dovpanda: Unlock Pandas Efficiency With Automated Insights
DovPanda is a tool that helps you write efficient Pandas code. It provides real-time suggestions to improve your code, automate data profiling, validation, and cleaning.
Join the DZone community and get the full member experience.
Join For FreeWriting concise and effective Pandas code can be challenging, especially for beginners. That's where dovpanda comes in. dovpanda is an overlay for working with Pandas in an analysis environment. dovpanda tries to understand what you are trying to do with your data and helps you find easier ways to write your code and helps in identifying potential issues, exploring new Pandas tricks, and ultimately, writing better code – faster. This guide will walk you through the basics of dovpanda with practical examples.
Introduction to dovpanda
dovpanda is your coding companion for Pandas, providing insightful hints and tips to help you write more concise and efficient Pandas code. It integrates seamlessly with your Pandas workflow. This offers real-time suggestions for improving your code.
Benefits of Using dovpandas in Data Projects
1. Advanced-Data Profiling
A lot of time can be saved using dovpandas, which performs comprehensive automated data profiling. This provides detailed statistics and insights about your dataset. This includes:
- Summary statistics
- Anomaly identification
- Distribution analysis
2. Intelligent Data Validation
Validation issues can be taken care of by dovpandas, which offers intelligent data validation and suggests checks based on data characteristics. This includes:
- Uniqueness constraints: Unique constraint violations and duplicate records are identified.
- Range validation: Outliers (values of range) are identified.
- Type validation: Ensures all columns have consistent and expected data types.
3. Automated Data Cleaning Recommendations
dovpandas gives automated cleaning tips. dovpandas provides:
- Data type conversions: Recommends appropriate conversions (e.g., converting string to datetime or numeric types).
- Missing value imputation: Suggests methods such as mean, median, mode, or even more sophisticated imputation techniques.
- Outlier: Identifies and suggests how to handle methods for outliers.
- Customizable suggestions: Suggestions are provided according to the specific code problems.
The suggestions from dovpandas can be customized and extended to fit the specific needs. This flexibility allows you to integrate domain-specific rules and constraints into your data validation and cleaning process.
4. Scalable Data Handling
It's crucial to employ strategies that ensure efficient handling and processing while working with large datasets. Dovpandas offers several strategies for this purpose:
- Vectorized operations: Dovpandas advises using vectorized operations(faster and more memory-efficient than loops) in Pandas.
- Memory usage: It provides tips for reducing memory usage, such as downcasting numeric types.
- Dask: Dovpandas suggests converting Pandas DataFrames to Dask DataFrames for parallel processing.
5. Promotes Reproducibility
dovpandas ensure that standardized suggestions are provided for all data preprocessing projects, ensuring consistency across different projects.
Getting Started With dovpanda
To get started with dovpanda, import it alongside Pandas:
Note: All the code in this article is written in Python.
import pandas as pd
import dovpandaThe Task: Bear Sightings
Let's say we want to spot bears and record the timestamps and types of bears you saw. In this code, we will analyze this data using Pandas and dovpanda. We are using the dataset bear_sightings_dean.csv. This dataset contains a bear name with the timestamp the bear was seen.
Reading a DataFrame
First, we'll read one of the data files containing bear sightings:
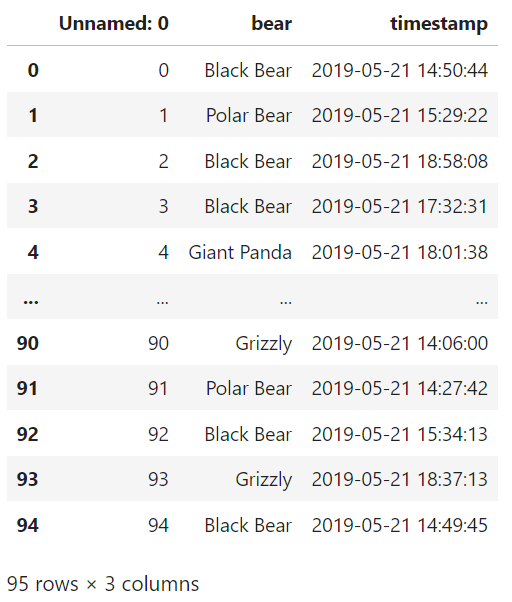
sightings = pd.read_csv('data/bear_sightings_dean.csv')
print(sightings)We just loaded the dataset, and dotpandas gave the above suggestions. Aren't these really helpful?!
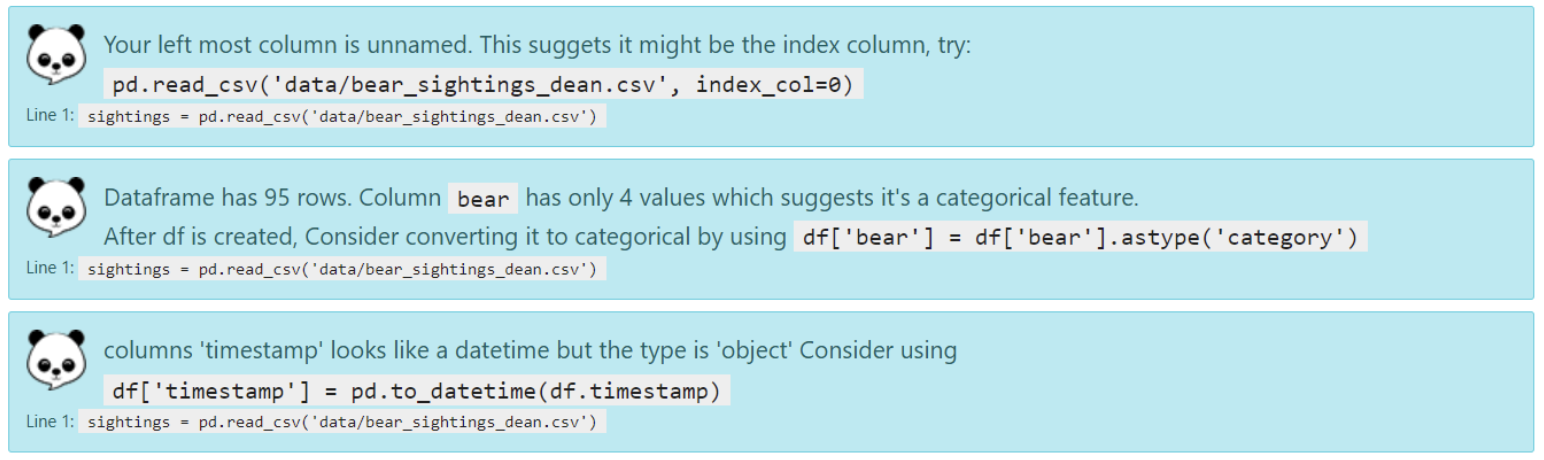
Output

The 'timestamp' column looks like a datetime but is of type 'object'. Convert it to a datetime type.
Let's implement these suggestions:
sightings = pd.read_csv('data/bear_sightings_dean.csv', index_col=0)
sightings['bear'] = sightings['bear'].astype('category')
sightings['timestamp'] = pd.to_datetime(sightings['timestamp'])
print(sightings)The 'bear' column is a categorical column, so astype('category') converts it into a categorical data type. For easy manipulation and analysis of date and time data, we used pd.to_datetime() to convert the 'timestamp' column to a datetime data type.
After implementing the above suggestion, dovpandas gave more suggestions.
Combining DataFrames
Next, we want to combine the bear sightings from all our friends. The CSV files are stored in the 'data' folder:
import os
all_sightings = pd.DataFrame()
for person_file in os.listdir('data'):
with dovpanda.mute():
sightings = pd.read_csv(f'data/{person_file}', index_col=0)
sightings['bear'] = sightings['bear'].astype('category')
sightings['timestamp'] = pd.to_datetime(sightings['timestamp'])
all_sightings = all_sightings.append(sightings)In this all_sightings is the new dataframe created.os.listdir('data') will list all the files in the ‘data’directory.person_file is a loop variable that will iterate over each item in the ‘data’directory and will store the current item from the list. dovpanda.mute() will mute dovpandas while reading the content.all_sightings.append(sightings) appends the current sightings DataFrame to the all_sightings DataFrame. This results in a single DataFrame containing all the data from the individual CSV files.

Here's the improved approach:
sightings_list = []
with dovpanda.mute():
for person_file in os.listdir('data'):
sightings = pd.read_csv(f'data/{person_file}', index_col=0)
sightings['bear'] = sightings['bear'].astype('category')
sightings['timestamp'] = pd.to_datetime(sightings['timestamp'])
sightings_list.append(sightings)
sightings = pd.concat(sightings_list, axis=0)
print(sightings)sightings_list = [] is the empty list for storing each DataFrame created from reading the CSV files. According to dovpandas suggestion, we could write clean code where the entire loop is within a single with dovpanda.mute(), reducing the overhead and possibly making the code slightly more efficient.
sightings = pd.concat(sightings_list,axis=1)
sightingsdovpandas again on the work of giving suggestions.
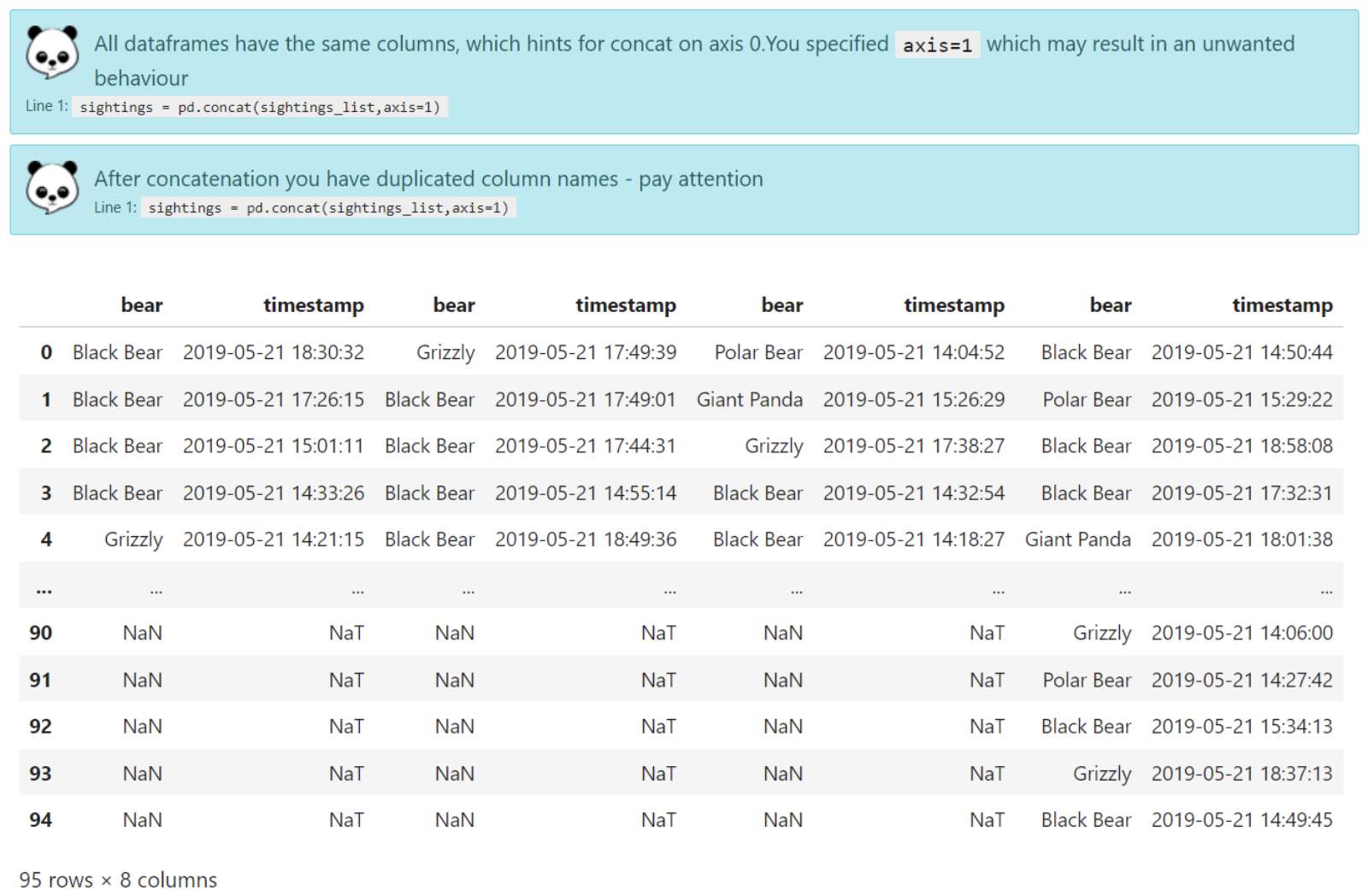
Analysis
Now, let's analyze the data. We'll count the number of bears observed each hour:
sightings['hour'] = sightings['timestamp'].dt.hour
print(sightings.groupby('hour')['bear'].count())Output
hour
14 108
15 50
17 55
18 58
Name: bear, dtype: int64
groupby time objects are better if we use Pandas' specific methods for this task. dovpandas tells us how to do so.

dovpandas gave this suggestion on the code:

Using the suggestion:
sightings.set_index('timestamp', inplace=True)
print(sightings.resample('H')['bear'].count())Advanced Usage of dovpanda
dovpanda offers advanced features like muting and unmuting hints:
- To mute dovpanda:
dovpanda.set_output('off') - To unmute and display hints:
dovpanda.set_output('display')
You can also shut dovpanda completely or restart it as needed:
- Shutdown:
dovpanda.shutdown() - Start:
dovpanda.start()
Conclusion
dovpanda can be considered a friendly guide for writing Pandas code better. The coder can get real-time hints and tips while doing coding. It helps optimize the code, spot issues, and learn new Pandas tricks along the way. dovpanda can make your coding journey smoother and more efficient, whether you're a beginner or an experienced data analyst.
Opinions expressed by DZone contributors are their own.
Comments