DORA Metrics in DevOps
DORA group defined four broad metrics that are now known as DORA Four Keys. Let's use them to measure the velocity and stability of our databases.
Join the DZone community and get the full member experience.
Join For FreeDevOps Research and Assessment (DORA) is a research group in Google Cloud. They conduct a long-running research program trying to assess and understand the velocity and reliability of the software development process. They try to capture what makes teams move fast, how to measure these KPIs automatically, and finally, how to improve based on the captured data.
DORA wrote a famous article in 2020 titled Are you an Elite DevOps performer? Find out with the Four Keys Project. They defined two broad areas — velocity and stability — to measure four important metrics: deployment frequency, lead time for changes, change failure rate, and time to restore service (also known as mean time to recover). These four metrics are now known as DORA Metrics or DORA Four Keys. Even though they later added a fifth metric — reliability, we still start on the four original metrics to assess the performance.
While the metrics focus on software deployments in general, people typically relate them with deploying application code. However, DORA metrics apply to everything that we deploy, including changes around our databases. Just like it’s important to monitor metrics for deploying microservices or applications in general, we should pay attention to everything that affects our databases, including schema migrations, query changes, configuration modifications, or scheduled background tasks. We need to track these metrics since every change in our databases may affect our customers and impact business operations. Slow databases lead to slow applications, which in turn lead to frustrated clients and lost revenue. Therefore, DevOps performance metrics should include metrics from our databases to accurately reflect the healthiness of our whole business. Let’s read on to understand how to achieve that.
Exploring the Four Key DORA Metrics
DORA identified four important metrics to measure DevOps performance. These metrics are:
- Deployment frequency
- Lead time for changes
- Change failure rate
- Time to restore service
Let’s walk through them one by one.
Deployment Frequency
Deployment frequency measures the successful deployments over a given time period. We want to maximize this metric as this means that we have more successful deployments. This indicates that we can get our changes more often to production.
In the database world, this means that we can apply modifications to the database more often. We need to understand that there are different types of changes. Some changes can be applied in a short time, while some other changes will require pushing to production outside of office hours or even taking the database offline. It’s important to understand what we measure and if we need to have different dimensions in this metric.
To improve the metric, we need to make sure that our deployments are fast and do not fail. We need to add automated testing along the way to check all the changes before we try deploying them in production. This includes:
- Code reviews
- Static code analysis
- Unit tests
- Integration tests
- Load tests
- Configuration checks
- Schema migrations analysis
- Other areas of our changes
We may also consider breaking changes into smaller batches to deploy them independently. However, we shouldn’t do that just for the sake of increasing the metric.
Lead Time for Changes
Lead time for changes measures the time it takes a code change to get into production. Let’s clarify some misconceptions before explaining how to work on this metric.
First, lead time for changes may sound similar to deployment frequency. However, lead time for changes covers the end-to-end time it takes to get some changes deployed. For instance, we may be deploying changes daily and have high deployment frequency, but a particular change may take a month to get deployed to production.
Second, lead time for changes measures how fast we can push a change through the CI/CD pipeline to production once we have the change ready. It’s not the same as lead time, which measures the time between opening an issue and closing it.
This metric measures the efficiency of our automated process, mostly our CI/CD pipeline. We can think of it as the time between merging the changes to the main branch and deploying things to production. We want to minimize this metric as this indicates that we can push changes faster.
To improve this metric, we should automate the deployment process as much as possible. We should minimize the amount of manual steps needed to verify the change and deploy it to production. Keep in mind that lead time for changes includes the time needed for code reviews, which are known to slow down the process significantly. This is especially important in the area of databases because there are no tools but Metis that can automatically review your database changes.
Change Failure Rate
The Change failure rate metric measures how often a change causes a failure in production. Even though we reviewed all the changes and tested them automatically, sometimes things break after the deployment. This metric shows at a glance how often that happens, and we want to keep the metric as low as possible.
To improve the metric, we need to understand why things break after the deployment. Sometimes, it’s caused by inefficient testing methods. In that case, we need to improve CI/CD pipelines, add more tests, and cover scenarios that fail often. Sometimes, it’s caused by differences between production and non-production environments like traffic increase, different data distribution, different configuration, parallelism, background tasks, permissions, or even different versions of the database running in production. In that case, we need to focus on replicating the production database in testing environments to find the issues during the CI/CD phase.
It’s important to understand that there is no point in moving fast (i.e., having high deployment frequency and low lead time for changes) if we break things in production. Stability is crucial, and we need to find the right balance between moving fast and still keeping high quality of our solutions.
Time To Restore Service
The Time to restore service indicates how long it takes to recover from a failure in production. We want to minimize this metric.
This metric can be increased by many aspects: long time for the teams to react, long investigation time, long time for applying the fix or rolling back the solution. Since each issue is different, this metric may be prone to high variation.
To improve the metric, we should keep well-written playbooks on how to investigate and fix issues. Teams shouldn’t spend time figuring out what to do. They should have their standard operating procedure written down and accessible whenever the issue pops up. Also, the investigation should be automated as much as possible to save time. We also need good database monitoring to have metrics in place that will fire alarms that will roll deployments back automatically.
In DevOps, studies have indicated that high-performing teams can have a recovery time (the time it takes to recover from a failure) of less than an hour, significantly quicker than lower-performing counterparts that may need 24 hours or more.
Other Metrics
DORA added a fifth metric — reliability — which is now tracked apart from availability in their reports. However, most of the tools and solutions focus on the four key metrics presented above. It’s important to understand that metrics are not the true goal. We want our software to be reliable and always available, and we want the changes to go swiftly and smoothly. Optimizing metrics just for the sake of optimization is not the point.
Implementing DORA Metrics in Your DevOps Practices
Let’s understand how to implement DORA Metrics in your space.
The easiest way to start is to integrate with the Four Keys project. The project provides a solution for measuring software delivery performance metrics and for visualizing them. It’s also worth checking out DORA Presentation Video to see it in action.
In general, we need to have the following elements:
- Signals source
- Metrics aggregation and calculation
- Visualization
- Feedback loop
Let’s see this in some greater detail.
Signals Source
We need to identify sources in our ecosystem and capture their signals. Typical examples of sources are:
- Source control repository: For instance, pull request created, code review created, comments added, or pull request accepted.
- CI/CD pipeline: For instance, tests executed, tests failing, deployments, rollbacks, or alarms.
- Deployment tools like Octopus Deploy: For instance, deployments, rollbacks, or alarms.
- Incidents: For instance, reported issues, triggered alarms, and faulted queries.
However, there are also specific signals around databases that we should capture:
- Configuration changes: For instance, changing parameters, changing
- Schema migrations: For instance, when a migration is triggered.
- Background tasks: For instance, vacuuming, partitioning, and defragmenting.
- Data migrations: For instance, moving data from hot storage to cold storage.
- Queries: For instance, slow queries, deadlocks, and unused indexes.
We need to capture these signals, transform them into a common form, and then deliver them to a centralized store. The Four Keys project can do that automatically from Cloud Build and GitHub events, and it can be extended with more signal sources if needed.
We want to capture signals automatically as much as possible. Ideally, we don’t need to implement anything on our end, but we just want to reuse existing emitters of our infrastructure and frameworks. If we build the code with cloud providers like AWS CodeBuild or Google Cloud Build, then we should capture the metrics using the event mechanisms these infrastructures provide. Same with GitHub, GitLab, or any other build server that we use.
Metrics Aggregation and Calculation
Once we have the signals accessible from one place, we need to aggregate them and calculate the key figures representing our process performance. Here, we calculate all the four metrics we defined in the previous section.
To calculate the metrics, we typically run a daily background job that aggregates the signals, calculates metrics, and exports the results in a form that can be later queried or browsed. This can be a database with all the metrics, JSON files, or some pre-generated dashboards. The Four Keys project includes this part and emits data to BigQuery tables.
We don’t need to come up with custom logic to calculate the metrics. We can use the Four Keys project as our starting point and then adjust as needed. If we emit our signals in the same format as the Four Keys, then we don’t need to modify the code at all to calculate the metrics.
Visualization
Once we calculate the metrics, we can start visualizing them. It’s up to us how we do that, and we can tune this part to our needs. We would like to get dashboards that can be reviewed quickly and can easily show if there are any issues or if we need to focus on improving some metrics. The Four Keys project prepares dashboards like this one:
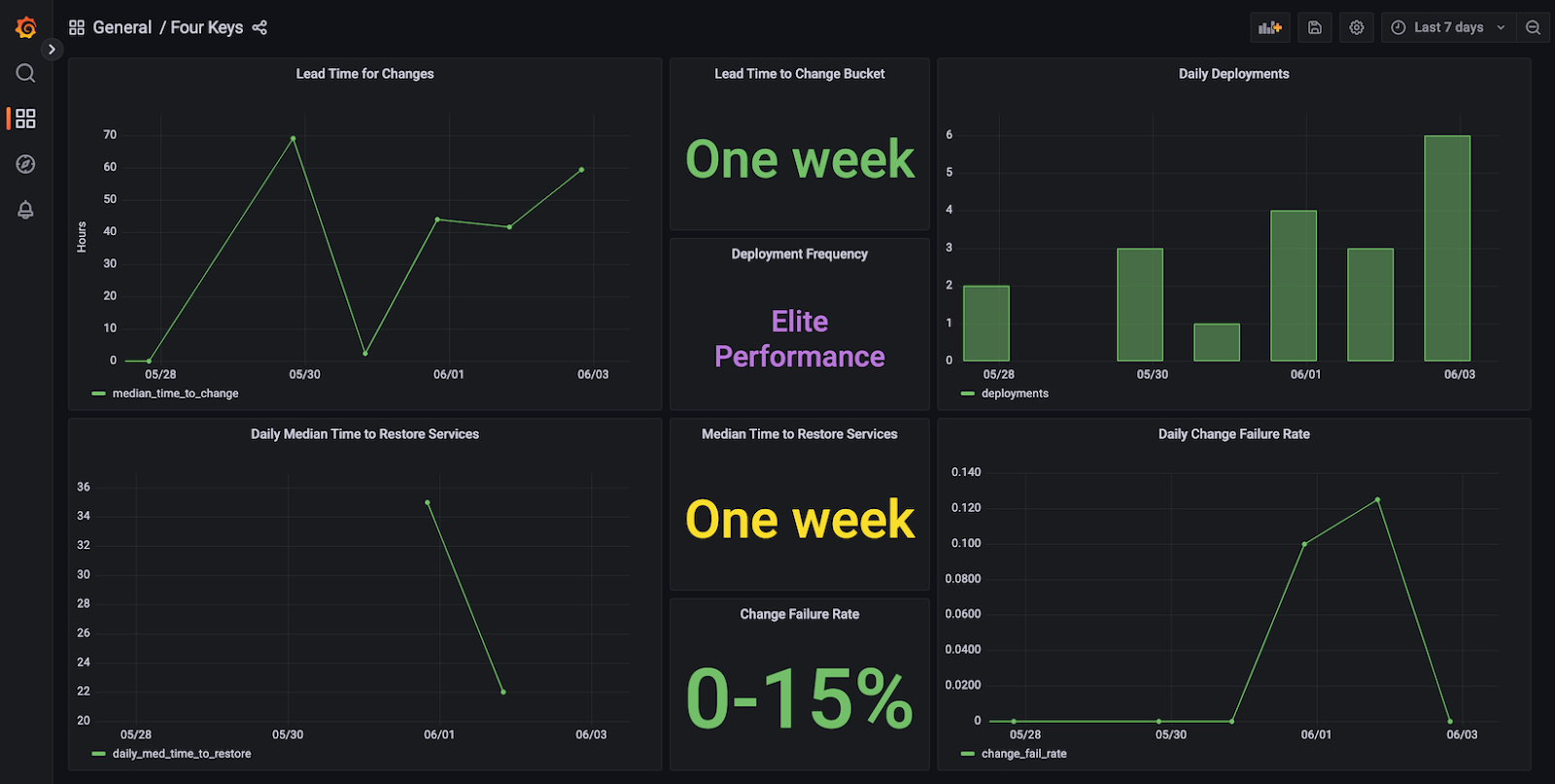
We can see all four metrics presented and some historical data showing how things change over time. We could extend such a dashboard with links to tickets, anomaly detection, or analysis of how to improve metrics.
We should look for a balance between how many details we show on the dashboard and how readable it is. Keep in mind that aggregating data may lead to hiding some issues. For instance, if we take the time to restore service from all incidents and average it, then we will include the long tail that may skew the results. On the other hand, if we ignore the long tail, then we may not see some issues that actually stop us from moving fast. Dashboards need to show enough data to easily tell if all is good, and at the same time, they should enable us to dig deeper and analyze details.
Feedback Loop
Last but not least, we need to have a feedback loop. We don’t track metrics just for the sake of doing so. We need to understand how things change over time and how we can improve metrics later on. To do that, we should build a process to take metrics, analyze them, suggest improvements, implement them, and verify how they affected the pipeline.
Ultimately, our goal is to make our business move fast and be reliable. Metrics can only point us to what can be improved, but they won’t fix the issues on our behalf. We need to incorporate them into our day-to-day lives and tune processes to fix the issues along the way.
Measuring and Improving With DORA Metrics
DORA metrics can show us how to improve processes and technology and how to change the culture within our organization. Since the metrics focus on four key areas (deployment frequency, lead time for changes, time to restore service, and change failure rate), we need to focus on each aspect independently and improve it. Below, we consider some of the strategies on how to use DORA metrics to improve our business.
Automation and Tooling
We want to automate our deployments and processes. We can do that with:
- Continuous Integration/Continuous Deployment (CI/CD): Automate testing, building, and deployment processes to streamline the delivery pipeline.
- Infrastructure as Code (IaC): Automate infrastructure provisioning and configuration, ensuring consistency and repeatability.
- Code quality tools: Use tools for static code analysis, linters, semantic diffs, and theorem provers.
- Database tools: Analyze your databases, focusing on things that often go unnoticed, like slow queries, deadlocking transactions, or unused indexes.
- GitOps: Describe and manage your system declaratively using version control
- NoOps and AIOps: Automate operations to the extent that they are nearly invisible. Use machine learning and artificial intelligence to remove manual tasks.
Culture and Collaboration
DORA metrics can’t be fixed without cultural changes. We need to promote DevOps focusing on shorter communication and faster feedback loops. We can improve that by having:
- Have cross-functional teams: Encourage collaboration between development, operations, and other relevant teams to foster shared responsibility and knowledge.
- Implement feedback loops: Implement mechanisms for rapid feedback and learning from failures or successes.
- Measure and analyze: Continuously measure and analyze metrics to identify bottlenecks or areas for improvement.
- Favor iterative improvements: Use data to iteratively improve processes and workflows.
- Invest in training: Provide training and resources to empower teams with the necessary skills and knowledge.
- Encourage experimentation: Create an environment where experimentation and trying new approaches are encouraged.
- Have supportive leadership: Ensure leadership buy-in and support for DevOps practices and initiatives.
Remember, improvements in DORA metrics often require a cultural shift, where continuous improvement and collaboration are valued. Start with small, manageable changes and gradually scale up improvements as the organization adapts to the new practices.
Reducing Lead Time for Changes
To improve the lead time for changes, we can try the following:
- Smaller batch sizes: Break down work into smaller, manageable chunks to reduce lead time for changes.
- Parallel development: Encourage parallel development of features by different teams or individuals.
- Parallel testing: Run tests early and in parallel. Do not wait with load tests until the very end but start them as early as possible to not block the pipeline.
Improving Time To Restore Service
To improve the time to restore service, we can make the following improvements:
- Monitoring and observability: Implement robust monitoring to detect issues early and facilitate faster troubleshooting.
- Blameless post-mortems: Encourage a blame-free culture to learn from incidents and improve processes without fear of retribution.
- Anomaly detection: Check your metrics automatically to detect anomalies and have low-priority alerts for those.
- Manual reviews: Encourage your stakeholders to periodically review metrics showing business performance to not let any business issues go unnoticed.
- Feature flags and rollbacks: Deploy changes behind feature flags to be able to roll back them much faster.
Reducing Change Failure Rate
To reduce the change failure rate, we need to make sure we identify as many issues as possible before going to production.
- Testing strategies: Enhance testing practices (unit, integration, regression) to catch issues before deployment.
- Feature flags and rollbacks: Implement feature toggles to enable easy rollback of features if issues arise.
- Maintaining documentation: Capture the issues that happened in the past and extend your pipelines to automatically make sure these issues won’t happen again.
Conclusion: The Future of DevOps With DORA Metrics
The future of DevOps with DORA metrics will likely involve a continued evolution towards greater automation, enhanced collaboration, stronger security integration, and a deeper understanding of how to measure and optimize software delivery and operational performance. Flexibility, adaptability, and a culture of continuous improvement will remain key aspects of successful DevOps implementations. We’ll include more and more domains like ML, security, and databases. We’ll also go towards NoOps and replace all manual work with automated machine-learning solutions.
FAQ
What Are the Four Key Metrics of DevOps?
These are:
- Deployment frequency
- Lead time for changes
- Time to restore service (also known as mean time to restore or MTTR)
- Change failure rate
How Does the DORA Framework Improve DevOps Performance?
DORA Metrics improves DevOps performance by providing a structured approach to measure and assess key metrics associated with software delivery and operational excellence.
What Is the Role of Continuous Deployment in DevOps?
Continuous deployment is a practice that focuses on automating the deployment of code changes to production or a live environment after they pass through the entire pipeline of tests and checks. It improves the business by automating the release process, enabling frequent and reliable software deployments.
How Do You Calculate Lead Time for Changes in DevOps?
The lead time for changes in DevOps represents the duration it takes for a code change to move from the initial commit (when the change is introduced) to its deployment in a production environment.
What Strategies Reduce the Change Failure Rate in DevOps Environments?
Reducing change failure rate in DevOps environments involves implementing strategies that prioritize reliability, risk mitigation, and thorough testing throughout the software delivery lifecycle. Automate your tests, remove manual steps, test early, and test often.
How Is the Mean Time to Recover Crucial for DevOps Success?
In essence, a lower MTTR is indicative of a more responsive, efficient, and resilient DevOps environment. It's not just about reacting quickly to incidents but also about learning from them to prevent similar issues in the future, ultimately contributing to the success of DevOps practices and the overall stability of systems and services.
What Tools Are Used for Measuring DORA Metrics?
The most important is the Four Keys project. However, we can build our own pipelines with any tools that allow us to capture signals from CI/CD and deployment, aggregate these signals, calculate metrics, and then visualize the results with dashboards.
Published at DZone with permission of Adam Furmanek. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments