Designing a New Framework for Ephemeral Resources
In this article, we will share the thinking process we underwent while designing this new framework for ephemeral resources.
Join the DZone community and get the full member experience.
Join For FreeWe have recently released our new framework for ephemeral resources, which was the result of a big design effort, going from a deep analysis of the problem to the exploration of multiple solutions.
In this article, we share the thinking process we underwent while designing this new framework, presenting some of the challenges we faced and the solutions we found and providing the reader with a clear idea about the resulting design.
Before getting deep into the details, it is worth commenting that one of the goals we usually try to achieve when introducing changes in our Operator (the software that runs in the user's clusters) is to make them generic enough to allow us to deliver new user-facing features without requiring users to upgrade their operator version every time. Or, in other words, be able to release new features just by introducing changes in our control plane that runs in our cloud (and thus, we have full control over it). We believe it is important to explain this, as you may notice a general tendency in all of our designs and not understand the reasoning behind it.
The Problem
Our alpha version of resources, launched a year ago, was a hook-based framework that defined a container image interface where users had to implement two executables: one for provisioning the resource and another for deprovisioning it. Those custom resource images must be later registered in the corresponding clusters by creating a Resource Plugin CRD object and could finally be referenced from Sandboxes.
Although this solution was generic and flexible, it proved to be too complex for the wider audience. The fact it required building and publishing custom images was a big obstacle for many of our users.
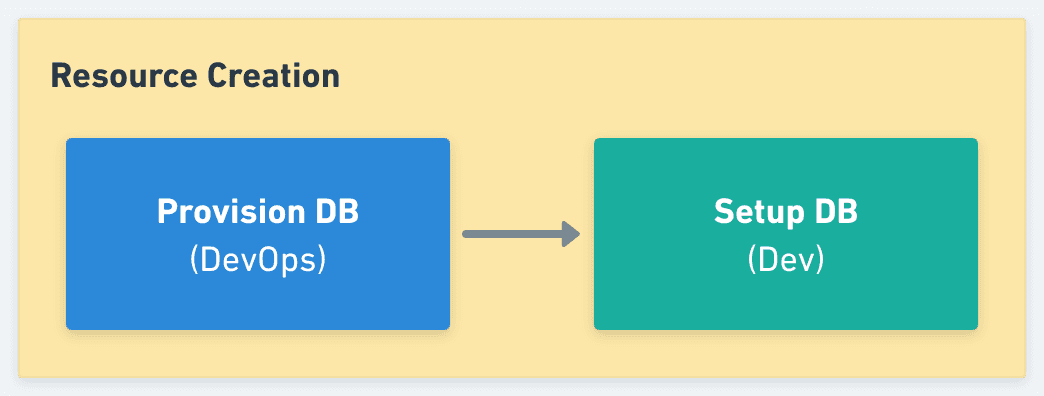
Another observed downside was it didn't offer a clear separation of concerns between what belongs to the Dev vs. to the DevOps team. If you think in the context of Sandboxes, in many cases provisioning a resource is not only making it available but also configuring it to be functional in its context. For example, imagine a microservice that requires a database for reading and writing data. In that case, the resource would be the database, but most likely to be functional within a sandbox (be able to create a fork of the microservice using the provisioned resource), it would require to have a schema defined and maybe some initial data loaded. On one hand, it is clear that the provisioning of the database in itself is a DevOps responsibility (for example, the creation of an AWS RDS instance or the deployment of an in-cluster database). But on the other hand, the creation of the schema, and especially the definition of what seed data is required to properly work, is a Dev concern (for example, one solution could be loading a subset of the data from a staging database).
Another important aspect to consider about the previous point is the rate of changes: while the provisioning logic tends to be very static once defined, the definition of the schema and seeding process may change much more frequently throughout the life-cycle of the microservice. So, in summary, putting these two concerns together within a single image required a tight collaboration between teams, which in many cases became a bottleneck, considerably decreasing the adoption of the resource framework.
The problem to solve was clear, providing a new framework for ephemeral resources as generic and flexible as the first one but without the above downsides.
The Design
Right from the beginning of our design discussions, we all agreed the hook-based model was a good solution for this problem. Ultimately, all we needed was to give users the ability to run their own logic at different points throughout the lifecycle of a sandbox: before starting to create the resource and after termination to delete it. So, what we had to change was the kind of hook accepted by our framework but not the original approach.
On the other hand, we still considered that container-based hooks were the right solution, or at least the first solution to begin with (this is, encapsulating the hook logic within a container that runs as a Kubernetes Pod). But we wanted it to be more declarative and less opinionated: instead of forcing users to build a custom image implementing a certain interface, let them specify what they want to run and how they want to do it. For example, the definition of a hook could look something like:
image: ubuntu
namespace: signadot
script: |
#!/bin/bash
echo "Provisioning my custom resource ..."That would be fairly simple for users to write and wouldn't require building any new images.
Now, an idea we had in mind was: is this hook framework something entirely related to resources, or is this something we could very well use outside the context of resources? And yes, in our view, this framework went beyond the scope of resources and even sandboxes. A generic implementation would allow us, in the future, to run arbitrary hooks related to the lifecycle of entities like route groups, sandboxes, and others. And that, for sure, would be something good to support.
Another topic of discussion was whether we should allow the execution of a single hook for each lifecycle event (preStart and postStop), or if it would be useful to support many. Sometimes it is hard to predict how users will use a given tool, especially in cases like this that are very much open-ended, but if we analyze the problem we previously explained about the separation of concerns between the DevOps and the Dev teams, we can see at least one case where being able to execute two different hooks as part of the same event would be beneficial.
Based on the above, we decided to support multiple hooks per event. What led us to the next decision point, which is: how will those hooks execute? will it be in sequence? in parallel? following other patterns? To answer these questions, we should first focus on a very important concept, that is, the input/output (IO) between hooks and/or related entities. However, before proceeding, let's formalize our design a bit more.
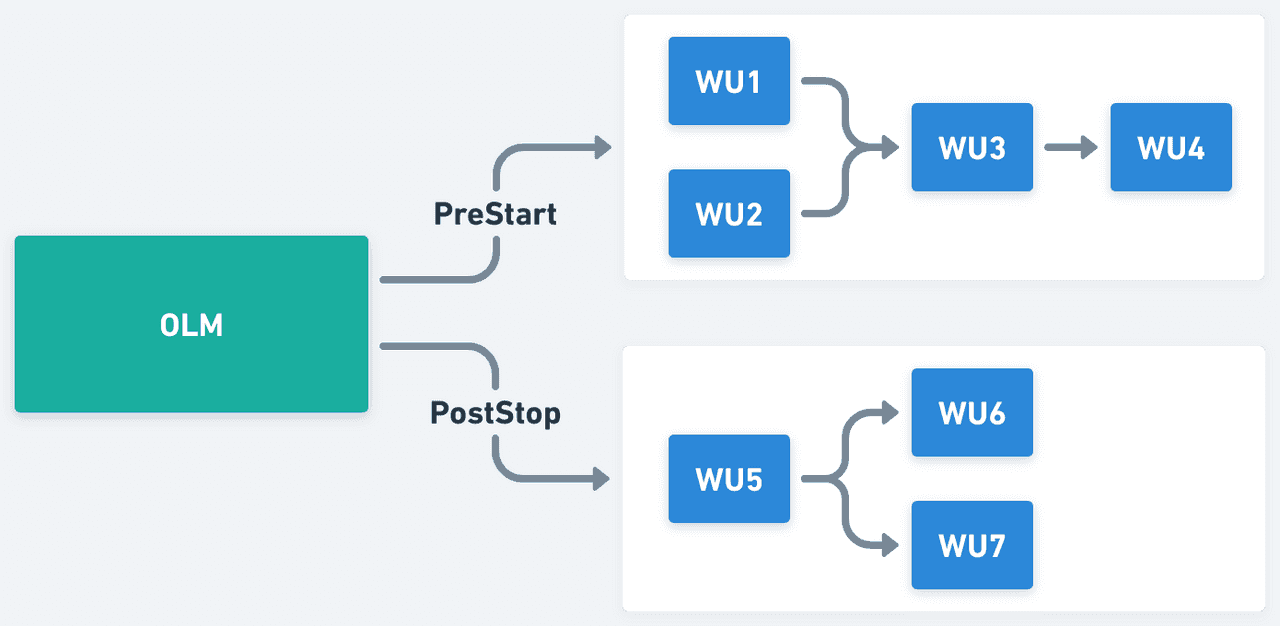
Let’s define an entity called ObjectLifecycleMethods (OLM) that will include a list of OLMWorkUnits for each of the tracked events (so far PreStart and PostStop, but this could be extended in the future if needed). Each OLMWorkUnits will define custom logic to be executed (these are the specific hooks the user wants to run for each event).
We assume there is always going to be an object to which we are connecting our hooks, or in other words; our hooks will always be related to the lifecycle of one specific object (could it be a sandbox, a route group, or others). We will call this object the TargetObject. Then, when using hooks, a TargetObject will own an ObjectLifecycleMethods and will interact with it as needed.

Now, to make this solution really functional, we should allow having IO between OLMWorkUnits. Without that, we would be imposing a big restriction that would drive the usability of this framework to barely just a few use cases.
Based on the previous, let’s consider then that an OLMWorkUnit may consume inputs and produce outputs. But if we think about the data flow in the context of Sandboxes, we will see there could be IO across many different entities.

As presented in the image above, OLMWorkUnits may:
- Receive inputs coming from the sandbox spec (the sandbox YAML).
- Receive inputs produced by other
OLMWorkUnits, even from units across different events. - Send parameters to the sandbox object.
The ability to receive inputs from the sandbox specification provides a good level of parametrization at the resource definition level, which for sure could be very useful.
Let’s now analyze a concrete example to see how all those things fit together.
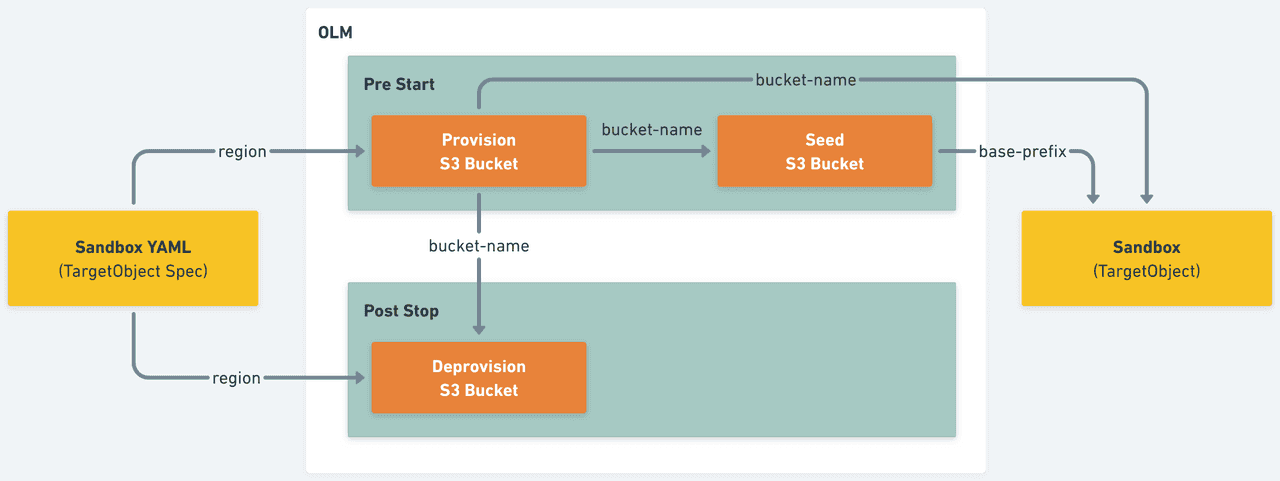
Imagine we need a resource to provision an AWS S3 bucket and seed it by uploading some required files for a microservice to run. We could split the creation of the resource into two different OLMWorkUnits, one that actually provisions the S3 bucket in AWS (a more DevOps-oriented task) and another that runs a script to seed the bucket (Dev will be in charge of this logic). It seems a good idea to receive the AWS region where the bucket will be created as a parameter from the sandbox spec (that way, we can use the same resource implementation across many AWS regions). The “Provision S3 Bucket” step will create the bucket using a random name and will return the bucket name as an output. Next, the “Seed S3 Bucket” step will depend on the “Provision S3 Bucket” and will receive the bucket name as input to upload the needed files. It will also generate an output with the prefix where the uploaded files were located. Now, if we are including this resource as part of a sandbox, it is because we are forking a service that requires it. For this forked service to use the ephemeral bucket, we will need to inject both the bucket name and base prefix as inputs. Finally, once the sandbox is terminated, the "Deprovision S3 Bucket” step will run, which will require the bucket name to remove from AWS.
Having now this IO model clearly defined, we can go back to the question of how to execute OLMWorkUnits for one specific event. We concluded that the execution order of OLMWorkUnits can be defined by their IO dependencies. In the previous example, “Seed S3 Bucket” is run after “Provision S3 Bucket” because there is an IO dependency: the first requires an input produced by the second.
In more technical terms, the OLMWorkUnits configured for one event will form a directed acyclic graph (DAG), where the edges correspond to IO relationships. That DAG will then be used to guide the execution of the different units by following this logic: each unit will be run as soon as all its dependencies have successfully completed or as soon as the event gets triggered in the case of no dependencies.
In short, with this design, we will be executing a workflow for each of the implemented lifecycle events.
Another aspect of the solution is how the ObjectLifecycleMethods relates to sandbox resources. One option we had was to make the Sandbox the owner of an OLM instance, who would be responsible for implementing the corresponding resource. However, we decided that introducing a new Resource entity would be a better and neater approach.

In this design, the Resource is a user-facing entity that provides meaningful information in the context of resources, while the OLM is just an implementation detail. Apart from this, if in the future we keep extending the OLM, for example, by adding support for other life-cycle events like PostStart and PreStop, then not every OLM would be a fit as a Resource. This means that the OLM associated with a Resource could be a more shaped or constrained version than a regular one. Another advantage of this design is it would allow us the implementation of arbitrary hooks at the Sandbox level very easily (let the user run custom logic at different lifecycle events outside the context of resources) just by making the Sandbox have its own version of an OLM. And the same concept would apply to other entities like Route Groups.
Before closing this section, let's analyze how we designed the OLMWorkUnit more deeply. We knew the first kind of hook we should implement was based on running containers. It was "simple," flexible, and powerful. But we could easily foresee other types of hooks which would make a whole lot of sense to support, such as webhooks and, more interestingly, the ability to create arbitrary Kubernetes objects. Imagine someone using Crossplane, where the creation of a resource would just mean creating a Crossplane CRD object, or someone running an Argo Workflow as one of the units. It would be great to support such cases. Of course, in those, the concept of inputs and outputs would still be relevant, but its materialization would be completely different compared to the one with containers. We never intended to exclude the possibility of supporting those hooks. As part of the original design of OLMWorkUnit, we considered the idea of supporting multiple kinds of units. We even considered the possibility of mixing them within the workflow defined for a lifecycle event.
Conclusion
We presented an in-detail view of the design of our new framework for ephemeral resources. We introduced the concept of a generic ObjectLifecycleMethods entity, the base implementation for the resource framework, that could easily be integrated with other entities, providing a rich hooking system. We also presented some of the extensions we could implement in the future, such as: adding support for other lifecycle events, integration with webhooks, Kubernetes native objects, etc.
We hope you enjoyed reading this. If you would like to learn more, check out Signadot's Documentation or join our community Slack channel (you are very welcome there!).
Published at DZone with permission of Daniel De Vera. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments