Don't Make These 10 Kubernetes Mistakes
There are many common Kubernetes mistakes to avoid. We’ve compiled a list, along with solutions and tips to help bypass them.
Join the DZone community and get the full member experience.
Join For FreeDevOps has come a long way, and Kubernetes is quickly taking over the technology world. Kubernetes is an open-source container orchestrator system: it automates the deployment, scaling, and management of containerized applications. It is a powerful tool to manage distributed clusters of containers economically and reliably. While it is considered a sophisticated tool, it can throw challenges at you if it’s not configured correctly. If not taken care of, these Kubernetes mistakes will lead to failures in your production environments.
Understanding the basic architecture and how Kubernetes works is essential in order to avoid these pitfalls. This blog will explore some common mistakes in Kubernetes deployments, how they work, and how you can fix them – or avoid them altogether with some simple tips.
The Basics of Kubernetes
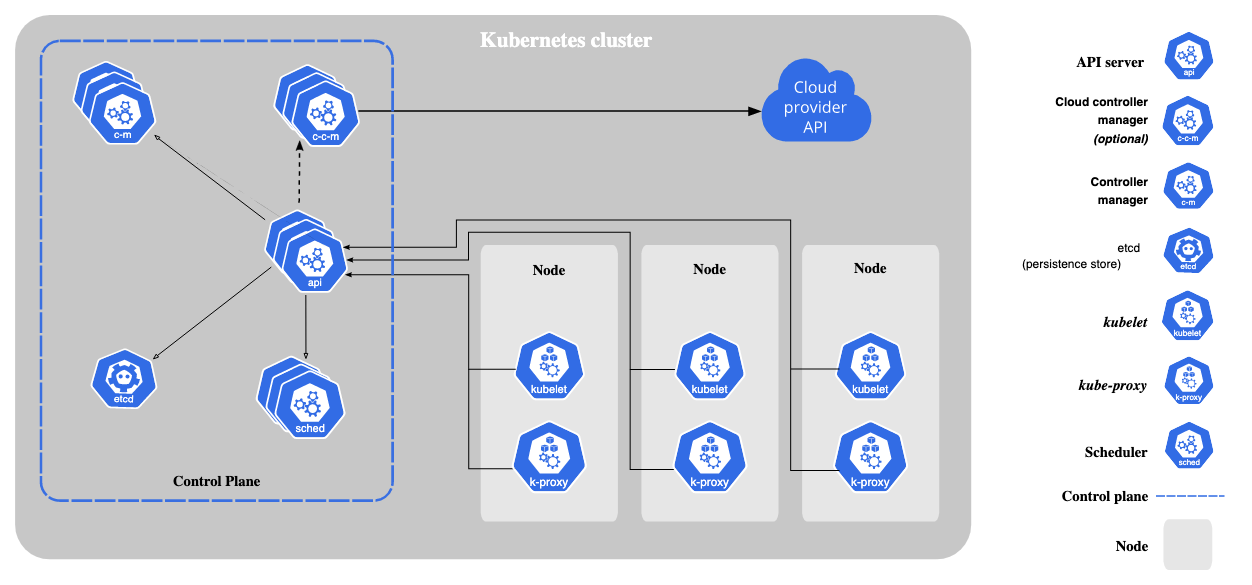
Image Source: Kubernetes.io
Kubernetes is a container orchestration platform. It manages the containers in a cluster with a set of APIs and command line tooling to automate containerized applications’ deployment, scaling, and management. The architecture of Kubernetes consists of a master, and multiple nodes or worker nodes. The master is in charge of the cluster state and nodes’ activities. It also manages the workloads, schedules containers on nodes, and assigns appropriate resources to containers. Nodes can be physical or virtual machines, but they all need access to the Docker engine and kubelet service to work with the Kubernetes cluster. Moreover, a node needs to be connected with other nodes to transmit data between them.
Kubernetes uses a declarative configuration model that makes it easy to design resilient systems to both anticipated and unanticipated changes. With declarative configuration, Kubernetes handles the underlying complexity of containers and cluster operations, making it simple to build clusters with high availability, scalability, and security.
The more complicated your deployment, the more likely you will make one of these mistakes.
1. Ignoring Health Checks

Image Source: Kaizenberglabs
While deploying services to Kubernetes, health checks are very important to help you keep services running as expected. To confirm whether everything is working fine, it is important to know the status of the pods and the overall health of the Kubernetes cluster. To do this, there are startup, liveness, and readiness probes that will help you know the status of your app and the services running inside them. The startup probe ensures the pod is initiated and created successfully. The liveness probe lets us test whether the application is alive. The readiness probe is employed to determine whether the application is ready to receive traffic.
2. Mounting Host File Systems in Containers
Mounting host file systems in containers is a common anti-pattern that leads to many failures. First, it is essential to know that all files created or modified inside the container are not visible to the outside world.
The primary use case for mounting host file systems in containers is persisting data. The simplest way of doing this is by mounting the host’s local directory as one of the directories within the container’s file system. This way, anything written to that directory will be persisted on the host machine. However, mounting your host file system does come with consequences:
- You can’t share state across multiple containers (i.e., you can’t mount two different directories onto two different hosts).
- Any changes on your host’s file system will be hidden from other containers.
- You can’t manage files on any mounted directories without changing their ownership and permissions.
To avoid these consequences, don’t mount any file systems of your host inside a container unless you need them for data persistence purposes.
3. Using the ‘Latest’ Tag
Using the latest tag in production creates chaos.. As it isn’t clear enough about the version and other descriptions, it is not recommended to use it in production. Furthermore, it creates more confusion when things break, and you need to bring things back to the available state as you won’t know what version of the app is running. Therefore, it would be best to always use meaningful Docker tags. Many of us think that the tag ‘Latest’ always points to the newly-pushed version of an image, but that is not the case. By default, the image gets the tag ‘Latest,’ but it doesn’t mean anything.
4. Deploying a Service to the Wrong Kubernetes Node
Kubernetes is a complex system, and one of the most common mistakes beginners make is deploying a service to the wrong node. In Kubernetes, nodes are either master nodes or worker nodes. Every job in Kubernetes has a controller and a scheduler. The controller runs on a master node, and the scheduler runs on a worker node. The master node’s primary function is synchronizing with its corresponding workers and managing cluster-level resources like volumes, network, and persistent data storage.
Worker nodes only run tasks assigned by their masters. This means that if you deploy your service to the wrong node, it may not work correctly – or at all! Also, it will take longer than expected for your new containers to start up, because they will need to wait for an available scheduler to assign tasks before it starts anything else.
To avoid this, you should always know which type of node your services are running on – master or worker – before deploying them. You should also check whether the pod has access to other pods in the cluster that it needs to communicate with before launching any containers.
5. Not Employing Deployment Models
Application deployment is a challenging task for developers, and Kubernetes makes it easy with its numerous deployment techniques. To keep your application available and make sure users don’t get affected by possible downtimes while deploying new software, Kubernetes recommends using deployment strategies: Blue-Green, Canary, and Rolling.

The rolling deployment strategy is the default strategy by Kubernetes that slowly replaces the old pods of the previous version with the pods of the new version.
In a blue-green technique, both blue and green versions get deployed simultaneously, but only one version will be active and live at a time. Let’s consider blue as the old version and green as the new version. So, all the traffic is sent to blue by default at first, and if the latest version (green) meets all the requirements, then the old version traffic is diverted to the new version (from blue to green).
Canary deployment strategy is used to carry out A/B testing and dark launches. It is similar to the blue-green approach but more controlled. We will see slow-moving traffic from version A to version B in this strategy. Think: canary in the coal mine!
6. Duplicated Deployments
One of the most common mistakes in Kubernetes is when a deployment strategy is duplicated. This happens when we create more than one replica of the same state, deployed in parallel to different clusters.
What does this mean? Essentially, this means that if one cluster goes down, the other will continue to process requests for your deployment. However, when they come back up (or if you add them), both replicas will be processing requests and doubling your requests because there are two sets of replicas running. This can be bad news, as it may oversubscribe the CPU and memory on the underlying hosts. To fix this mistake, we would recommend using a service type such as Headless Service or Daemon Set so that only one version of the deployment is running at any given time.
7. Using Only One Kind of Container (i.e., Stateless) in Production Environments
Initially, containers and containerization were designed for stateless applications, but then there went a lot of effort to support stateful applications. With Kubernetes enabling containerization and supporting modern data-driven applications, it has become critical to employ stateful applications.
One common mistake developers make is using only one kind of container – usually stateless – in production environments where they should be using both stateful and stateless containers. Many people mistakenly believe that all containers are the same, but they have significant differences. Stateful containers allow you to store data on persistent storage like disks, which means they’ll never lose data. In contrast, stateless containers will keep their data as long as they’re running, after which it’s lost forever (unless backed up). Hence, it is a good practice to make use of both stateful and stateless containers.
8. Deploying Your Application Without Considering Monitoring and Logging Requirements
Not considering the need for monitoring and logging can be disastrous. With this oversight, developers cannot see how their code or application is running in a production environment.
To avoid this mistake, developers should set up a monitoring system and a log aggregation server before deploying their application on Kubernetes. Once these systems are in place, it’s possible to measure the performance of your application and see what changes you need to make to optimize it for better performance.
Vendor lock-in can occur when you only use the services and tools provided by Kubernetes itself rather than using third-party solutions. For example, you would use a CRI container runtime interface to deploy your container rather than Docker or rkt containers. Also, many developers get into a state of chaos by not having enough capacity in their cluster or by deploying their applications at the wrong time of the day.
9. Deploying Your Application Without Any Security Configurations in Place
When deploying your application, you should always keep security in mind. So what are some of the most important things to consider when it comes to security? For example, using an endpoint accessible outside of your cluster, not securing your secrets, not considering how to run privileged containers, etc. safely.
Kubernetes security is an integral part of any Kubernetes deployment. Security challenges include:
● Authorization – Authentication and authorization are essential for controlling access to resources in a Kubernetes cluster.
● Networking – Kubernetes networking involves managing overlay networks and service endpoints to ensure that traffic between containers is routed securely within the cluster.
● Storage – Securing storage in a cluster consists in providing that data cannot be accessed by unauthorized users or processes and that data.
The Kubernetes API server has a REST interface that provides access to all the information stored. This means that users can access any information stored in the API by simply sending HTTP requests to it. To protect this data from unauthenticated users, you need to configure authentication for the API server using supported methods like username/password or token-based authentication.

It’s not just about securing the cluster itself but also the secrets and configurations on it. To protect the cluster from vulnerabilities, you will need to configure a set of security controls on it. One such robust security control is securing a Kubernetes cluster with RBAC: Role-Based Access Control can be used to secure Kubernetes clusters by limiting access to resources based on roles assigned to users. These roles can be configured as “admin” or “operator.” The admin role has full access rights, while the operator role has limited rights over resources within the cluster. We can control and manage anyone getting access to the cluster by doing this.
10. Not Setting Resource Consumption Limits
If you see your resource utilization and your bills shooting up, then it’s time you take control and determine which services are needed and which ones are not. One way is to perform a stress test against your application.
Then, you can set a limit on the CPU and the memory of containers. Kubernetes defines ‘requests’ and ‘limits’ in its resource utilization category. Requests represent the minimum resources an application needs to run, and limits define the maximum resources. No control over the resources also means we are not monitoring the application. We can specify the resource limits in the deployment YAML.

Harness Cloud Cost Management (CCM) gives suggestions for your Kubernetes clusters by showing resource optimization opportunities to reduce your monthly spending. The recommendations are computed by analyzing your workload’s past utilization of CPU and memory. The implementation uses a histogram method to compute the recommendations.
Conclusion
Kubernetes is great, but the learning curve can be daunting at times. We knew developers were facing issues running Kubernetes, hence, we listed these common mistakes and pitfalls with tips to avoid them so that you can work efficiently with your Kubernetes deployments. Additionally, these mistakes can be avoided by paying close attention to your interactions with Kubernetes and understanding the differences between how it interacts with your deployed services.
Make sure you’re doing your due diligence before your application goes live.
Published at DZone with permission of Pavan Belagatti. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments