I Misunderstood Scalability in a Distributed System
Is a system scalable? Answering this question seems pretty straightforward. But we mostly get it wrong. Not any longer. Read more to find out.
Join the DZone community and get the full member experience.
Join For Free"Is the application scalable?" asked the manager. It was almost halfway through the weekly system roadmap meeting. I thought we were done with all the tech parts and would soon move to business-related questions.
The architect of my team cleared his throat and answered, "It can easily handle double the usual load."
The manager gave a long look as if he didn't believe the answer. But, in the absence of any better points, he continued with further updates. I implicitly believed that our system is indeed scalable. After all, the architect had announced it in clear terms.
A year down the line, I learned the truth. One fine day, the system crashed due to excessive load.

The bank had launched a new loan product for the holiday season. The business strategy paid off and there was a surge in demand. Since our application provided the core data to make the credit decision, it was swamped with 5 times more incoming requests from several other applications.
We added more CPUs to handle the load on our service. The same strategy had worked the last couple of times. However, this time it didn't.
Our system was scalable until it no longer was.
Upon analysis, we found that the issue wasn't entirely in our application code. Our application was made up of multiple services that connected with the bank's central database. The connection to the database was made using a connection pool.
Our fault was that we were careless about the number of open connections. Turns out, the database administrations were not.
The DBAs had a hard block on the number of open connections for our group of applications. When the incoming requests to our application surged, we ended up acquiring even more connections until we hit the wall. No matter how many additional CPUs we added to increase the application capacity, it didn't make any difference.
To add insult to injury, the DBAs refused to increase the permissible number of connections. The only option left was a costly change to our application to handle connections properly. For all practical purposes, our system was no longer scalable.
Of course, it was our mistake. We should have accounted for the limited number of connections and used them wisely. Nevertheless, the problem was not unfixable. But the change wasn't cost-effective.
Though the situation was ultimately handled, it piqued my interest in the subject. We thought the system was scalable. But it wasn't. At least not until we hit the connection limit.
It was clear we were wrong about the true meaning of scalability. I decided to dig deeper into the whole situation. My initial motivation was to avoid getting into the same situation as my team's architect
The Usual Definition of System Scalability
Scalability is one of the fundamental challenges in building distributed systems.
While studying scalability for distributed systems, the most common definition I have come across is as follows:
Scalability is the ability of the system to handle an increased workload.
How does this definition apply in real life?
Developers of an actively used system monitor its workload levels. They create processes for predicting when the performance of the system will become unsatisfactory. The goal is to increase the system's capacity before the danger level is reached.

In this approach to scalability, the primary focus is to determine an interval of demand within which the system will perform at an acceptable level. If this interval is sufficiently large, the system is considered scalable.
In my view, this definition is pretty limited. The focus of this definition is always on the workload.
The main concern of this definition is that a system is scalable if it continues to perform adequately as the workload grows. No attention is given to how a system will have to be modified to keep the performance at the same level.
As we found in our case, our system could have continued performing at a good level. But the changes required on the database side were not acceptable. Neither was changing the code cost-effective.
The common scalability definition pays no attention to the approach of capacity increase or its overall impact on the system. We don't ask important questions such as:
- Will doubling the number of processors allow the system to handle double the workload?
- Is the overhead of coordinating work between processors going to be prohibitively high?
In defense of the definition, it is the most common definition used by system designers and developers. We hear it all the time when someone says that a system is scalable and it can handle double the workload with no problems.
Scalability by Extension
In my quest to understand scalability, I came across another definition of scalability that often gets neglected. However, I have come to believe that it may be far more important in practical situations.
Scalability is the ability to handle an increased workload by repeatedly applying a cost-effective strategy for extending a system's capacity.
Straight away, the focus shifts towards the strategy for adding capacity.
We are no longer interested in a one-time capacity increase to improve scalability. We are interested in a strategy for adding capacity and the number of times the strategy can be applied cost-effectively.
This line of thought always makes me think about world-class tennis players like Rafael Nadal or Roger Federer. Over the years, how many times have players like Nadal or Federer adapted their playing style to the changing demands of the game?
Many times, I reckon.
Each change they made prolonged their careers and made them more successful.
However, making a change is not easy. Many players rise to the top and fizzle out because they could not adapt. Even the best players are bound to face difficulties in trying to adapt. The easier it is for a player to make changes, the higher the probability for that player to maintain his dominance in the game.
The same goes for scaling a system.
When we consider the second definition of scalability, we start considering other types of arguments about our system.
- If we add more processors to increase capacity, what is the method for coordinating work between the added processors?
- Will the coordination method take more processing cycles?
- If yes, the full benefit of adding capacity won't be realized. Hence, adding processors beyond a certain point may not be a cost-effective approach to improving scalability.
Focusing on the repeated application of a scaling strategy makes us more cognitive of our choices.
For example, replacing an O(n^2) with an O(nlogn) algorithm makes it possible to process a larger workload in the same amount of time. In other words, replacing an algorithm with a more efficient one improves the system's scalability.
But can we use this approach repeatedly? I don't think so.
Once we have the most efficient algorithm in place, the algorithmic replacement strategy stops being viable. You cannot keep applying the strategy again and again to improve the system's scalability.
Is a System Scalable?
Armed with the two definitions of scalability, I was finally able to make sense of the fundamental question. This was the same question that popped up in our meeting and was answered inadequately.
To answer the question, we end up labeling a system as scalable or not. In my view, this is an oversimplification.
What Does It Mean for a System To Be Scalable?
Most systems scale in some sense. However, no system is infinitely scalable.
So how should we approach scalability?
Theoretical Approach
Rather than labeling systems, it is more fruitful to compare the scalability of two different systems. Consider the below graph that shows the response vs demand curves for two hypothetical systems A and B.
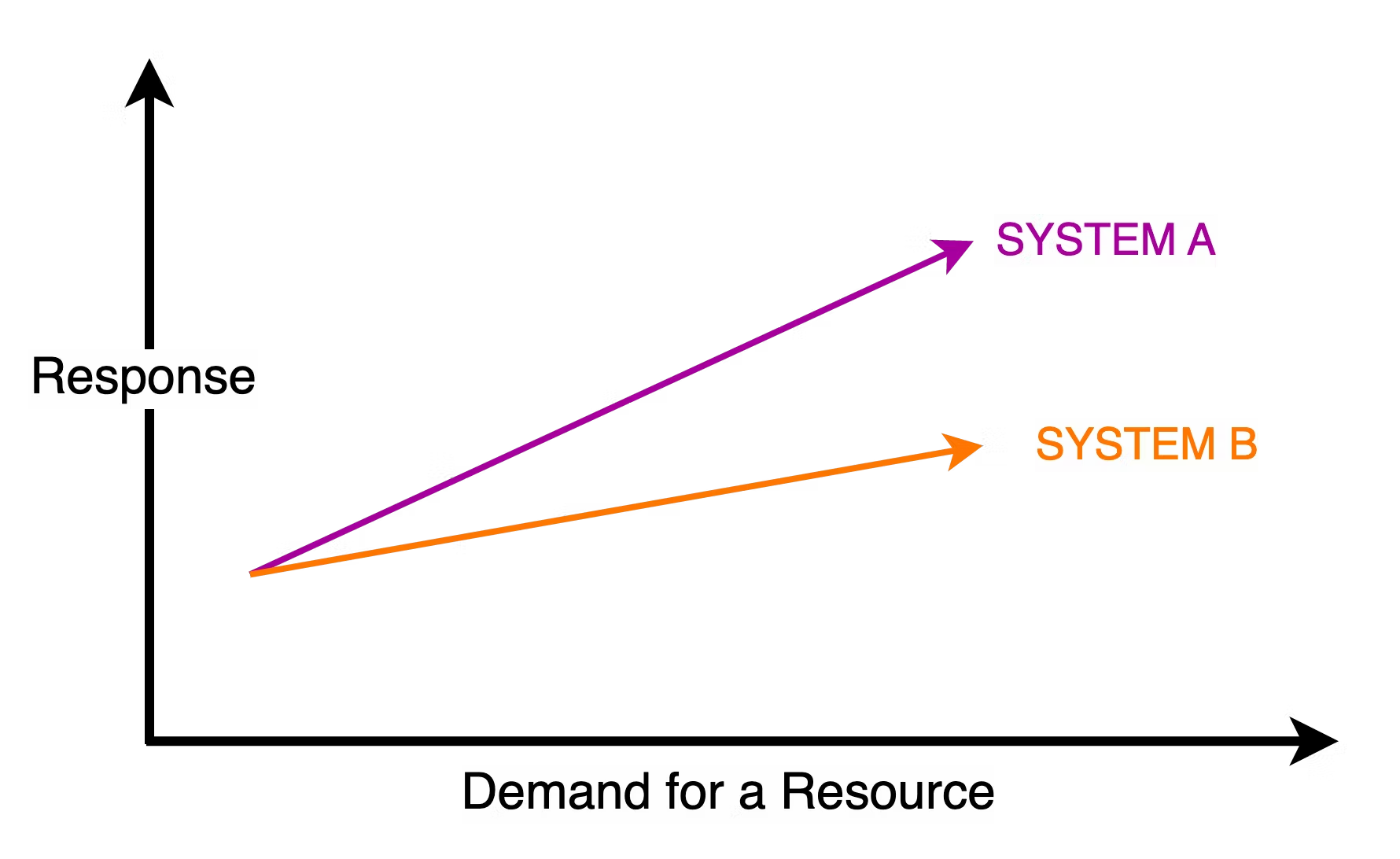
For any given demand level, the response is worse for System A as compared to System B. If there is a maximum tolerable value for the response, System A will reach it earlier than System B.
System B is more scalable than System A.
Of course, if both lines continue to rise at the same monotonic rate, they will eventually reach a point where the demand for resources exceeds their availability. At that point, the response times will become unsatisfactory for both systems. Though the points may be different for A and B, they signify the limit of a system's scalability.
Remember - no system is infinitely scalable.
Systems do not follow a monotonic rate of increase in response vs demand metric. The curve looks more like the below example.
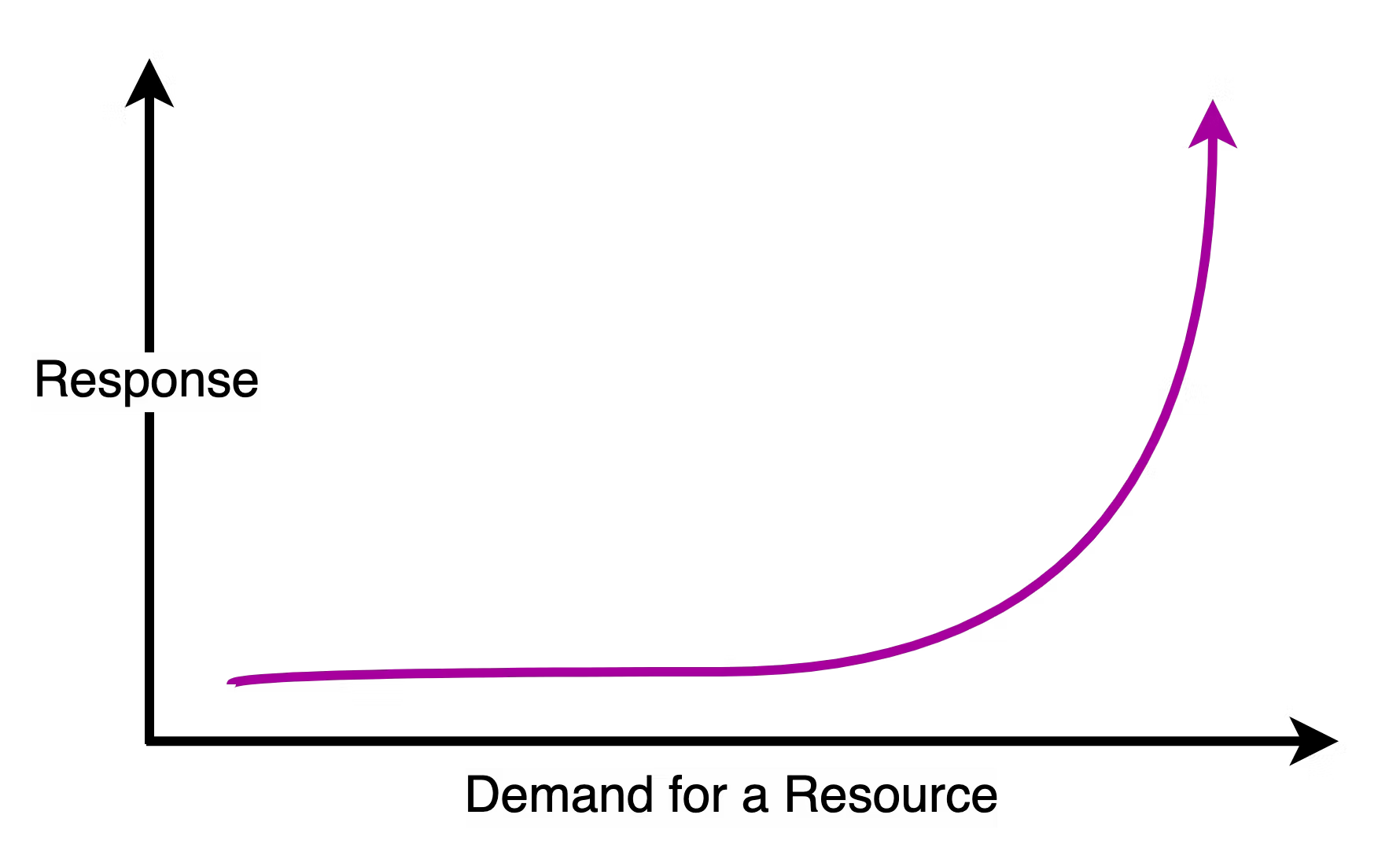
The hypothetical system tolerates demand increase quite well until it hits a significant design limitation. This limitation forms a knee-like shape in the response demand curve. After crossing a particular demand level, the response metric simply goes out of hand.
The goal of designers is to keep the knee of the curve as far to the right as possible. Once a system reaches closer to the knee, it is no longer scalable. Any increase in demand will push it down the hill.
Practical Approach
The theoretical aspects of scalability were genuine eye-openers for me. But I still thought something was missing.
I couldn't completely relate the above graphs to our system. We were able to scale our system successfully during the initial days whenever there was a general increase in load. Things went south only when we hit the database limit.
This behavior does not fit into either of the two theoretical models to depict scalability.
How To Classify This Behavior
Most real system exhibit a more hybrid behavior. The below graph shows this:
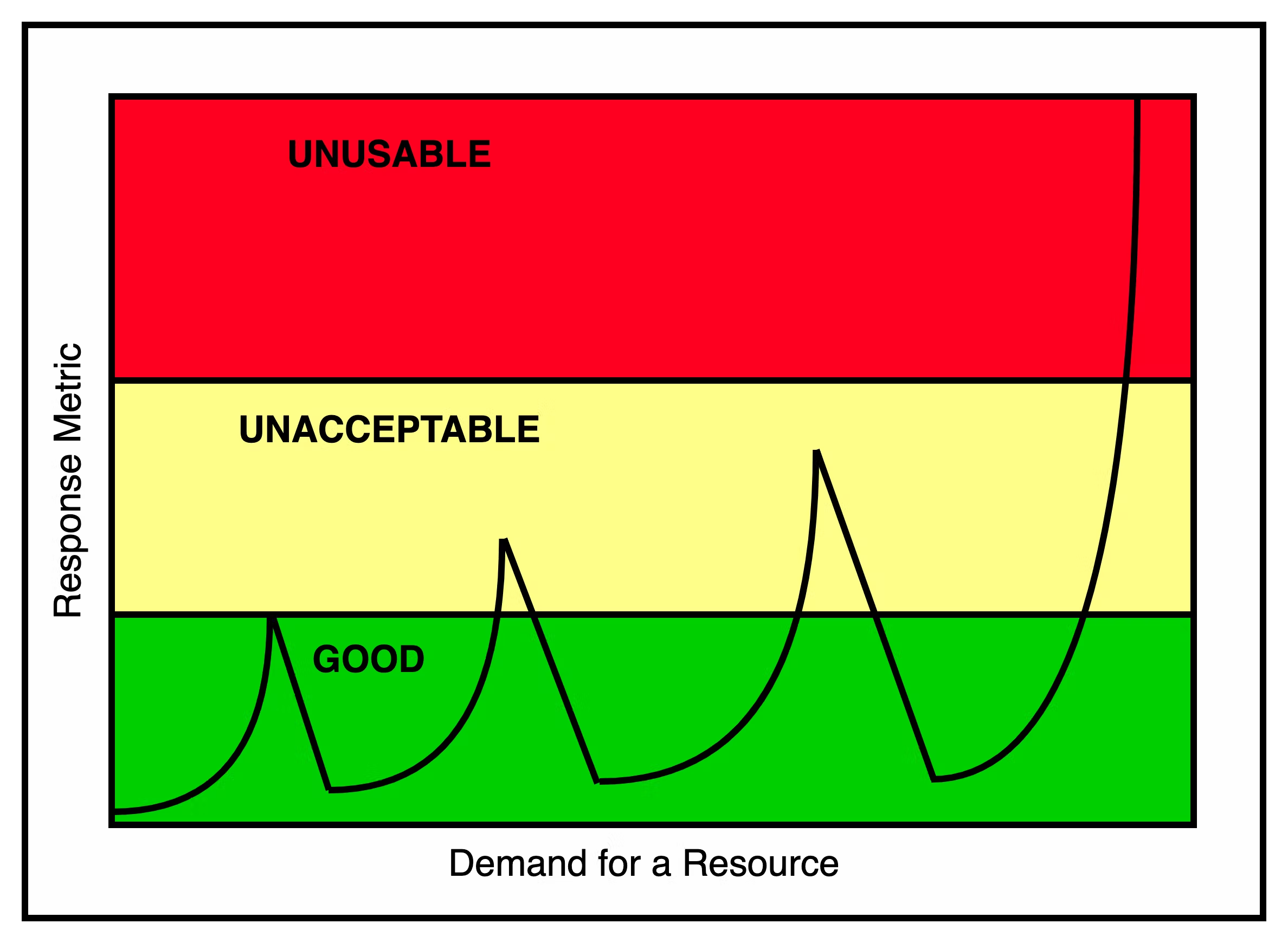
When a system is running in the bottom green zone, it is responding well. As it begins to linger in the middle zone (shown in yellow), the response starts to get unacceptable. When it finally crosses into the top zone (shown in red), the system becomes unusable.
In my opinion, this is a more accurate representation of the second definition of scalability.
- On the first couple of occasions, the system designers were able to take quick action to keep the response within acceptable limits. It was probably a matter of adding additional memory.
- On the third occasion, the designers needed more time and effort to bring the response metric down to acceptable levels. The changes needed to improve the response were probably more complicated.
- In the last case, the system reached a point where no reasonable solution was possible to keep the response times from becoming unusable. The system was no longer scalable using the cost-effective techniques that worked the initial few times.
The above turn of events also depicts the situation of our system. Even though we were able to keep our system scalable for some time, it ultimately reached a point beyond which any cost-effective solution was not possible.
So, is the system scalable?
The answer is - it depends! And not in a cop-out sort of way.
Scalability is more of a moving target that evolves rather than a fixed state.
If the system owner can afford to continue pouring money to meet the higher demand levels, the system is scalable up to a certain point. Beyond this point, no cost-effective action can alleviate the response metric issues.
If the system owner has no money to purchase additional resources at the first very hiccup, the system is not scalable.
Whatever the case, no system is infinitely scalable.
Concluding Thoughts
My journey to understand the true meaning of scalability led to some important conclusions.
In my view, you cannot simply slap a label of scalability on a system and call it a day.
All systems are scalable to some extent. But it does not mean that you can continue scaling them indefinitely in a cost-effective manner.
An ideal scalability situation requires a nuanced approach to system design. Only focusing on adding resources to improve scalability is a trap. You also need to consider the cost-effectiveness of the additional resource.
With this post, my goal was to bring this perspective to the discussion.
Do share your thoughts in the comments section below.
Published at DZone with permission of Saurabh Dashora. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments