Building V1 Gen-AI Products at Scale: Technical Product Patterns That Work
Shipping Gen-AI V1 requires modular systems, grounding, evaluation, and infrastructure planning, treating it as a product, not a prototype.
Join the DZone community and get the full member experience.
Join For FreeShipping the first version of the Gen-AI product is not only a technical problem but a systems-level event. Coordinating the product, infra, security, design, and executive layers when doing it in the enterprise or a consumer-grade setting is necessary. This is especially true when the product interacts with real users and serves in a business-critical environment.
This is not a testbed prompt with an open-source LLM. This is a real-world deployment; at this scale, every minute of latency and every hallucination incurred ceases to be some model parameter and becomes a business liability.
Understanding the True Nature of a Gen-AI “V1”
Gen-AI product is not a prototype or lab demo. It is the minimum viable baseline that can receive interaction with production traffic without upsetting core trust expectations. That means the responding party must be auditable, latency must be predictable, and teams must be ready to iterate on the model behavior and supporting systems.
For example, Amazon Rufus is a Gen-AI-powered shopping assistant. Its launch wasn’t only about producing clever chat completions. It still had to obey business constraints, reflect accurate product information, and run via malls known to search for personalization and compliance services. The design was based on the underlying architecture required for structured and unstructured data, providing fallback modes for low-confidence completions and enforcing security and content policies. In Gen-AI, that’s what a genuine V1 looks like.
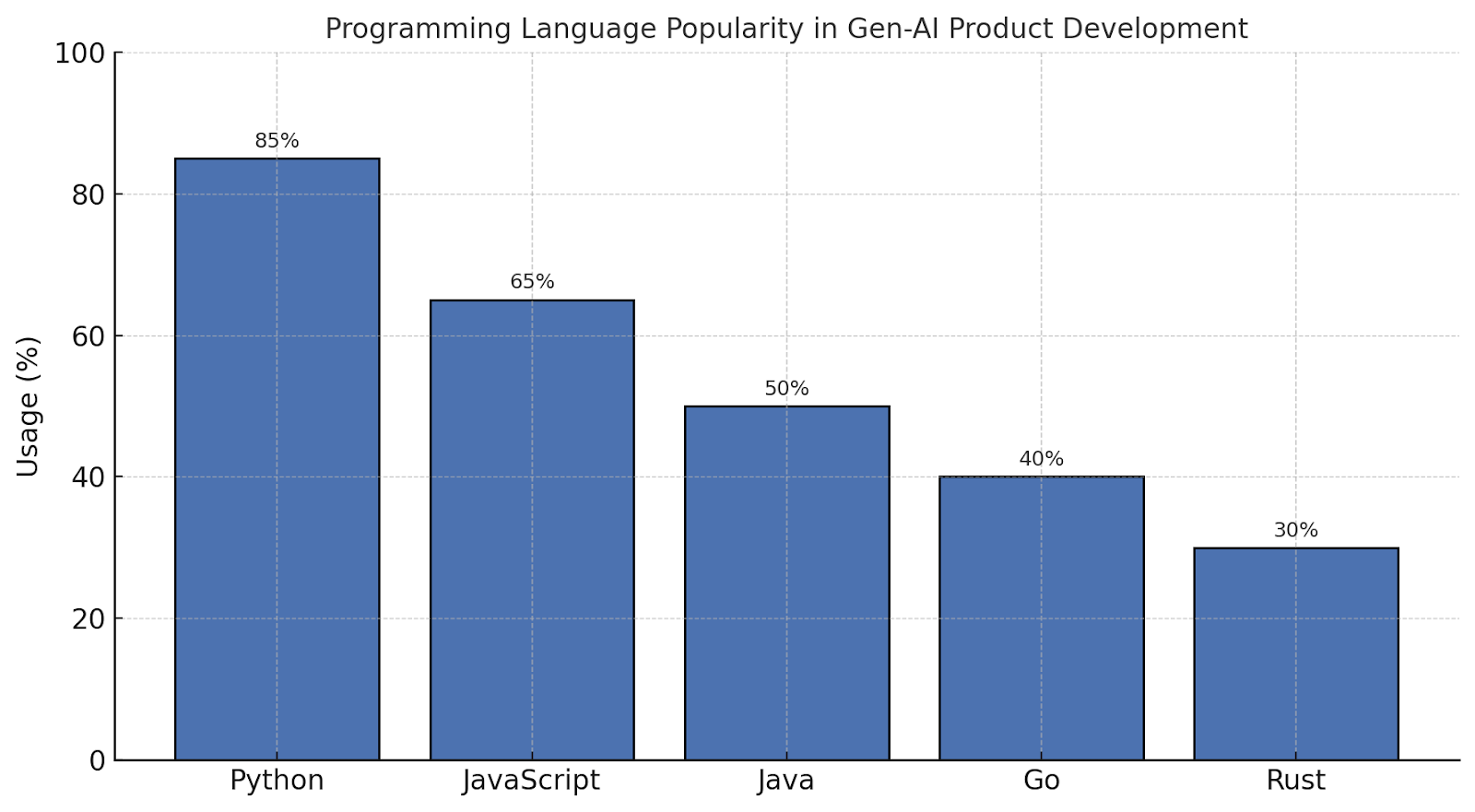
Why One-Shot Architectures Collapse Quickly
Once you bring a model to production, the myth that you can wrap a single endpoint around a model and claim your product is Gen-AI dies quickly. Therefore, most implementations start with a monolithic orchestration service that binds constructive prompt together, grounding, inference, and post processing into one block. Friction, however, increases with use.
Within weeks, the system ran into issues in one Gen-AI product for a top-tier e-commerce platform. As new models were tested and prompts changed, the architecture needed to separate orchestration logic, grounding services, rate control, and failover flows. The lesson: A V1 system must be modular even if there is a feeling of overbuilding early on. Without that flexibility, feature development stalls as every change creates regression risks elsewhere.
Treating Grounding as a Production-Grade Subsystem
It is not optional to ground a model’s output with enterprise-grade data. Reliability is the foundation of making a Gen-AI system work. Today’s product assistants that hallucinate prices, stock availability, or features create immediate escalation dangers to their customer trust and legal exposure for the company.
One example is that a major retailer had to rebuild their grounding pipeline after internal tests exposed inconsistent attribute recall across product lines, including multiple sub-criteria. In this respect, they reimplemented the query time data access layer and the structured slot alignment in prompts and implemented nightly diff audits to validate grounding fidelity. Without these pipelines being viewed as production services, the assistant would have continued to hallucinate fact-based answers, eroding trust one user at a time.
Evaluation Isn’t Just for Models; It’s for Products
Gen-AI systems break traditional product testing patterns. You don’t simply test for endpoints and latency; you must also test the semantic alignment between what users are attempting to do and what the model outputs. It is about capturing data from live sessions, detecting discrepancies in tone, correctness of material, and helpingness, and building a system that understands why something did not produce an output, not merely that it did.
The evaluation system was built as a closed loop within the user interface in one enterprise platform. Confusing or misleading responses were automatically sent back to an offline reranker, which fed them into real users, who could flag them. Tuning signals were fed into the scores of outputs against reference completions, thereby learning a reranker. It wasn’t glamorous, but it ensured that the product remained on point with user expectations even though as models change over time, the product's behavior can drift.
Infrastructure as a Product Constraint, Not a Platform Concern
A significant change for teams is that inference infrastructure isn’t someone else’s problem. In Gen-AI V1, model latency, provider rate limits, and GPU availability directly determine the user experience. If your product is cold or overloaded, your model slows down. Your budget bleeds when token usage spikes.
In one situation, an internal Gen-AI agent aimed at helping sales teams falter under deteriorated latency during quarterly end pushes. It wasn’t a model issue; it was an overcrowding issue. In response, the team routed high-priority traffic to a lower latency distilled model, queued the longer inference tasks in batches for summarization, and continued the snappiness of the experience. The re-architecture became resilient but not at the expense of a massive hardware investment.
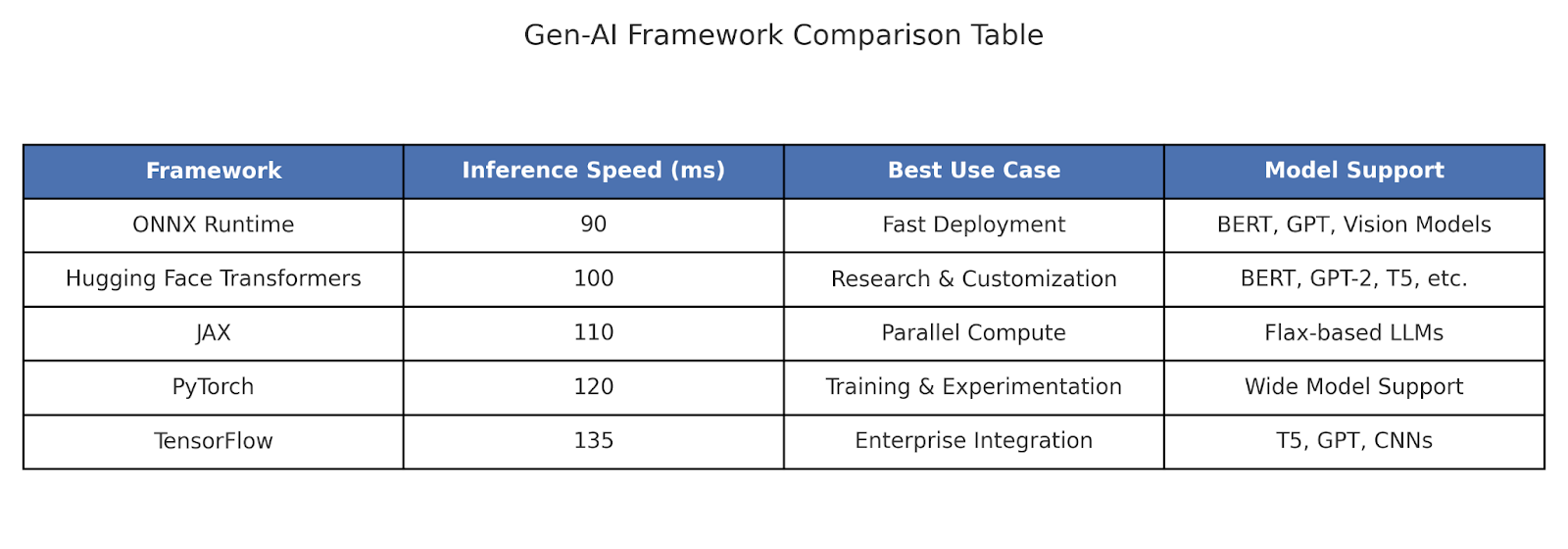
Dealing With Hallucinations Means Building for Refusal
These drifted outputs will occur even in the best grounded systems. What should your product do then? Gen-AI is non-deterministic. It will fail; if that happens, it should not hurt the user.
In high-sensitivity domains like finance or health, the systems that perform best are those that know when to say nothing. One successful model deployed within a healthcare search portal used a multi-layered refusal framework. It first ran a classifier to score factual alignment completions. Following that, it applied category-level filters and rejected suggestions in high-risk situations unless they could be validated against curated content. It wasn’t perfect fluency; it was reliable silence when it mattered.
Conclusion
Building a V1 Gen-AI product isn’t about delivering a sleek interface or a clever prompt; it’s about solving for system behavior at scale. The teams that succeed don’t treat Gen-AI like a special project; they treat it like a system that will outgrow its assumptions within weeks.
That means grounding pipelines must be tested like APIs, evaluation must be a product discipline, product managers must understand infrastructure, and hallucinations must be assumed, not wished away. The V1 launch isn’t your last chance to get it right; it’s your first chance to make the hard decisions visible and build a system that will keep learning along with its users.
Opinions expressed by DZone contributors are their own.
Comments