Building a High-Throughput Distributed Sequence Generator Using the Hi-Lo Algorithm
Design scalable sequential ID generation in distributed systems using the Hi-Lo pattern with Cosmos DB to reduce contention, improve latency, and maintain ordering.
Join the DZone community and get the full member experience.
Join For FreeGenerating sequential numeric IDs sounds like one of those problems that should have been solved decades ago.
And in a monolithic application, it mostly was.
You create a database sequence, use an auto-increment column, and move on. Every new record gets a unique number, the ordering is preserved, and nobody on the engineering team loses sleep over it.
That simplicity disappears the moment the system becomes distributed.
Once your application is running across multiple services, multiple instances, or multiple Kubernetes pods, generating ordered numeric identifiers turns into a very different problem. What used to be a harmless database feature suddenly becomes a scalability bottleneck. Every request that depends on “the next number” now has to coordinate through shared state, and shared state is exactly where distributed systems become expensive.
We ran into this problem while building a service that needed globally unique, monotonically increasing numeric identifiers at very high throughput. UUIDs were not a good fit because the business wanted readable, ordered numbers. At the same time, we could not afford to make a database round trip on every request.
The pattern that solved it cleanly was the Hi-Lo algorithm, backed by Azure Cosmos DB for coordination. It gave us a practical way to preserve uniqueness and ordering while dramatically reducing database contention and keeping request latency extremely low.
Why This Problem Gets Hard So Quickly
The most obvious solution is also the one that fails first under scale.
Store the current sequence value in a database record. For each request, increment it atomically and return the new value. From a correctness perspective, it works. From a scalability perspective, it is painful.
The issue is not that databases cannot increment counters. They can. The issue is that when every service instance depends on the same counter, you create a write hotspot. All traffic funnels through a single piece of mutable state. As request volume grows, latency increases, write contention rises, and horizontal scaling stops helping as much as it should.
You can add more pods, but they are all still lining up to talk to the same centralized counter. That is the point where teams discover that sequential ID generation is not really an ID problem. It is a coordination problem. And in distributed systems, coordination is usually the thing you want to minimize.
Architecture Diagram
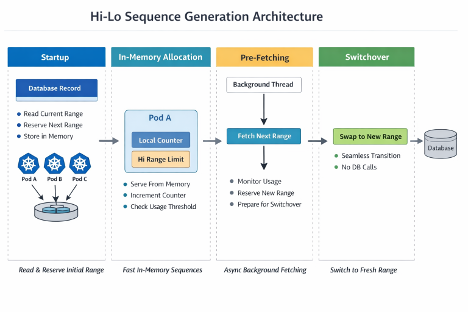
The Idea Behind Hi-Lo
The Hi-Lo algorithm works by separating identifier generation into two layers:
- A high value, reserved centrally
- A low value, generated locally in memory
Instead of asking the database for the next number every time, a service instance reserves an entire block of numbers in one operation. After that, it generates values locally from that reserved range until the block is exhausted.
For example, if the current global boundary is 1000 and the configured lot size is 1000, one pod can reserve the next block: 1001 to 2000. From that point on, it does not need the database for every request. It can serve identifiers from memory until it reaches 2000.
That changes the coordination model completely.
Instead of one database write per ID, the system performs one database write per batch of IDs. If the batch size is 1000, the database pressure drops by roughly a factor of 1000. That is the core advantage of Hi-Lo. It does not make centralized coordination faster. It makes it far less frequent.
Using Cosmos DB as the Source of Truth
In our implementation, Azure Cosmos DB maintains the global upper boundary of allocated ranges.
The coordination model is simple: A pod reads the current boundary, calculates the next range it wants, and tries to update the stored value to reflect the newly reserved upper limit. If the write succeeds, the range belongs to that pod. If it fails because another pod updated the value first, the pod retries.
The important detail is that this is done using optimistic concurrency control through ETag validation.
That gives us atomic range reservation without introducing heavyweight locks or a custom coordination service. Two pods may try to reserve a range at nearly the same time, but only one can successfully update the shared document. The others detect the conflict and try again.
This is exactly the kind of pattern Cosmos DB handles well, as long as the design acknowledges that the shared document is a coordination point and treats it carefully.
We also made a few deliberate configuration choices:
- Session consistency was used to preserve read-your-own-write behavior
- Direct TCP mode helped minimize reservation latency
- Multi-write regions were disabled because monotonic ordering mattered more than geographically distributed writes
That last point is easy to underestimate. If strict ordering is a requirement, you cannot casually spread writes across regions and still assume the sequence semantics will behave the way the business expects.
The Fast Path Is Purely In Memory
Once a pod owns a range, the hot path becomes extremely lightweight.
The service keeps the current range in memory, along with the current pointer and the maximum value of the reserved block. Every request simply increments the local counter and returns the next number.
No network call.
No shared lock.
No database hit.
No cross-pod communication.
That means steady-state performance is not tied to remote I/O. It is essentially the cost of incrementing a number and returning it.
This is where the architecture starts to feel elegant. The database is still the source of truth for range allocation, but it is no longer involved in day-to-day ID generation. The expensive coordination step has been pushed out of the critical request path.
In practice, that made a major difference not just for throughput, but also for latency consistency.
Preventing Pauses With Pre-Fetching
One subtle issue with batch allocation is what happens when the current range runs out.
If the service waits until the final value has been consumed before reserving the next block, some request will eventually have to pay the cost of going back to the database. That creates latency spikes right at the boundary between ranges.
The fix is straightforward: pre-fetch the next range before the current one is exhausted.
In our case, once the service had consumed around 80 percent of the current lot, a background process started reserving the next block from Cosmos DB. That block was stored as a standby range.
When the active range reached its end, the generator simply switched to the pre-fetched range and continued without interruption.
That small design choice helped keep the request path smooth even during transitions. Under stable conditions, callers never noticed when one block ended, and another began.
It also made the system feel much more production-ready. Without pre-fetching, the architecture still works, but the boundary behavior becomes a lot noisier under load.
Handling Contention Without Making It Worse
Even with batched reservation, multiple pods can still collide when they try to reserve ranges around the same time. That is normal.
The key is making sure those collisions stay localized and do not turn into synchronized retry storms.
When a reservation fails because the ETag has changed, the pod retries with:
- A bounded retry count
- Randomized backoff
- Jitter between attempts
The jitter matters more than it might seem. Without it, competing instances can become accidentally synchronized, failing and retrying in lockstep. That creates more contention than the original conflict ever did.
With randomized retry timing, the contention spreads out naturally, and one of the pods usually succeeds quickly.
Most importantly, this contention only occurs during range reservation. It does not happen for every generated ID.
That is a huge shift from the naive design, where every request competes for the same shared state.
What the Performance Profile Looks Like
The performance difference between the two approaches is dramatic.
In a centralized per-request counter design, generating 20,000 IDs per second means 20,000 coordinated database operations per second.
With Hi-Lo and a lot size of 1000, the same throughput requires roughly 20 database reservations per second per pod.
That is not a small optimization. It is a different scaling model.
The practical benefits include:
- Much lower write pressure on the database
- Better request latency
- More predictable tail latency
- Reduced risk of hot partition behavior
- Better horizontal scalability as pods increase
The architecture still has a centralized coordination point, but the frequency of access is reduced so much that it stops being the dominant constraint.
That is often the real win in distributed systems: not eliminating coordination entirely, but moving it off the hot path and amortizing its cost.
The Tradeoff You Have to Accept
Like most scalable designs, this one is not free.
The biggest tradeoff is that the sequence is not gap-free.
If a pod reserves a range and crashes before consuming all of it, the unused numbers in that block are lost forever. The system still guarantees uniqueness and monotonic increase across allocated values, but it does not guarantee perfect continuity with no missing numbers.
For many business cases, that is completely acceptable. For some financial, legal, or regulatory workflows, it may not be. That tradeoff has to be explicit.
There is also a startup dependency on Cosmos DB. A pod cannot safely generate values until it has reserved its first range. In our design, if Cosmos DB is unavailable during initialization, the service fails fast rather than generating inconsistent identifiers.
That is the safer operational choice, even if it is less forgiving.
Where This Pattern Fits Best
The Hi-Lo pattern makes sense when you need all of the following at once:
- Numeric IDs rather than UUIDs
- Global uniqueness
- Monotonic ordering
- High throughput
- Distributed deployment across multiple service instances
It is especially useful in cloud-native systems where a simple database counter becomes a scaling liability.
On the other hand, if your system is low-volume or does not truly need ordered numeric identifiers, this pattern may be unnecessary. Sometimes the better solution is to stop insisting on sequences and use UUIDs or another coordination-free identifier format.
But when the business requirement is real, Hi-Lo is one of the cleanest ways to satisfy it without punishing the system on every request.
Conclusion
One of the most useful lessons in distributed architecture is that performance often improves not when coordination gets faster, but when coordination happens less often. That is exactly why the Hi-Lo algorithm works so well.
By reserving ranges instead of individual values, we turned a centralized bottleneck into an occasional coordination step. Cosmos DB remained the source of truth, but it was no longer involved in every ID request. The hot path stayed local, fast, and predictable.
With in-memory generation, optimistic concurrency, proactive pre-fetching, and jitter-based retries, this approach gave us a sequence generator that was both scalable and operationally practical.
For teams building high-throughput distributed systems that still need ordered numeric IDs, Hi-Lo is one of those patterns that feels almost too simple at first.
Opinions expressed by DZone contributors are their own.
Comments