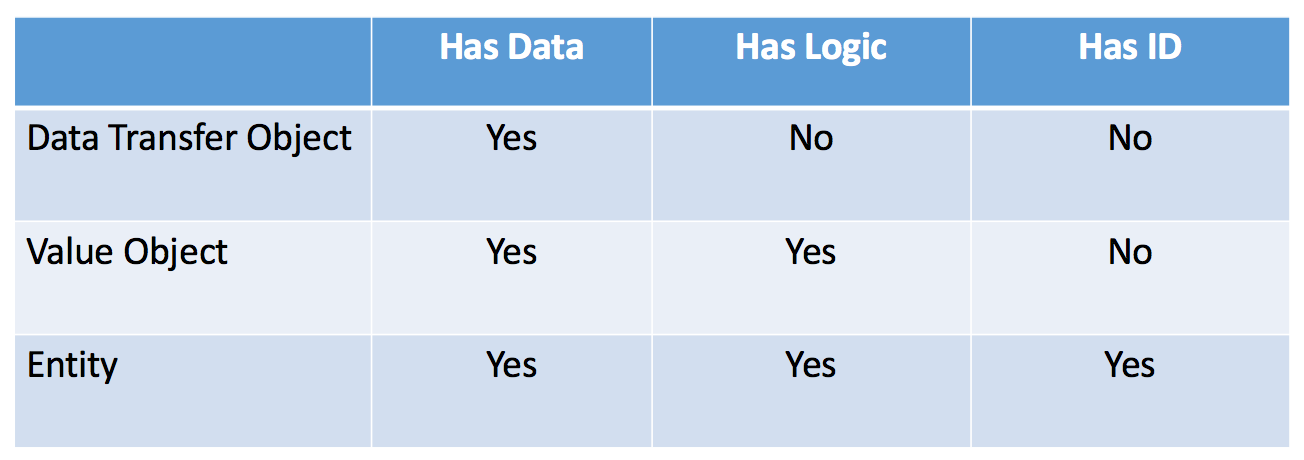
DTO is merely a stupid data container (only holds data without any logic). Thus, it's anemic in general (only contains attributes and getter/setter). DTO is absolutely immutable. Usually, we use DTO to transfer the object between layers and tiers in one single application or between application to application or JVM to JVM (mostly useful between networks to reduce multiple network calls).
VO is also immutable, but what makes it different than DTO is that VO also contains logic.
That’s all for now. Read the next part here.
Published at DZone with permission of M Yauri at-Tamimi. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments