Introducing Cloudera SQL Stream Builder (SSB)
SSB is an improved release of Eventador's SQL Stream Builder with integration into Cloudera Manager, Cloudera Flink, and other streaming tools.
Join the DZone community and get the full member experience.
Join For FreeCloudera SQL Stream Builder (SSB)
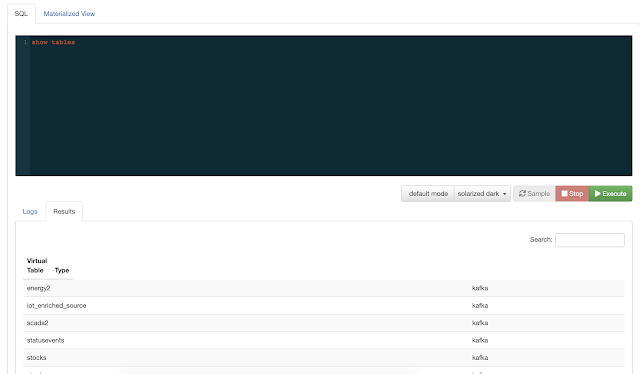
The initial release of Cloudera SQL Stream Builder as part of the CSA 1.3.0 release of Apache Flink and friends from Cloudera shows an integrated environment well integrated into Cloudera's Data Platform. SSB is an improved release of Eventador's SQL Stream Builder with integration into Cloudera Manager, Cloudera Flink, and other streaming tools.
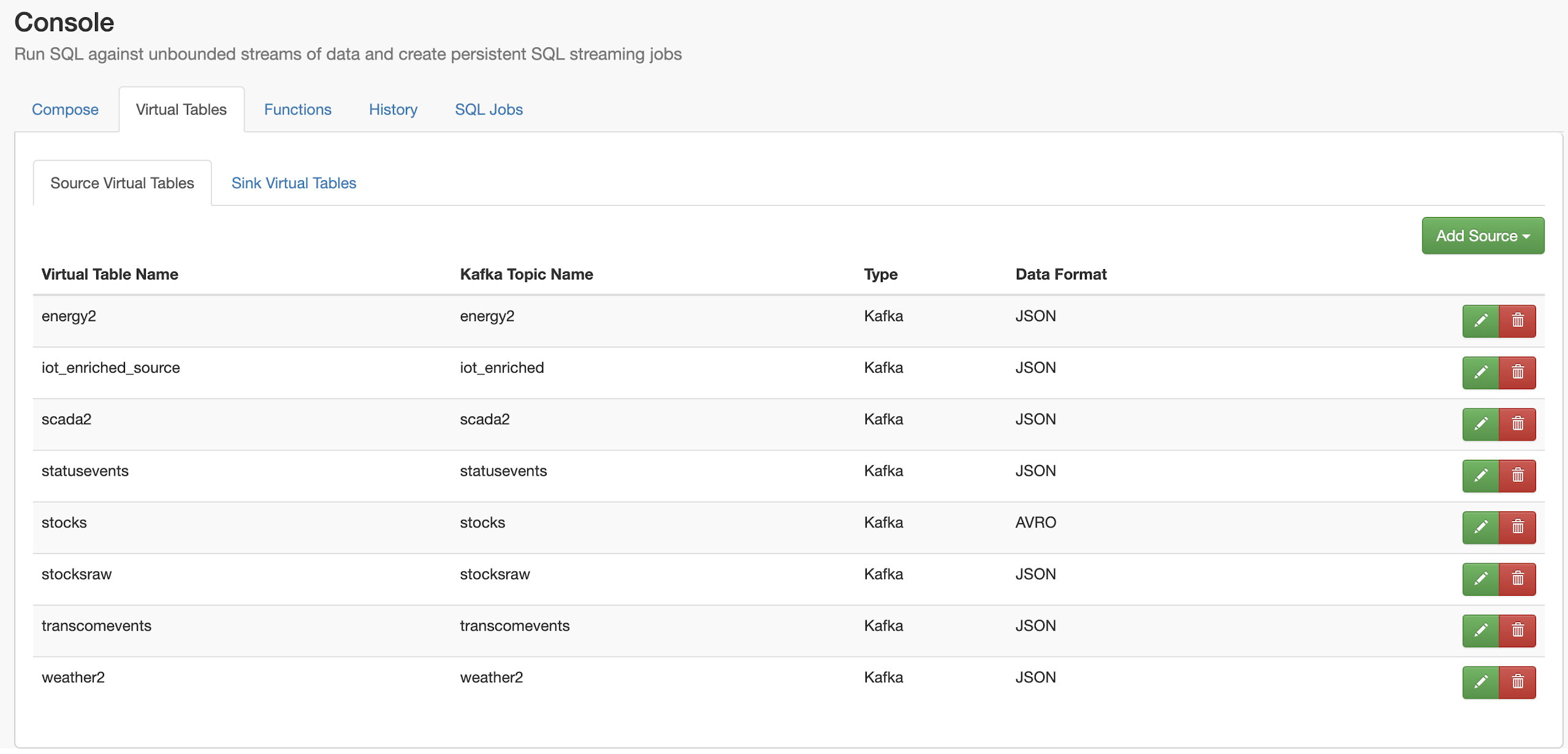
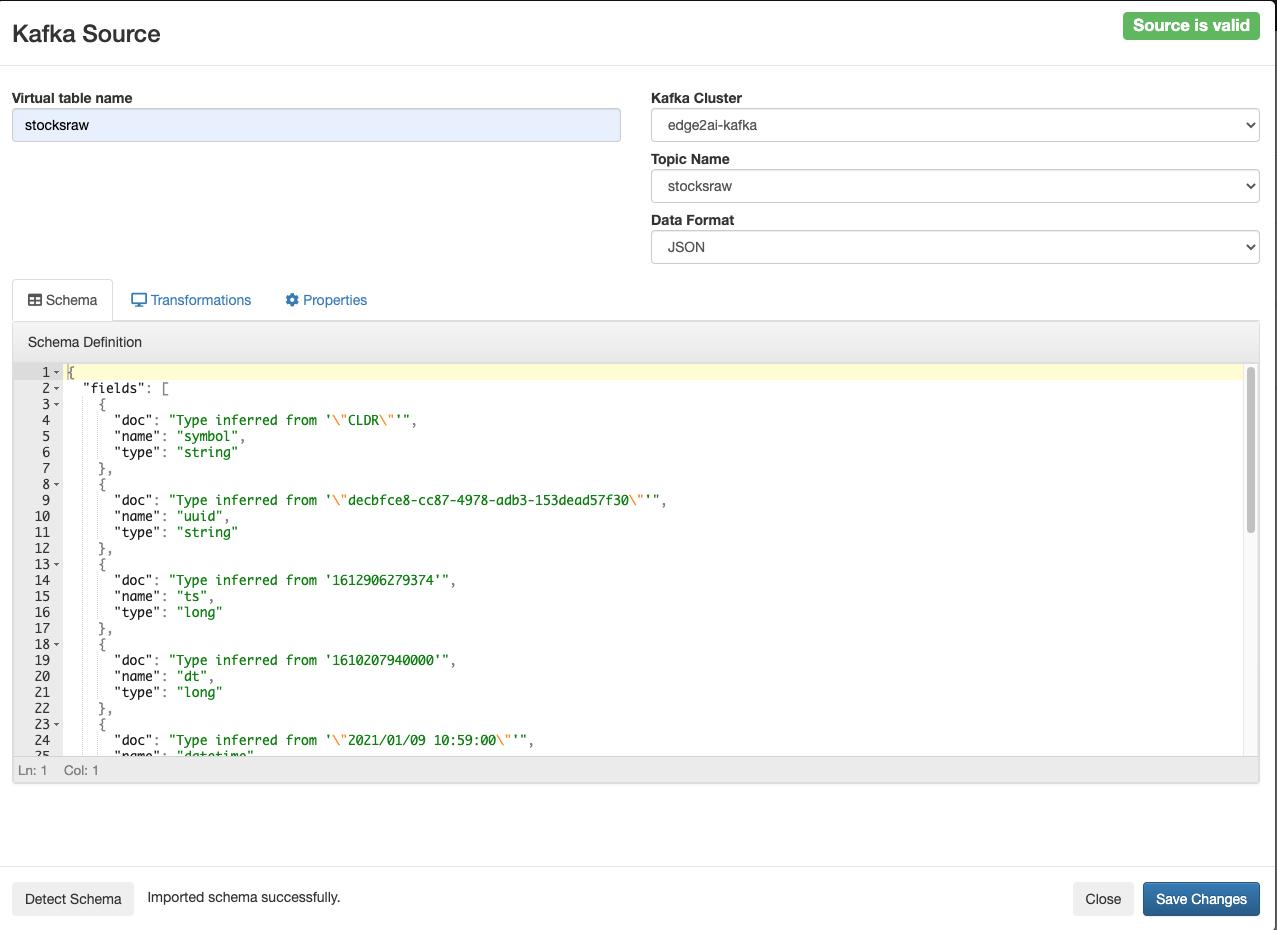
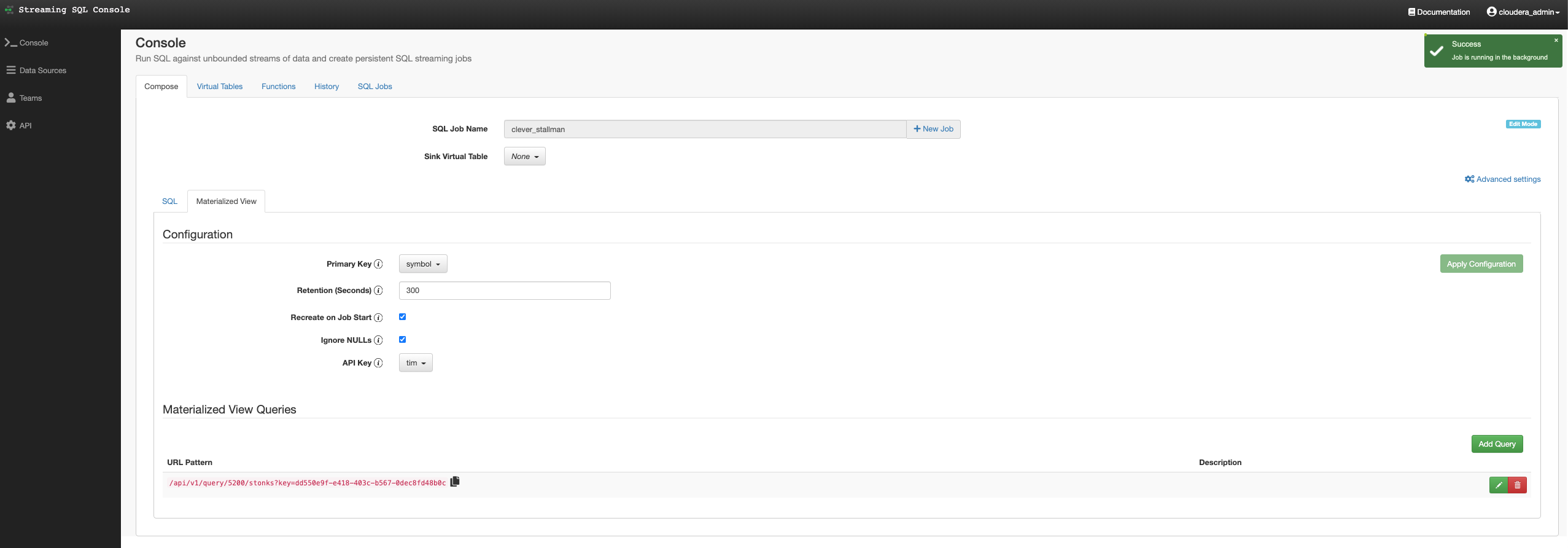
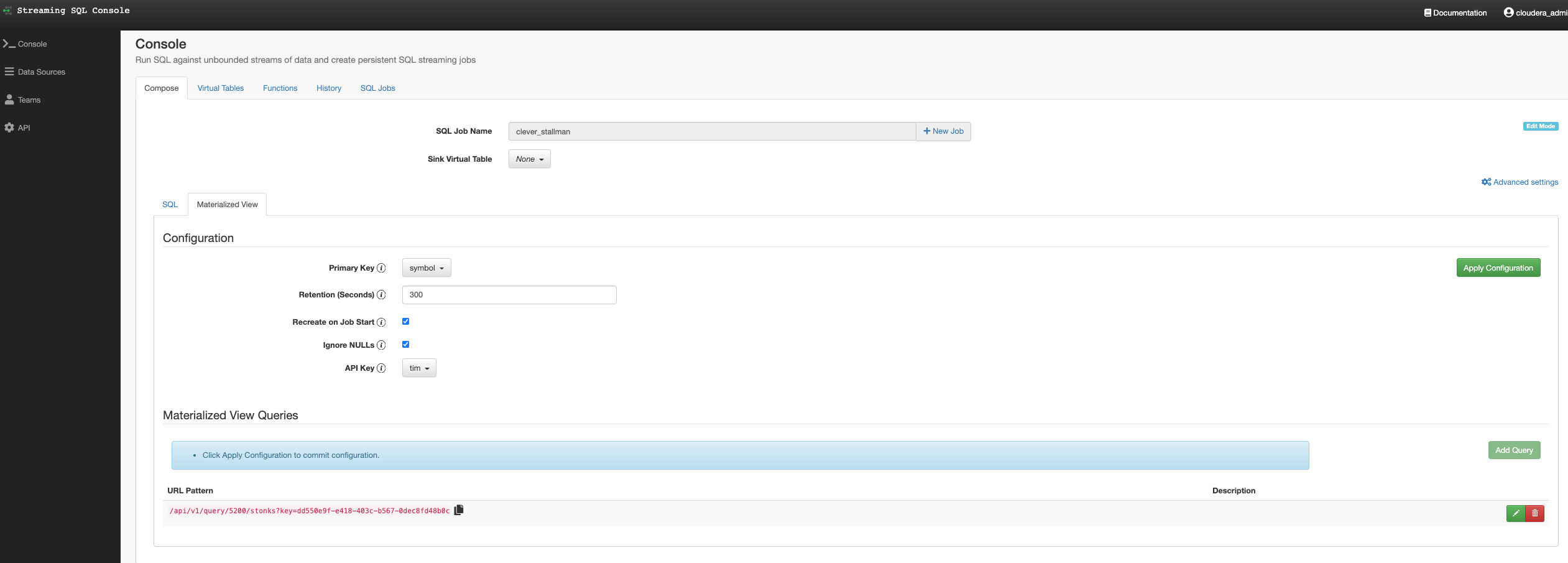
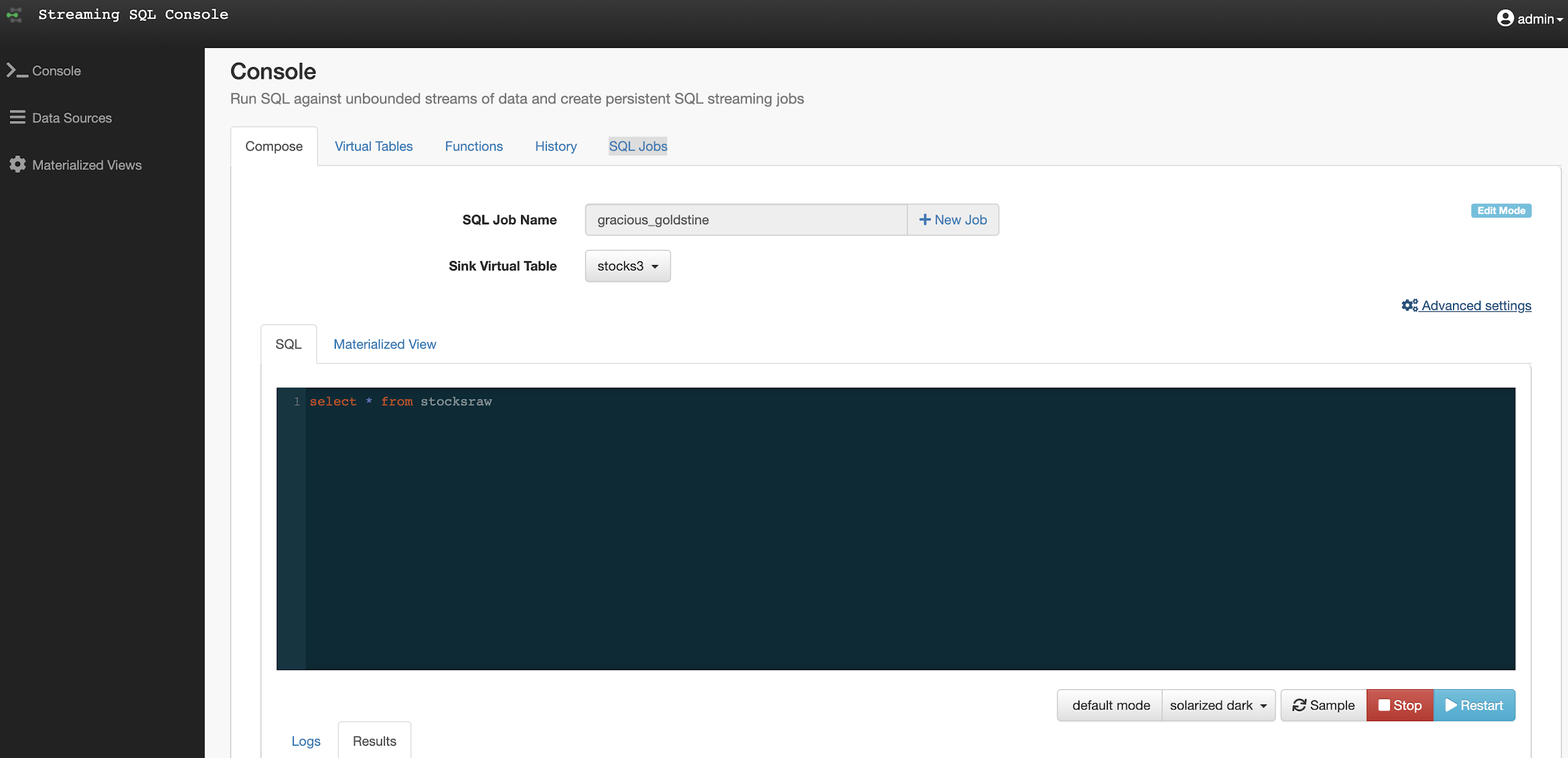
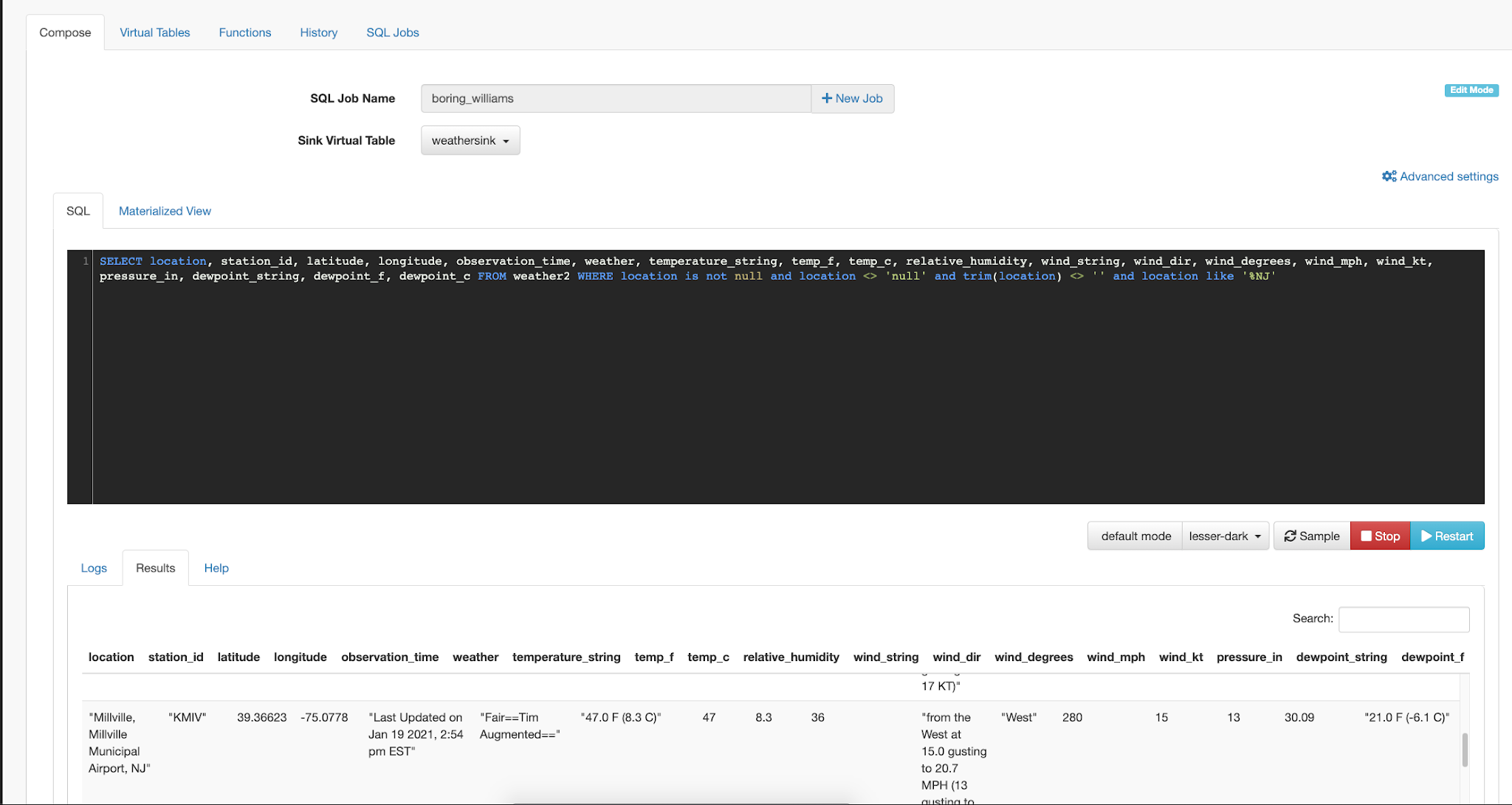
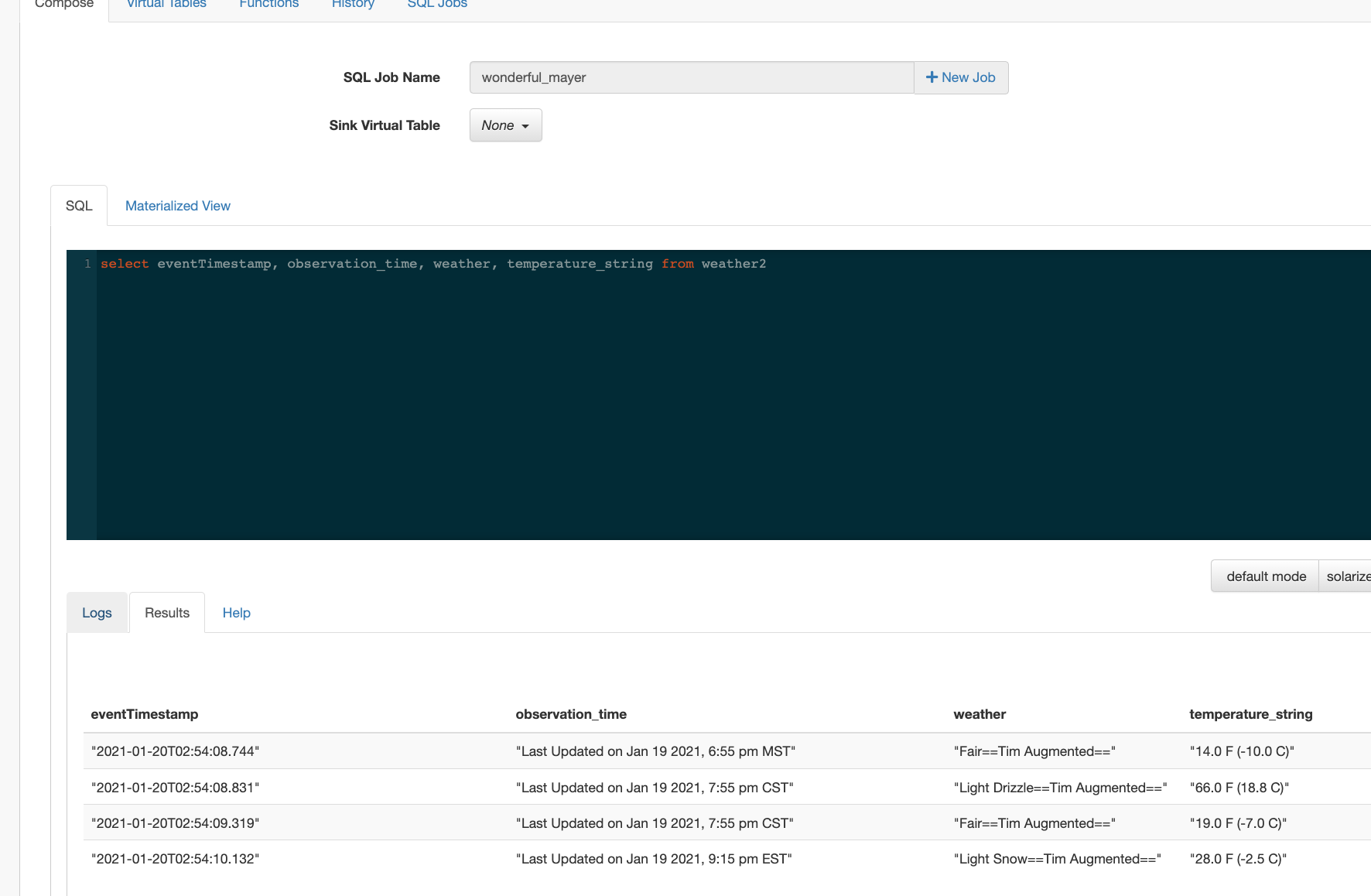
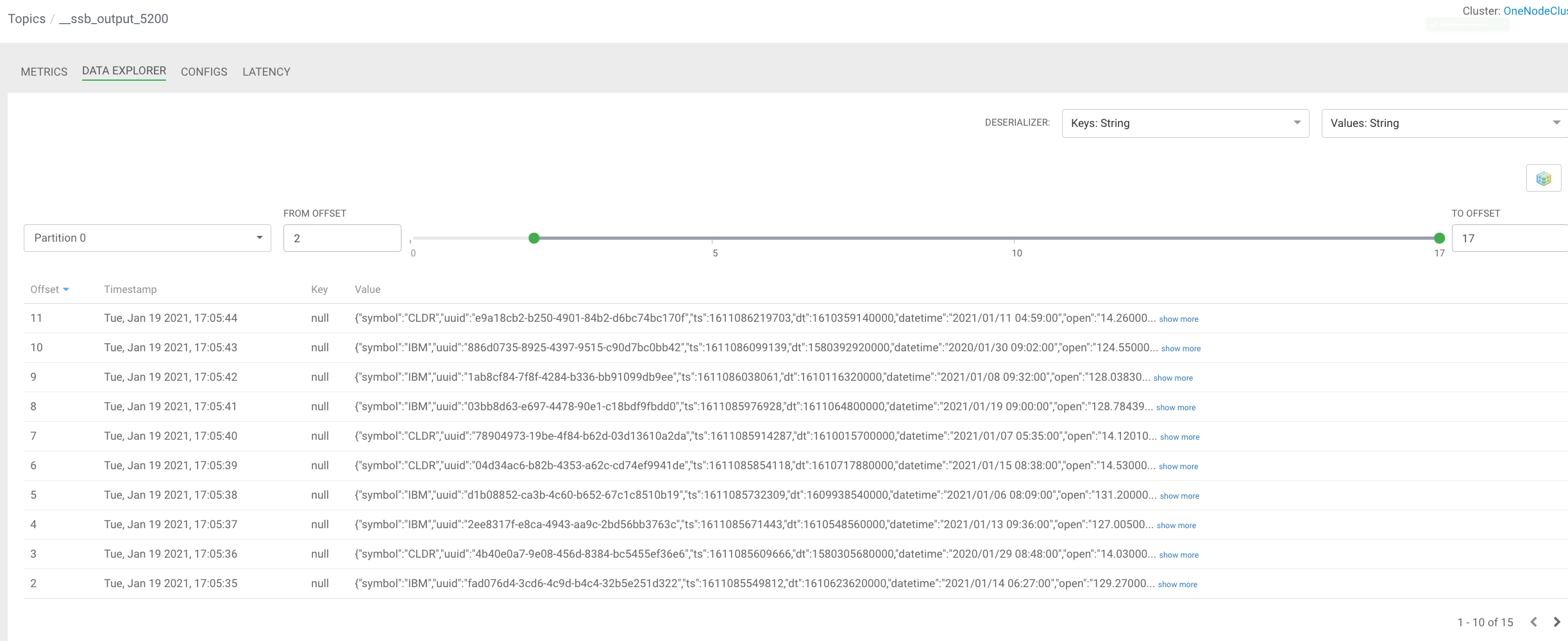
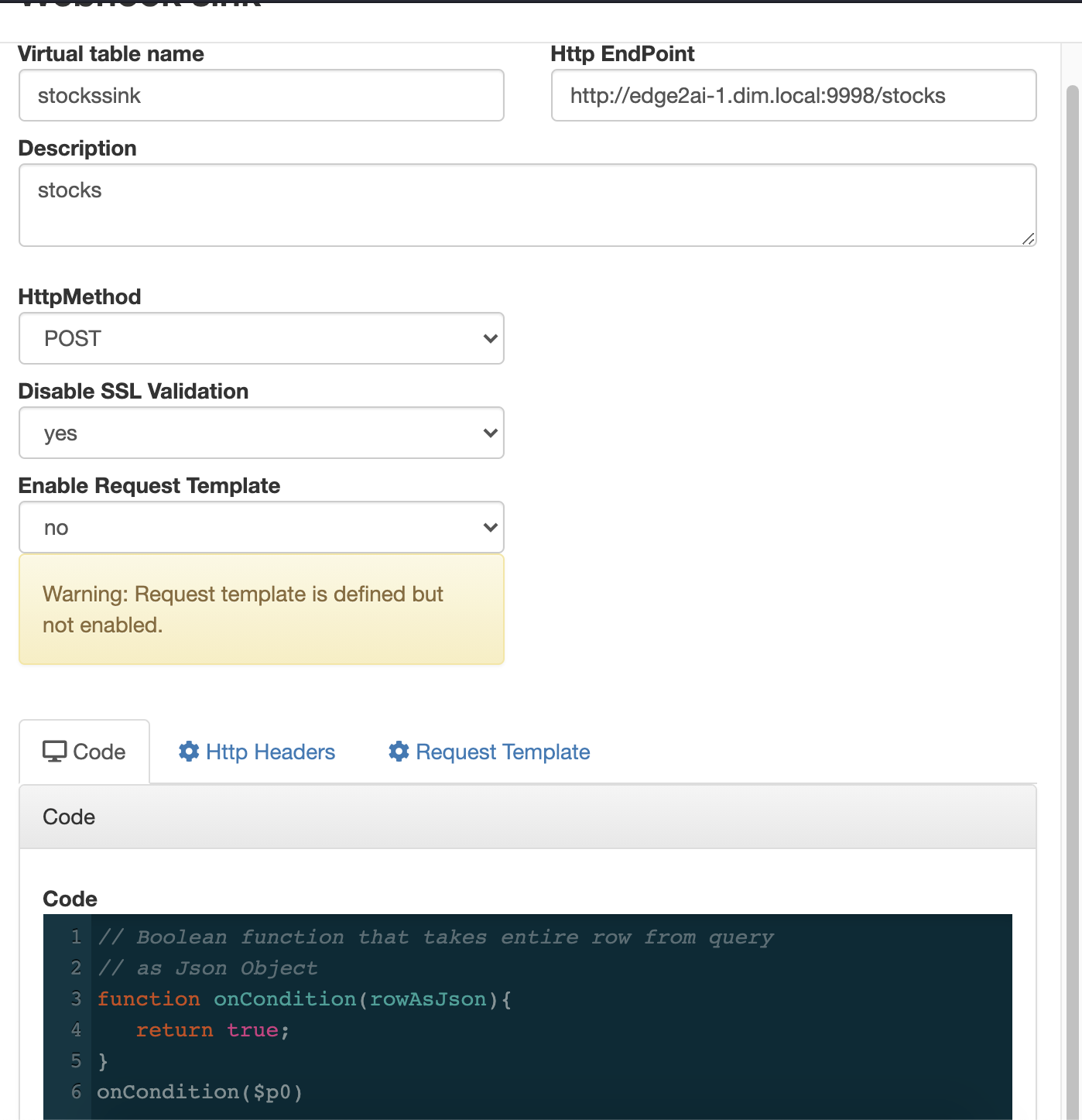
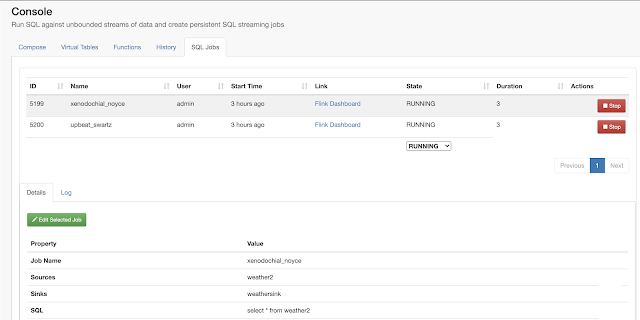
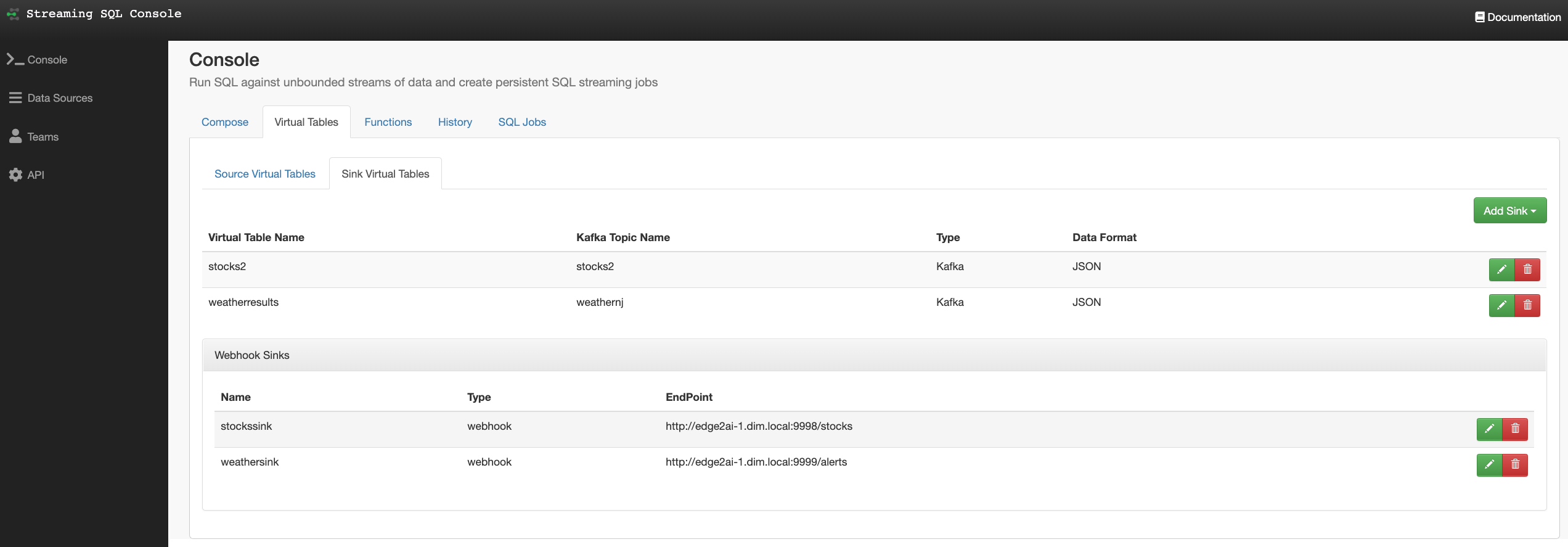
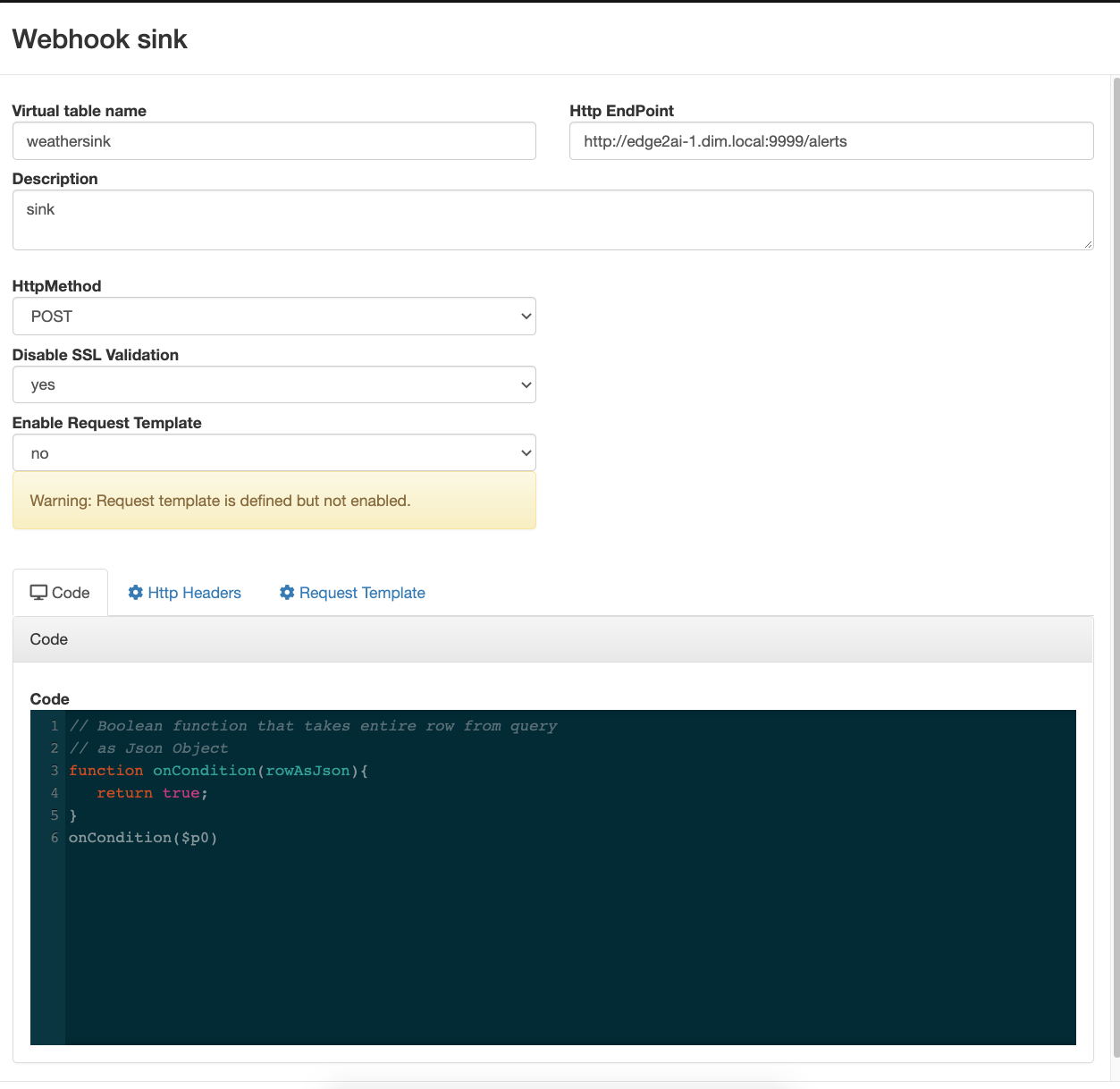
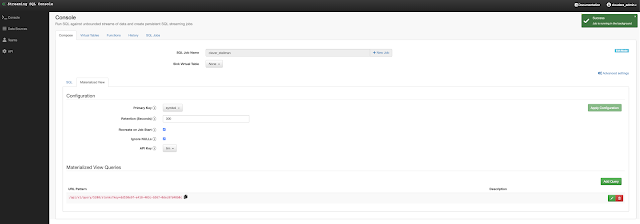
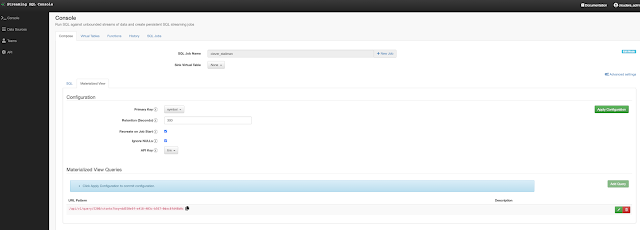
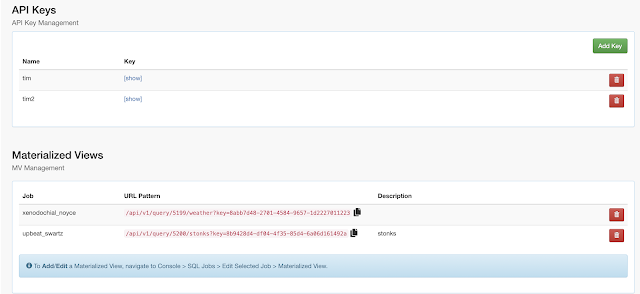
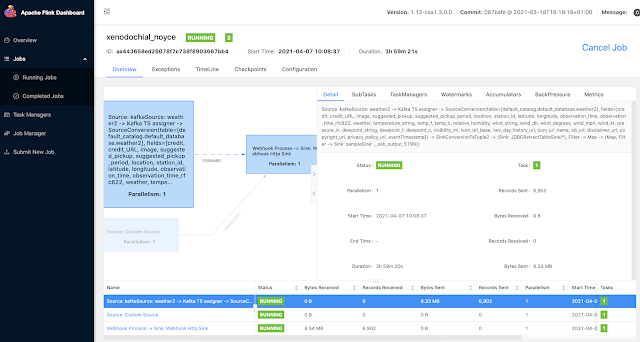
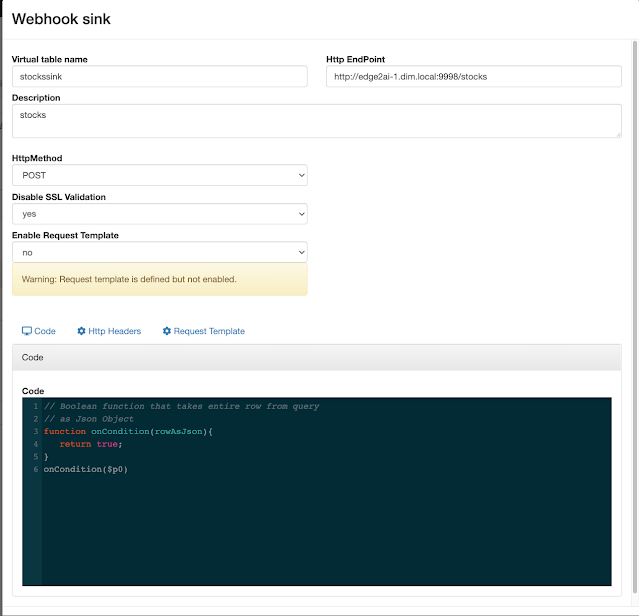
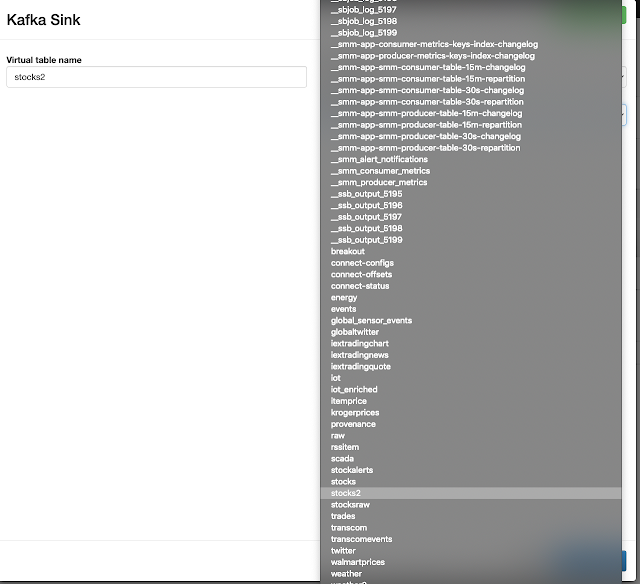
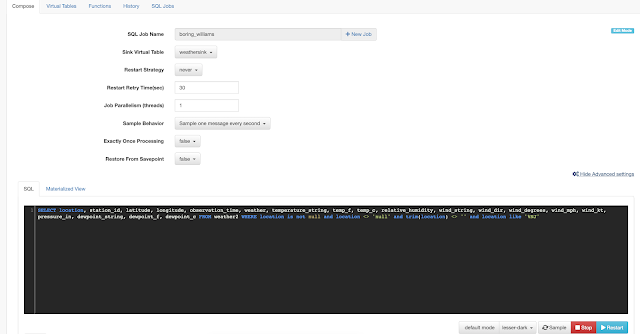
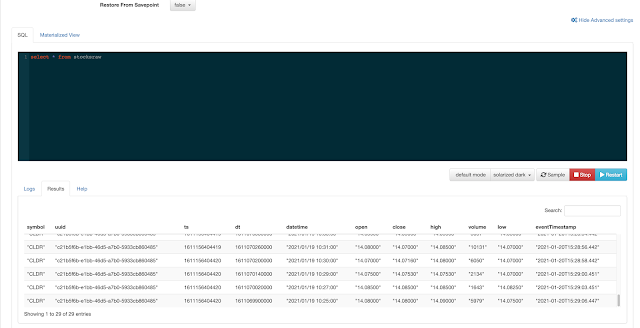
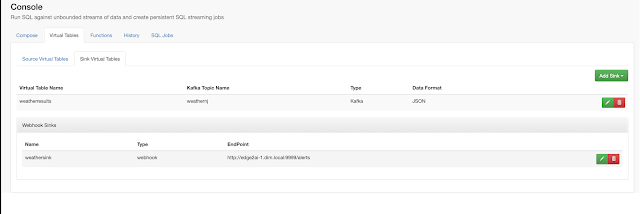
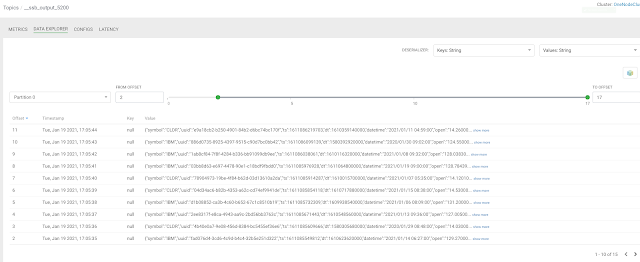
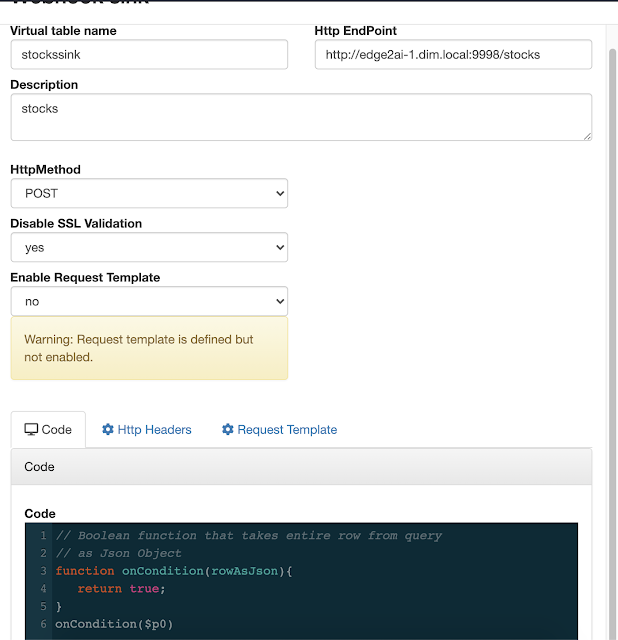
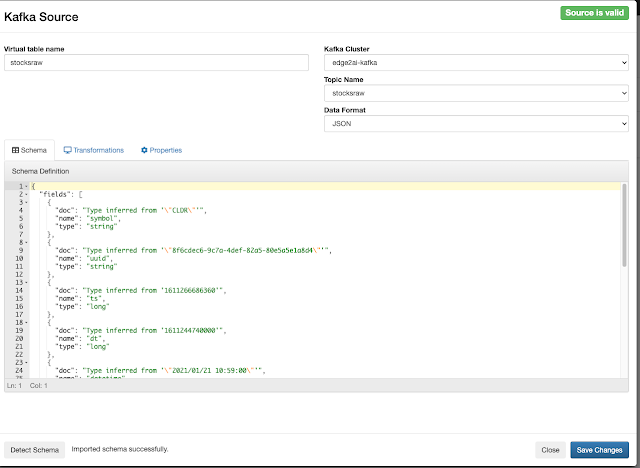
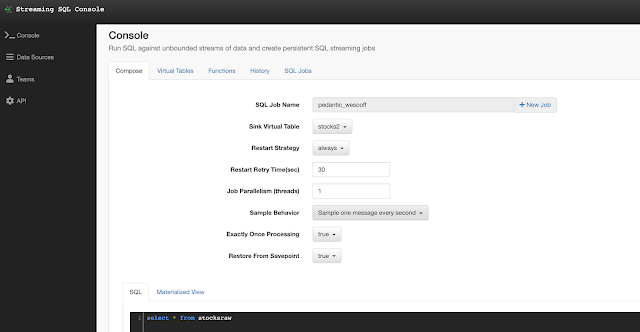
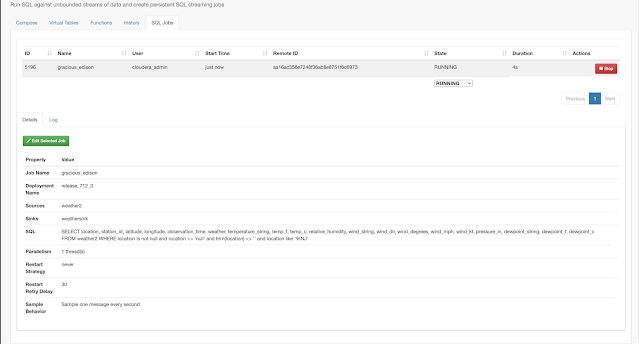
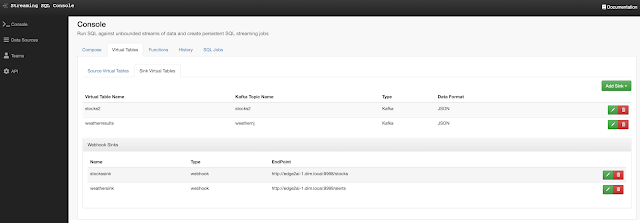
In this initial release, the user is given a complete web UI to build, develop, test, and deploy enterprise Continuous SQL queries into YARN Apache Flink clusters. The initial source is any number of Kafka clusters and the first set of outputs are Kafka clusters and webhooks. You are also given the ability to build Materialized Views that act as constantly updated, but fast sources of data for REST clients to consume. This makes for a great interface to Kafka data from non-Kafka consumers.
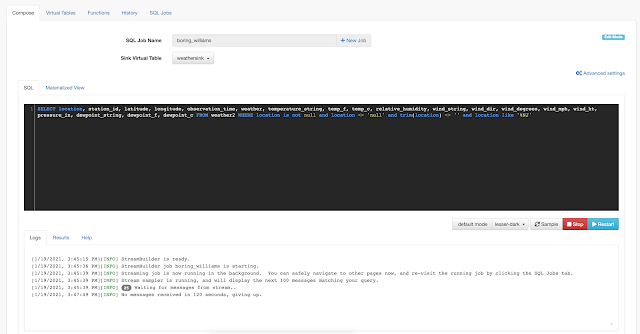
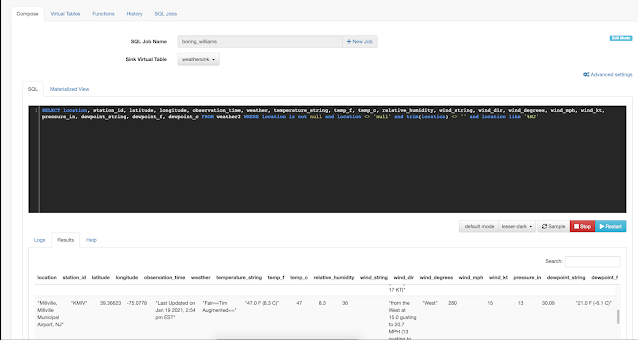
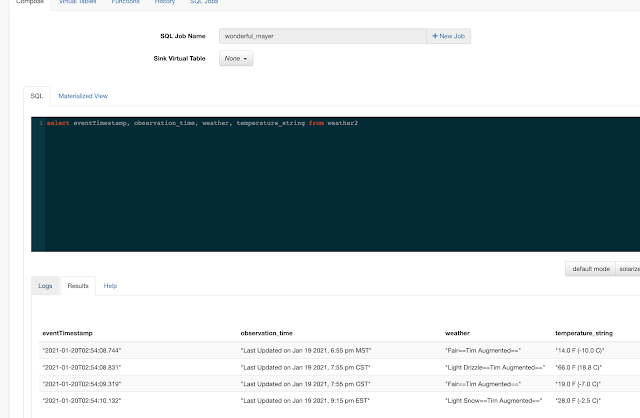
All you need to do is type SQL against tables and the results can be in Materialized Views, Kafka topics, or webhooks. You can do rich SQL thanks to Apache Calcite including Joins, Order By, Aggregates, and more.
CSA 1.3.0 is now available with Apache Flink 1.12 and SQL Stream Builder! Check out this white paper for some details. You can get full details on the Stream Processing and Analytics available from Cloudera here.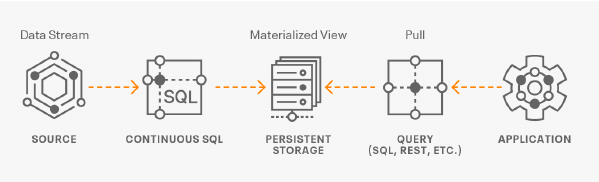
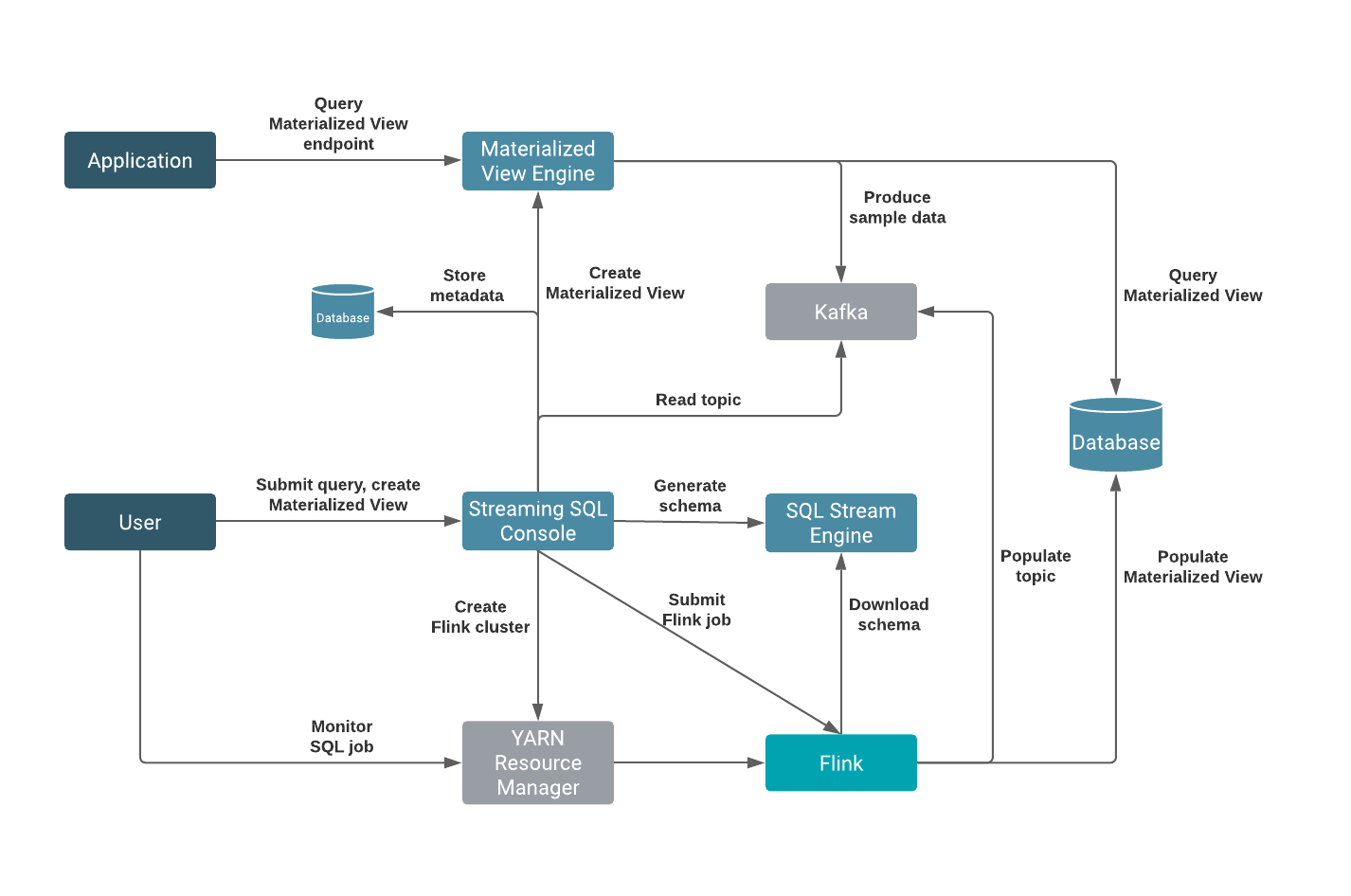
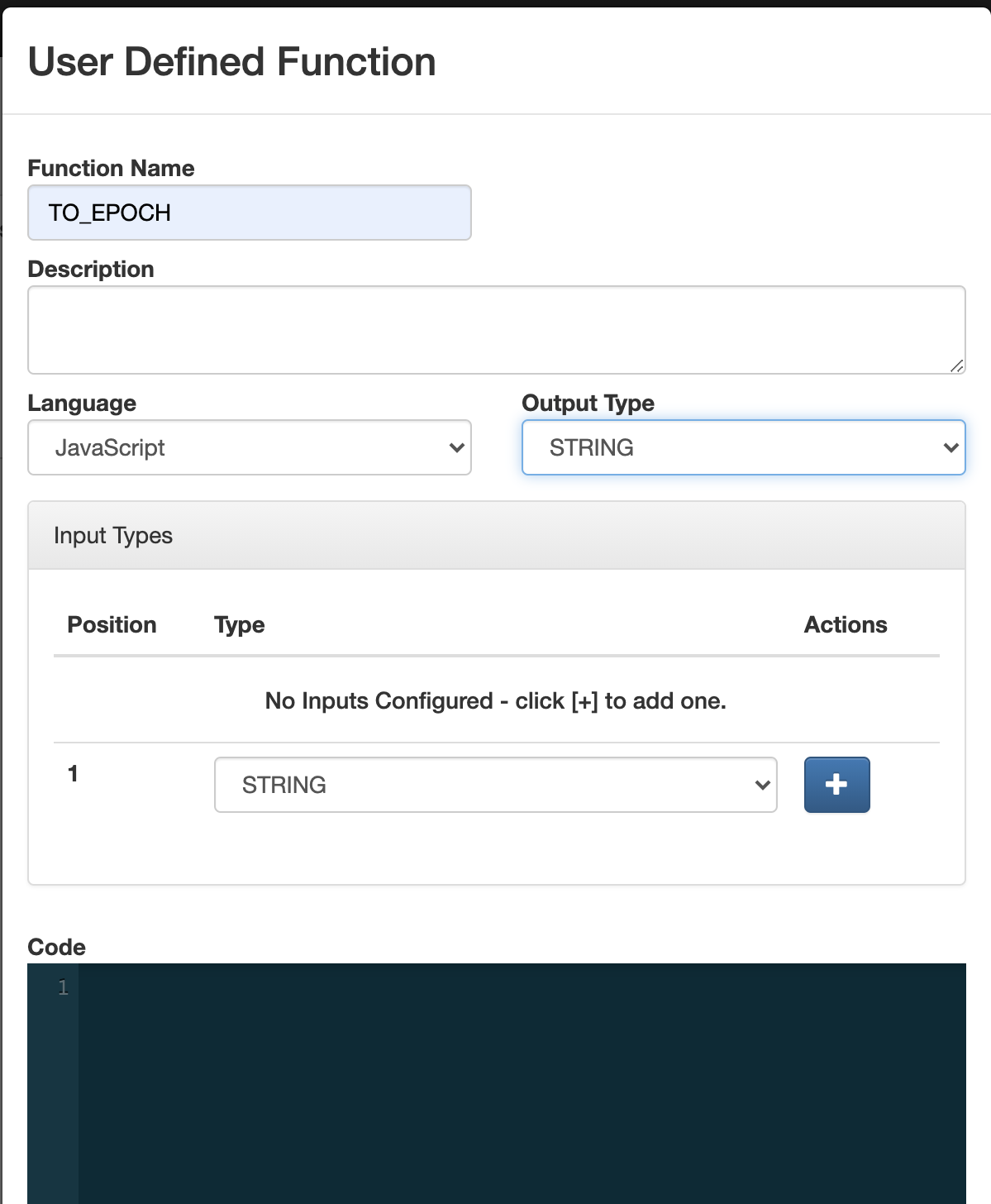
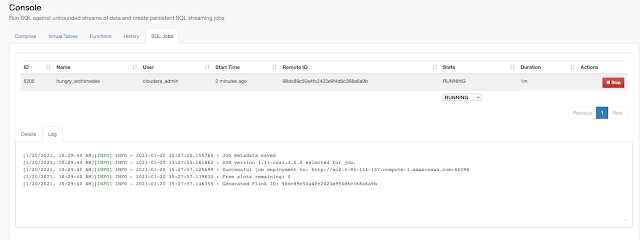
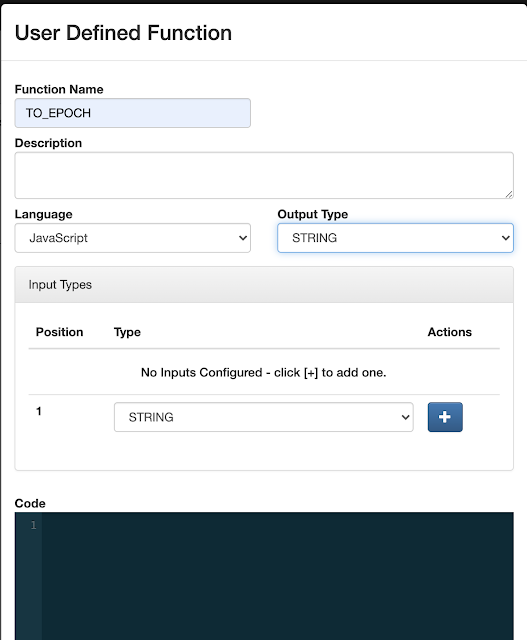
This is an awesome way to query Kafka topics with continuous SQL that is deployed to scalable Flink nodes in YARN or K8. We can also easily define functions in JavaScript to enhance, enrich and augment our data streams. No Java to write; no heavy deploys or build scripts; we can build, test and deploy these advanced streaming applications all from your secure browser interface.
Example Queries:
xxxxxxxxxx
SELECT location, max(temp_f) as max_temp_f, avg(temp_f) as avg_temp_f,
min(temp_f) as min_temp_f
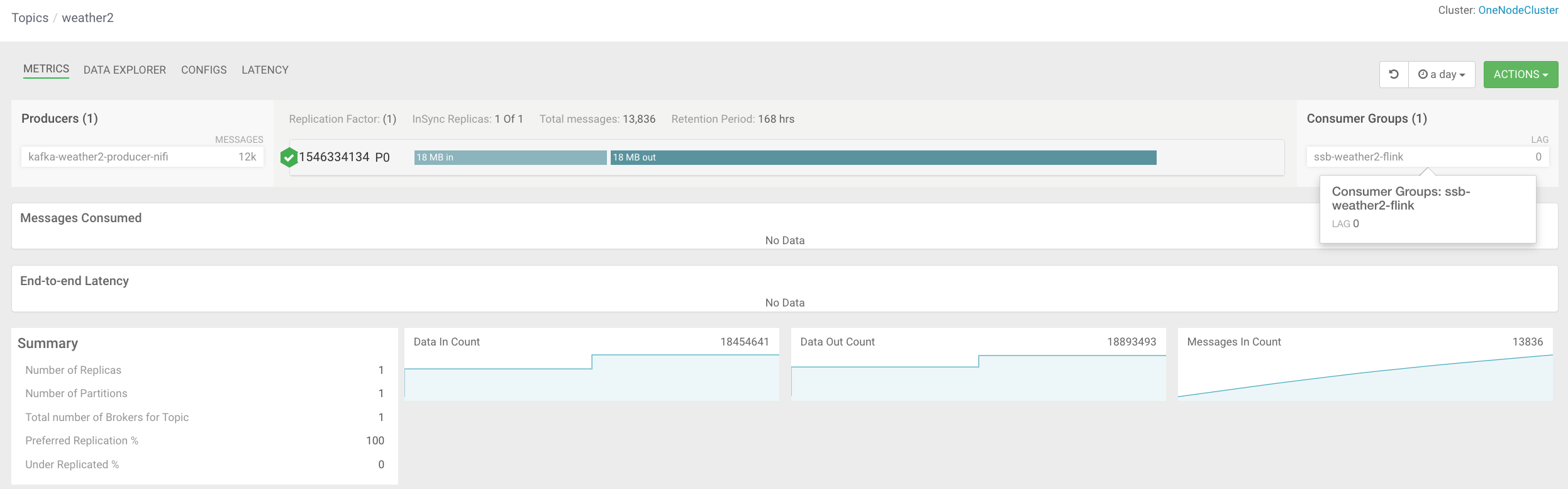
FROM weather2
GROUP BY location
xxxxxxxxxx
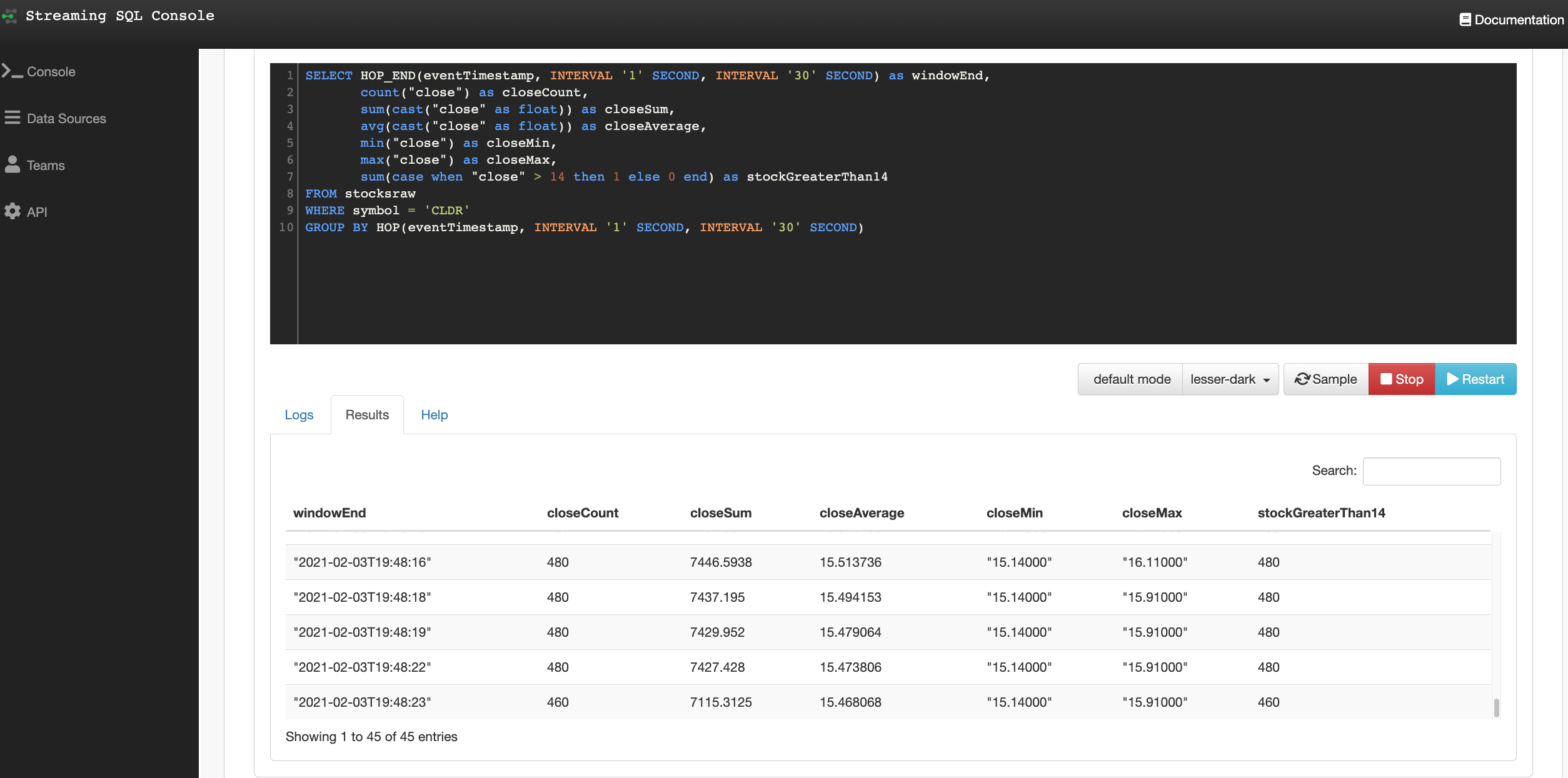
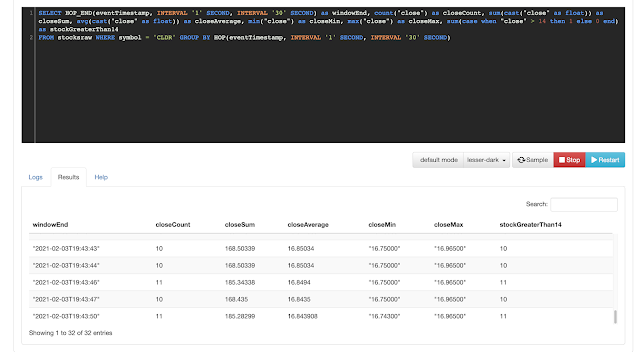
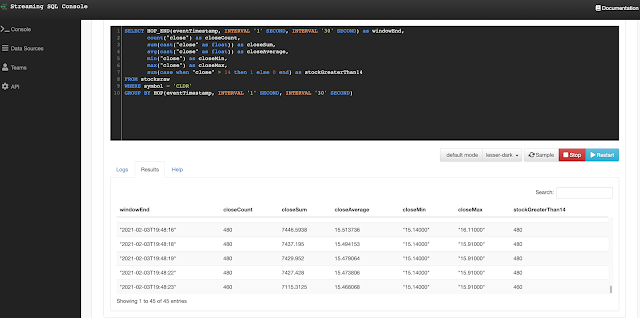
SELECT HOP_END(eventTimestamp, INTERVAL '1' SECOND, INTERVAL '30' SECOND) as windowEnd,
count(`close`) as closeCount,
sum(cast(`close` as float)) as closeSum, avg(cast(`close` as float)) as closeAverage,
min(`close`) as closeMin,
max(`close`) as closeMax,
sum(case when `close` > 14 then 1 else 0 end) as stockGreaterThan14
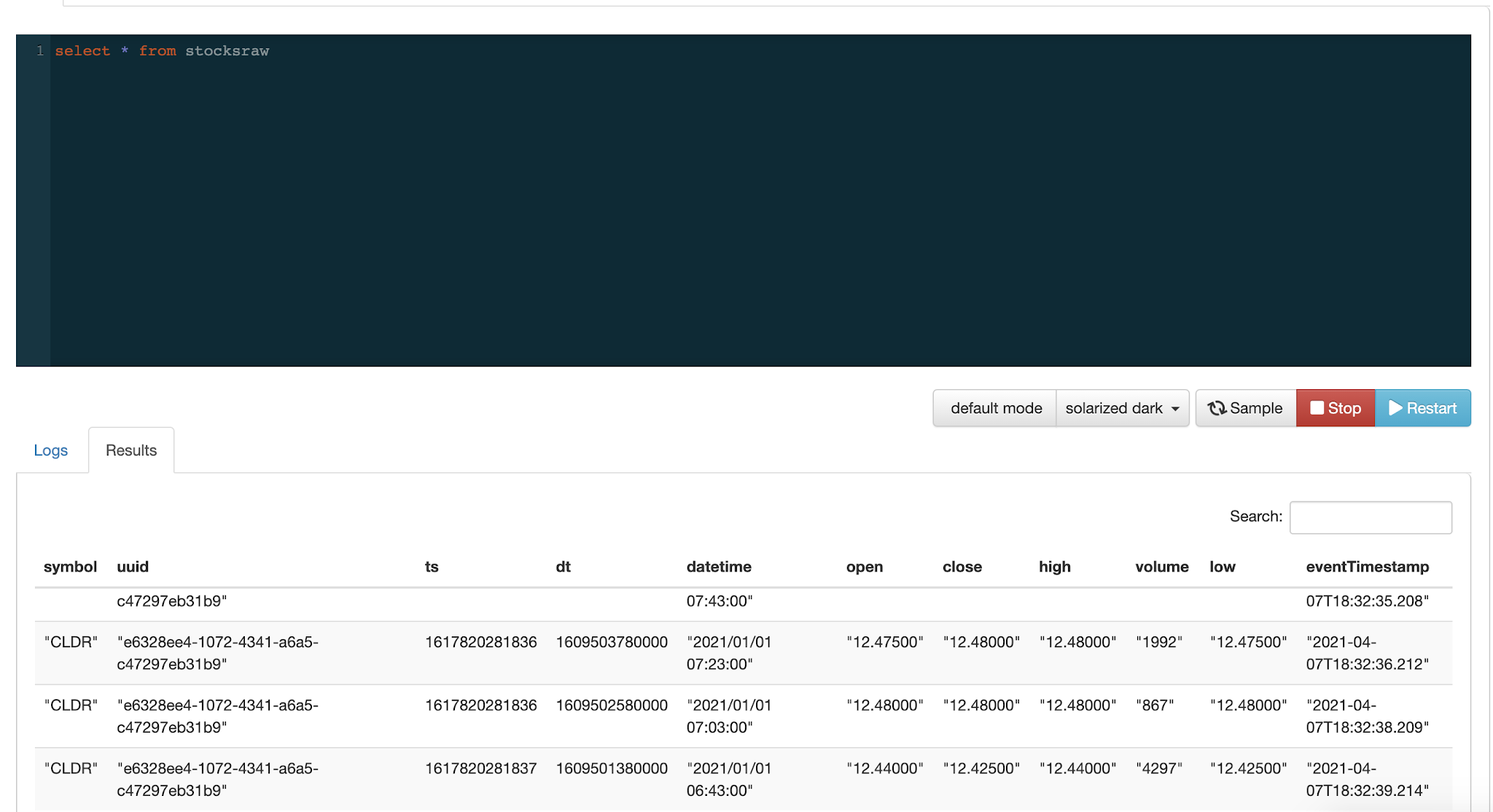
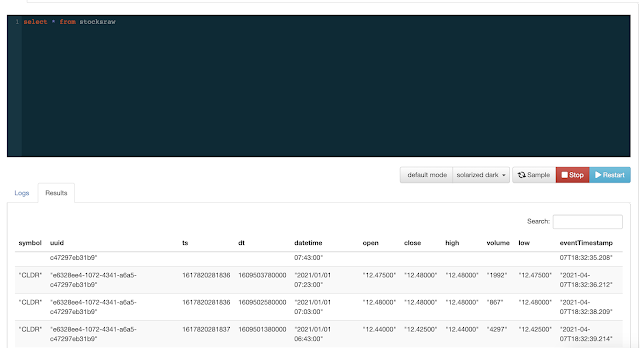
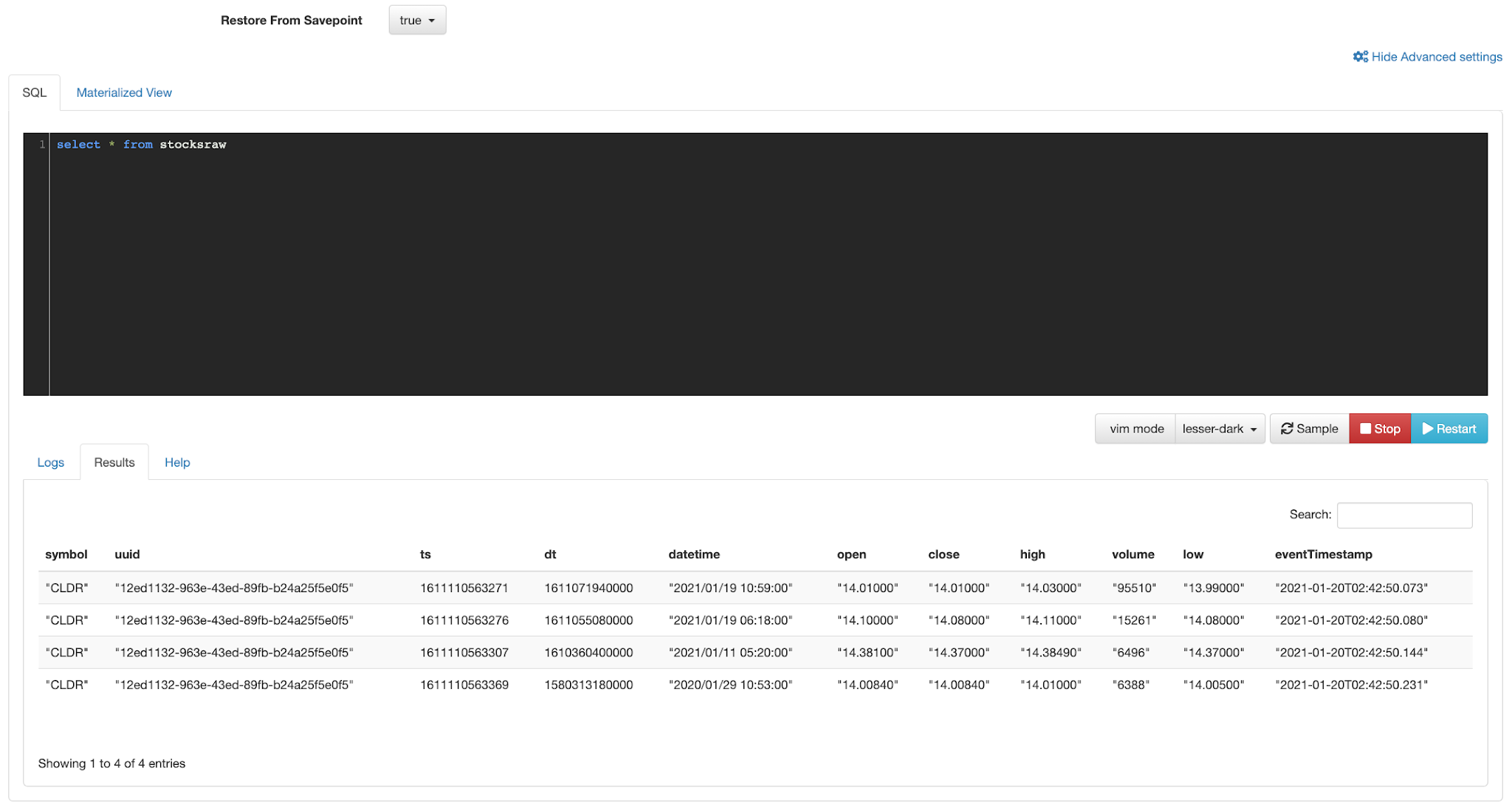
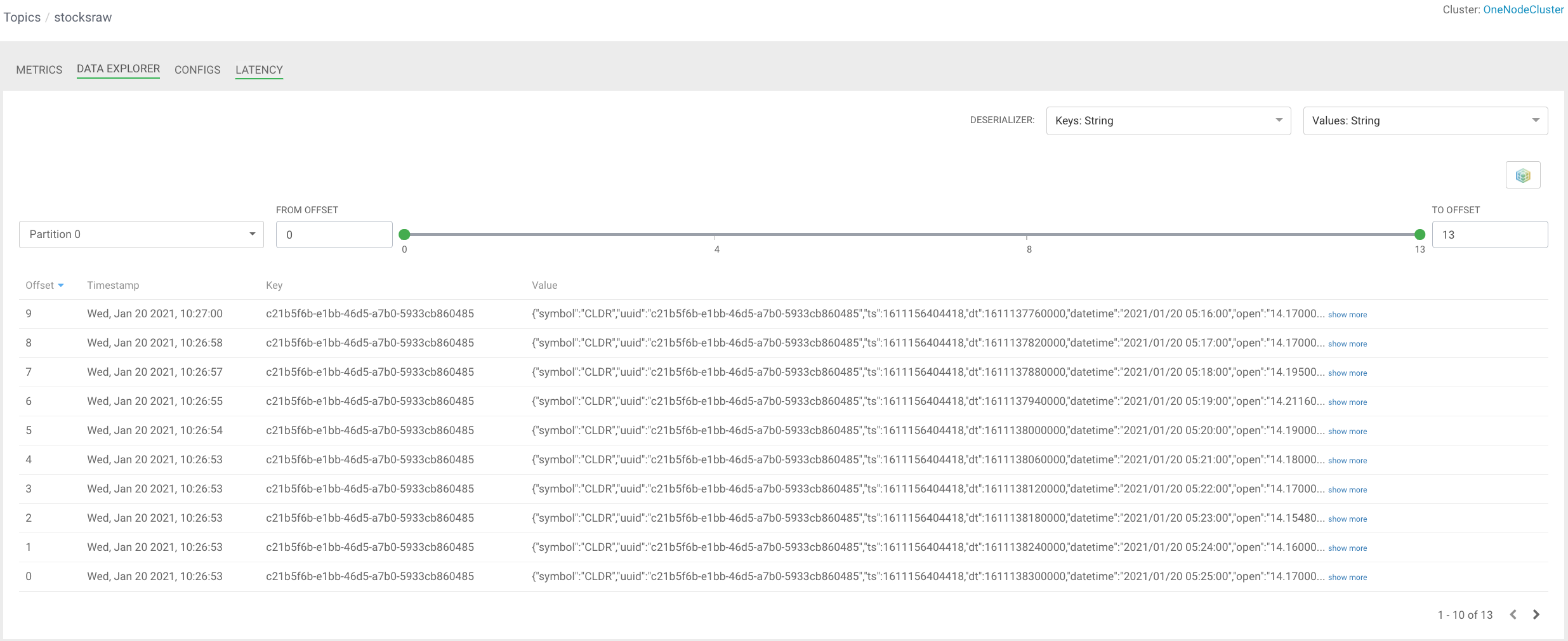
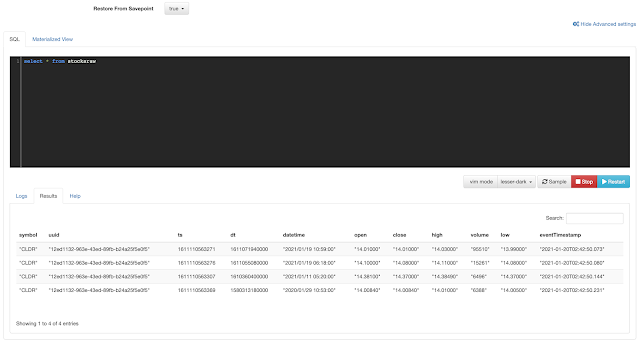
FROM stocksraw
WHERE symbol = 'CLDR'
GROUP BY HOP(eventTimestamp, INTERVAL '1' SECOND, INTERVAL '30' SECOND)
x
SELECT scada2.uuid, scada2.systemtime, scada2.temperaturef, scada2.pressure,
scada2.humidity, scada2.lux, scada2.proximity,
scada2.oxidising,scada2.reducing , scada2.nh3,
scada2.gasko,energy2.`current`,
energy2.voltage,energy2.`power`,energy2.`total`,energy2.fanstatus
FROM energy2 JOIN scada2 ON energy2.systemtime = scada2.systemtime
xxxxxxxxxx
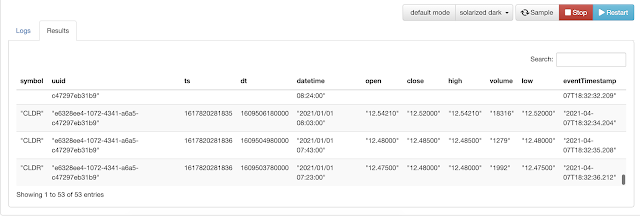
SELECT symbol, uuid, ts, dt, `open`, `close`, high, volume, `low`, `datetime`, 'new-high' message, 'nh' alertcode,
CAST(CURRENT_TIMESTAMP AS BIGINT) alerttime
FROM stocksraw st
WHERE symbol is not null
AND symbol <> 'null'
AND trim(symbol) <> ''
AND CAST(close as DOUBLE) >
(SELECT MAX(CAST(`close` as DOUBLE))
FROM stocksraw s
WHERE s.symbol = st.symbol)
xxxxxxxxxx
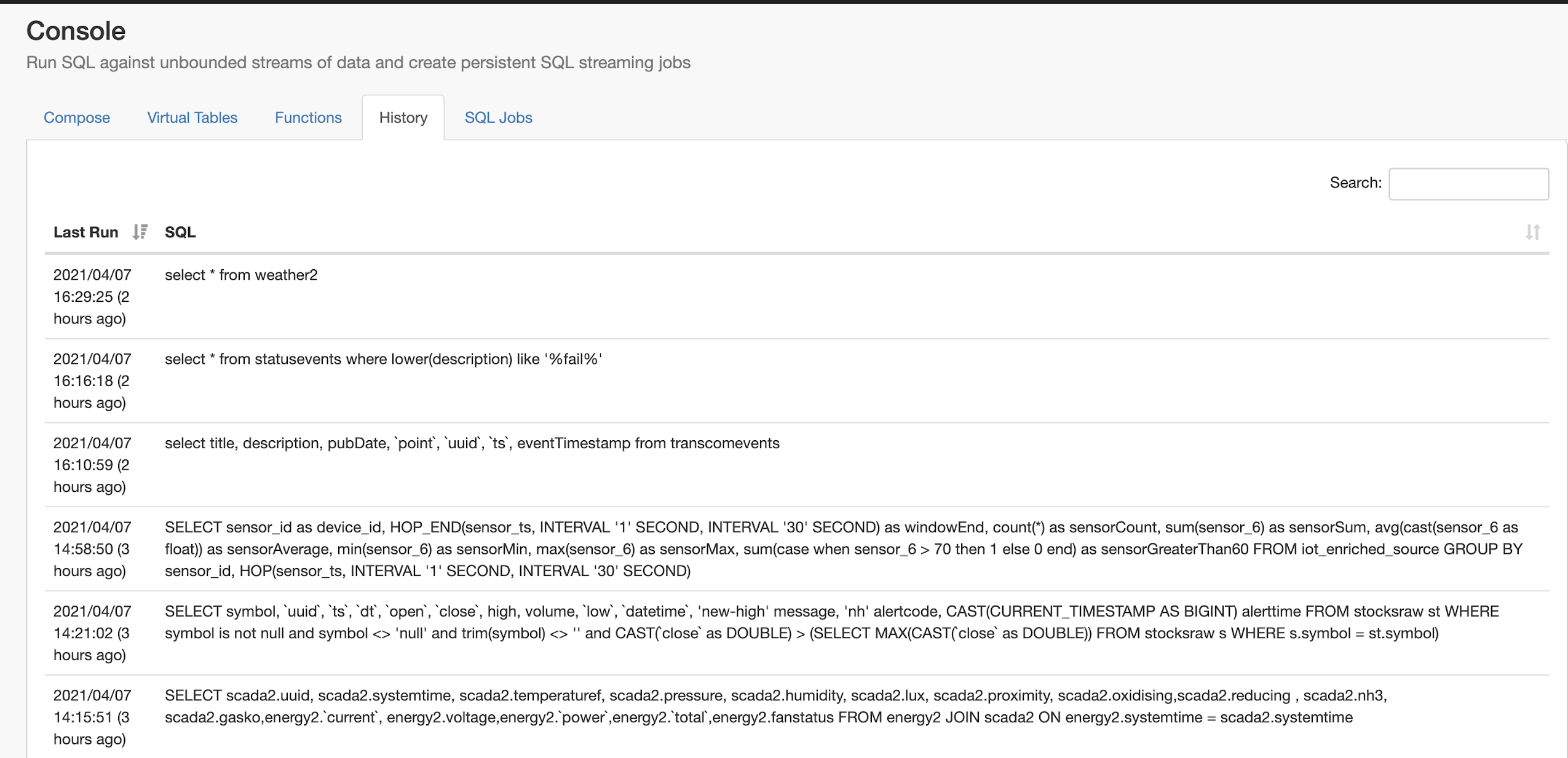
SELECT *
FROM statusevents
WHERE lower(description) like '%fail%'
xxxxxxxxxx
SELECT sensor_id as device_id,
HOP_END(sensor_ts, INTERVAL '1' SECOND, INTERVAL '30' SECOND) as windowEnd,
count(*) as sensorCount,
sum(sensor_6) as sensorSum,
avg(cast(sensor_6 as float)) as sensorAverage,
min(sensor_6) as sensorMin,
max(sensor_6) as sensorMax,
sum(case when sensor_6 > 70 then 1 else 0 end) as sensorGreaterThan60
FROM iot_enriched_source
GROUP BY
sensor_id,
HOP(sensor_ts, INTERVAL '1' SECOND, INTERVAL '30' SECOND)
SELECT title, description, pubDate, `point`, `uuid`, `ts`, eventTimestamp
FROM transcomevents
Source Code:
- https://github.com/tspannhw/CloudDemo2021
- https://github.com/tspannhw/StreamingSQLDemos
- https://github.com/tspannhw/SmartTransit
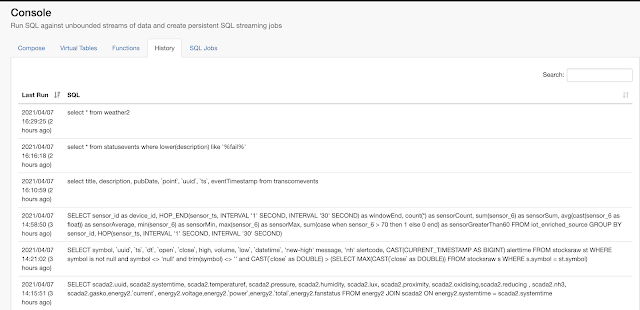
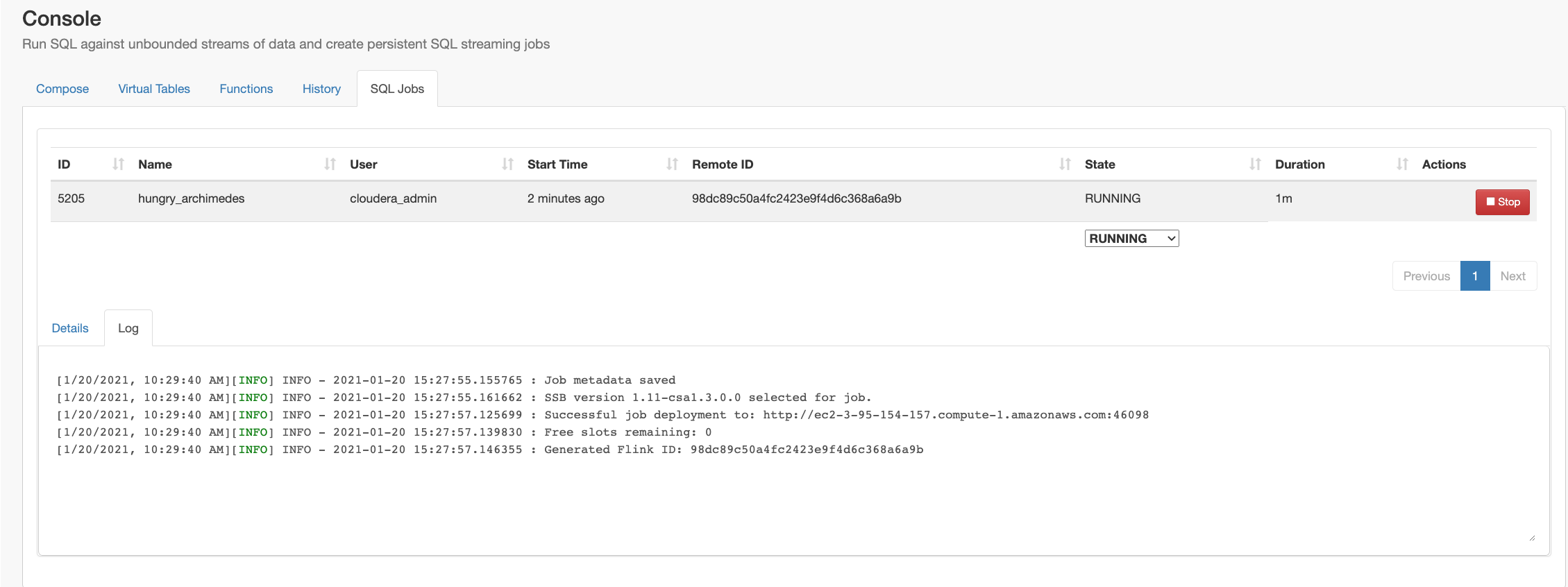
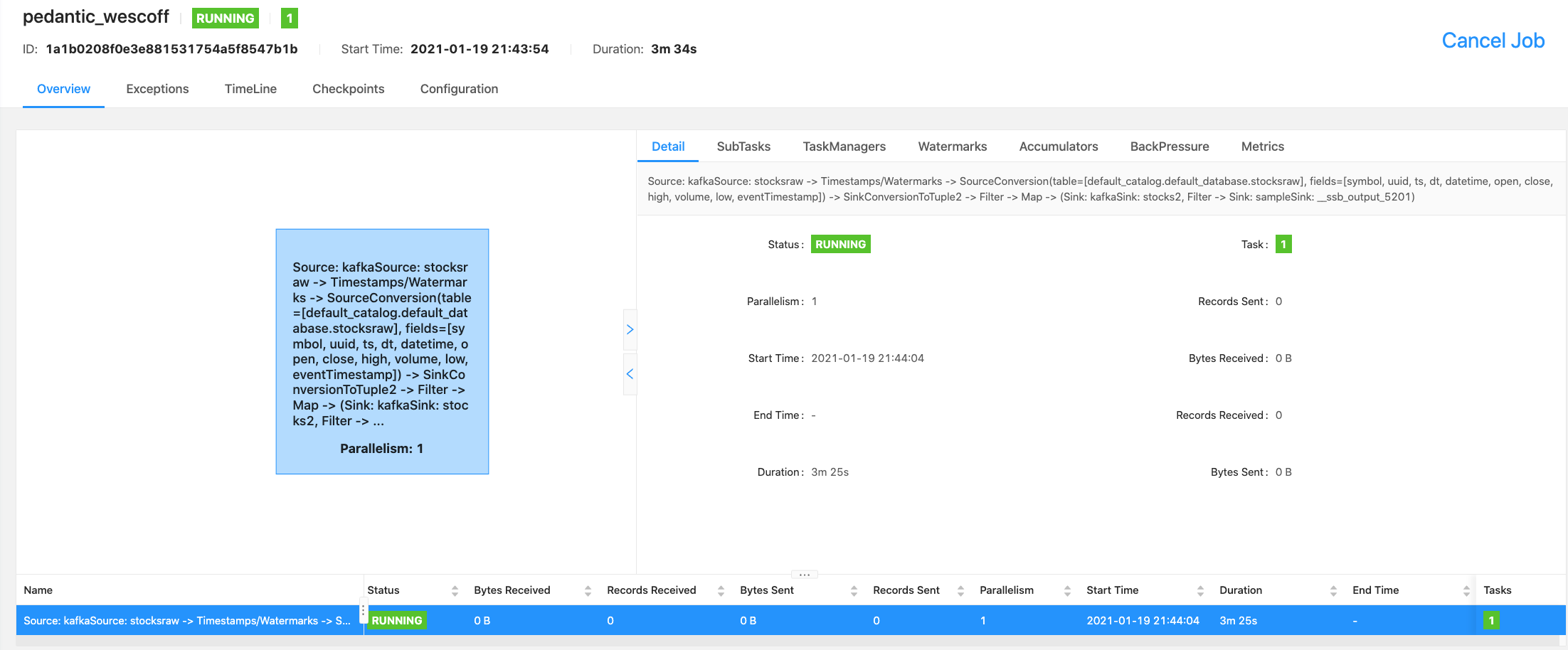
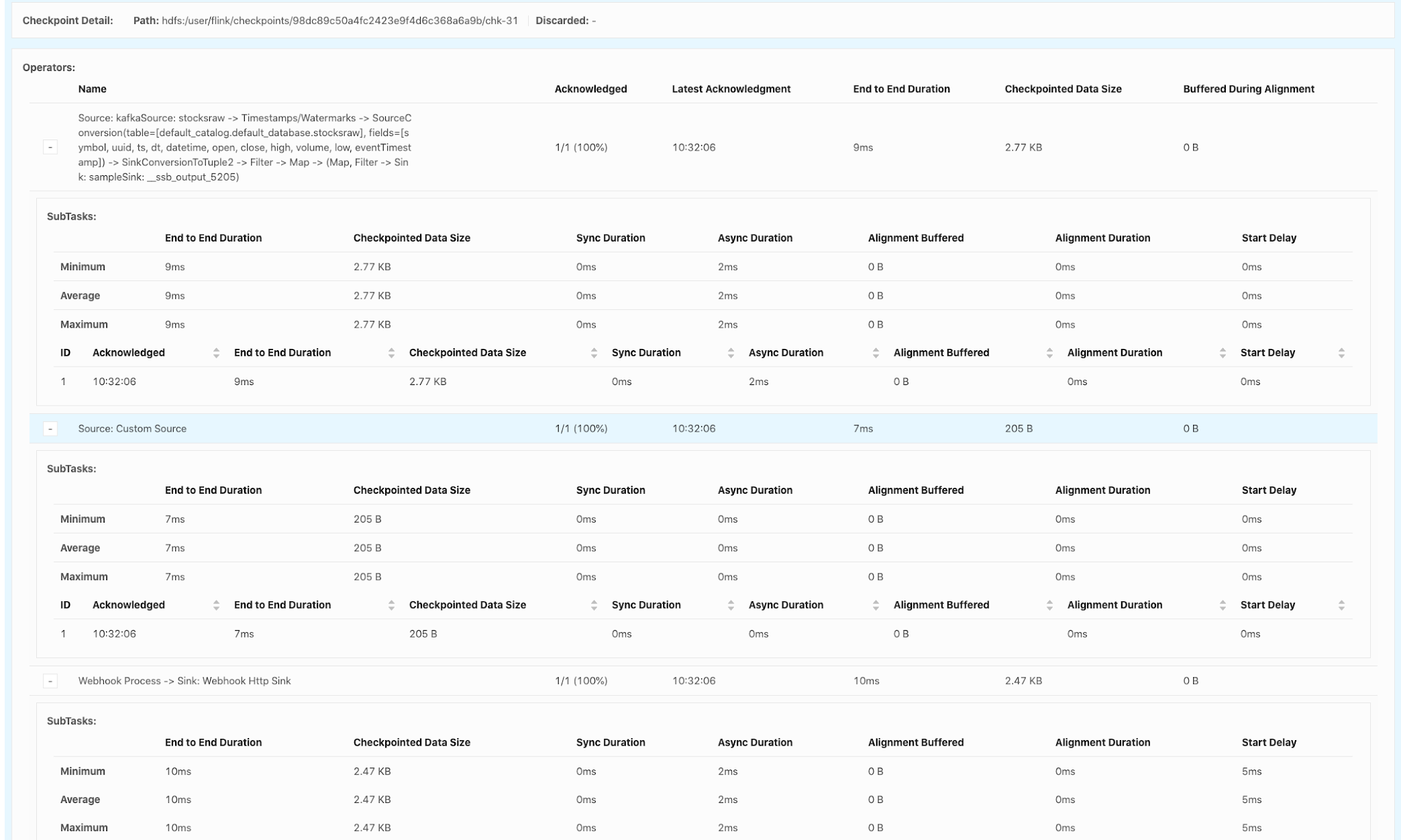
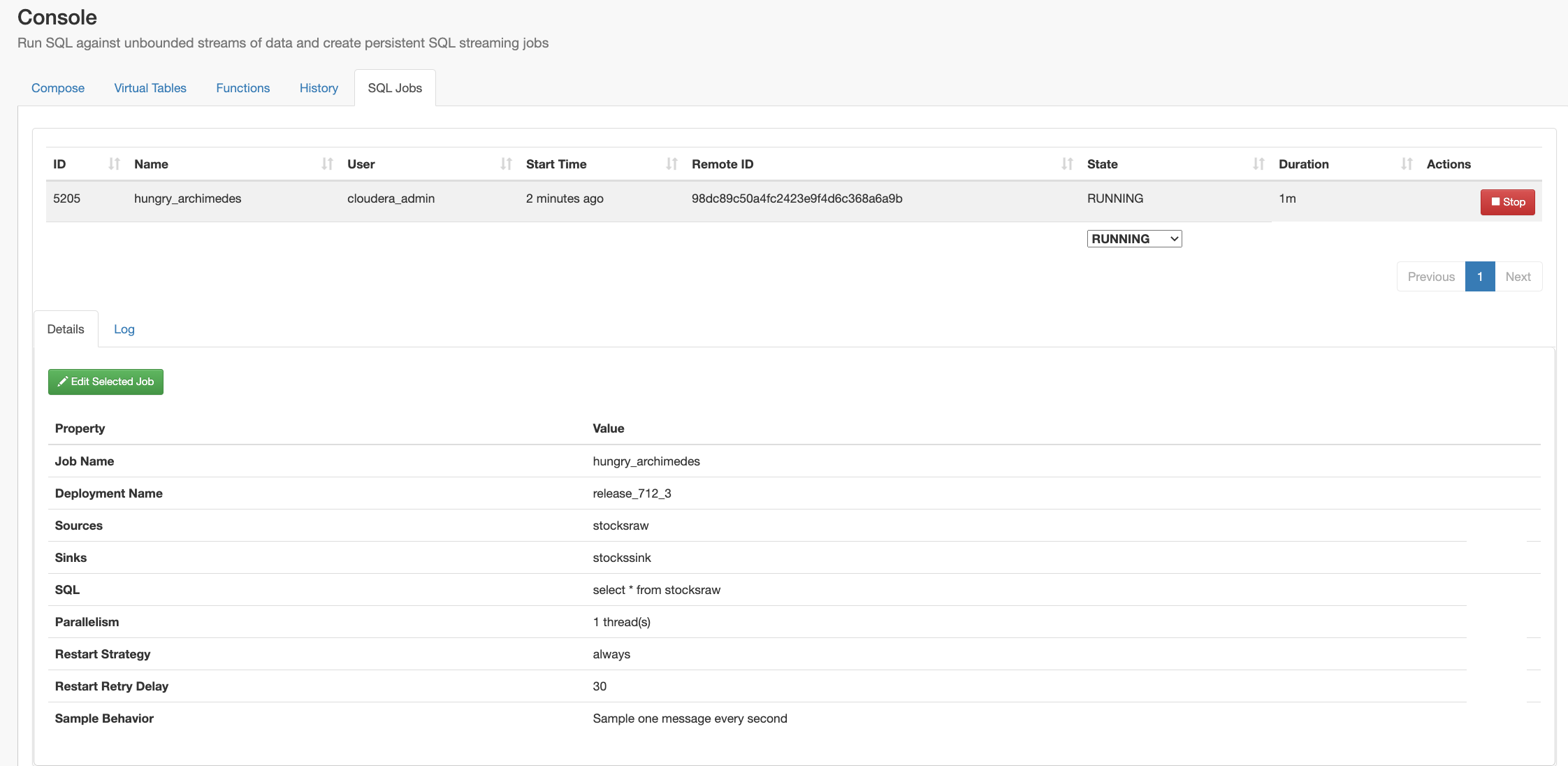
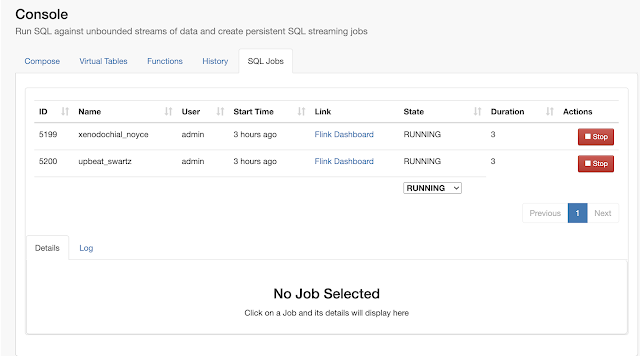
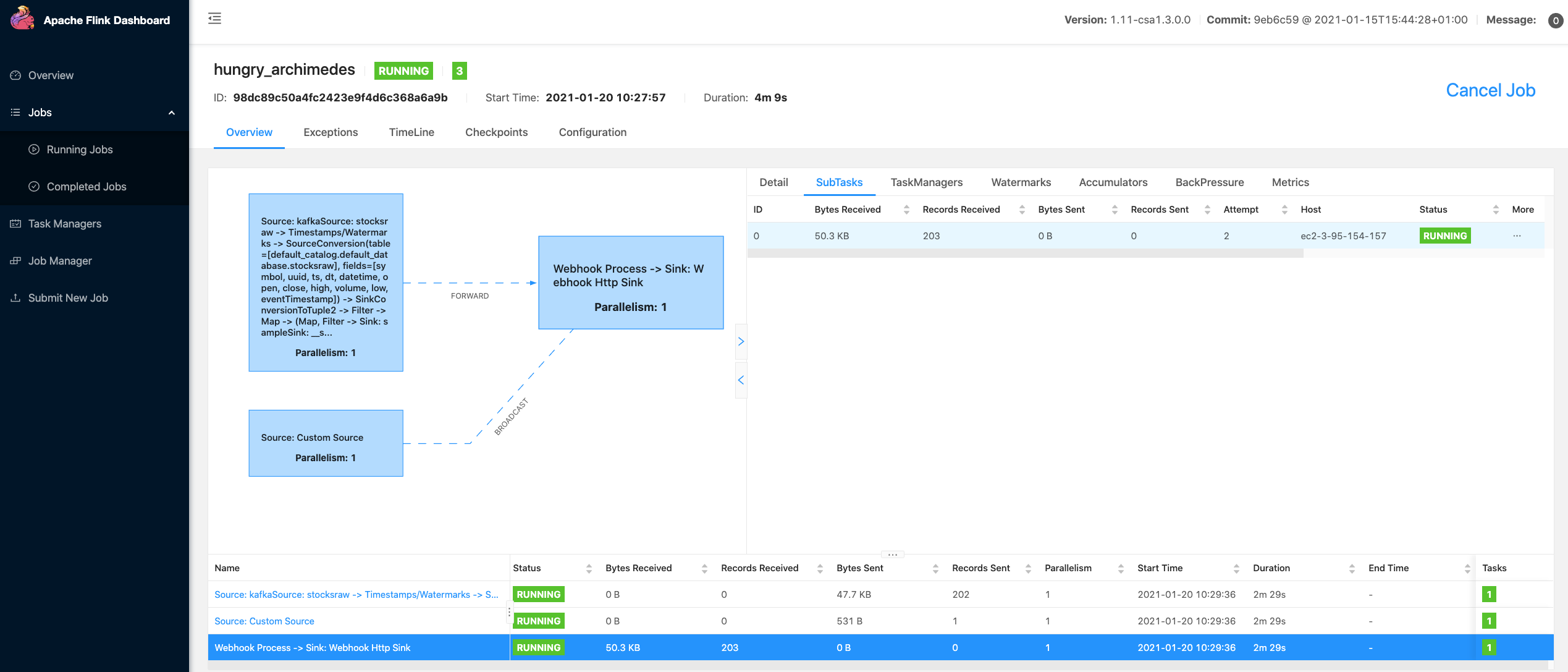
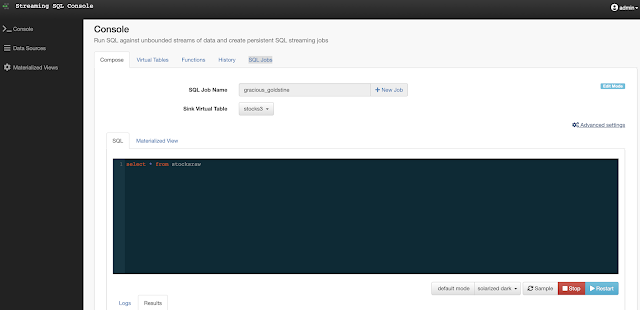
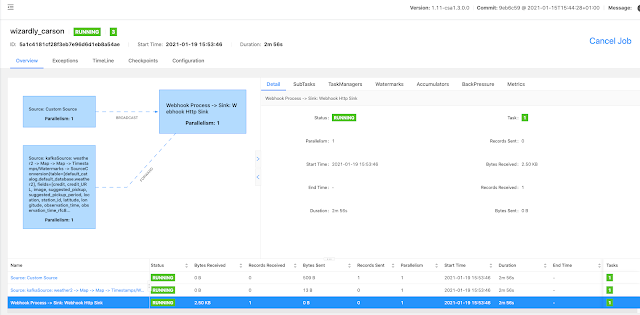
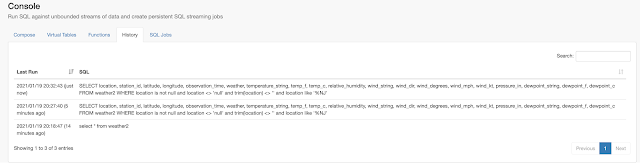
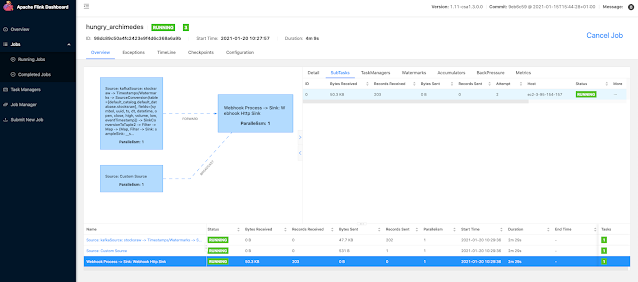
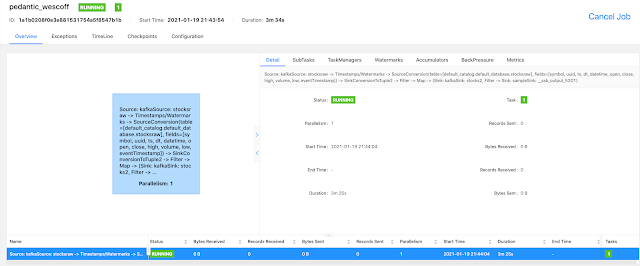
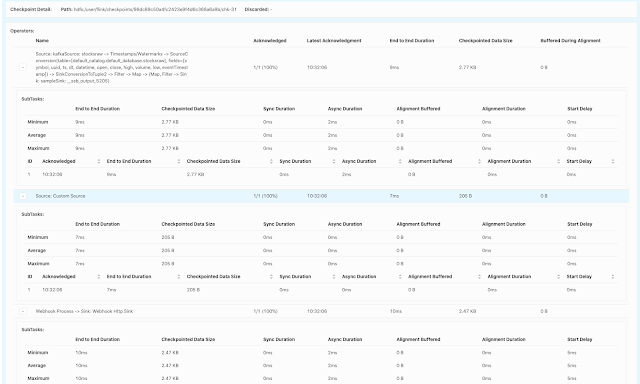
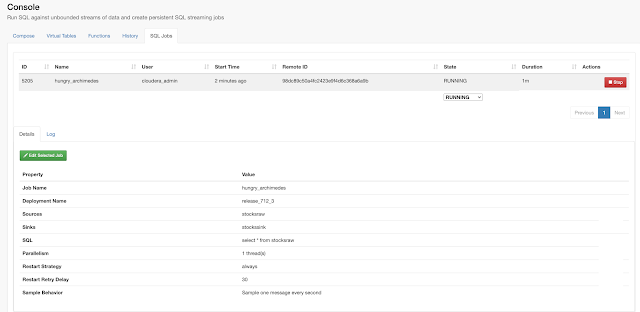
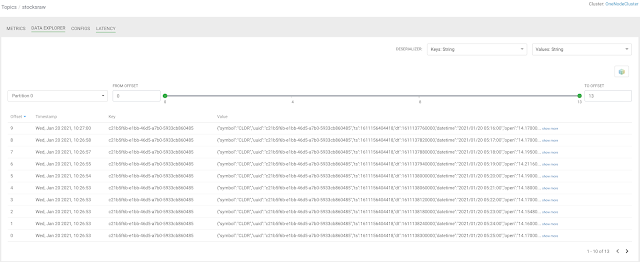
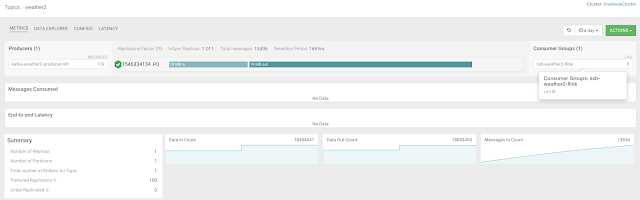
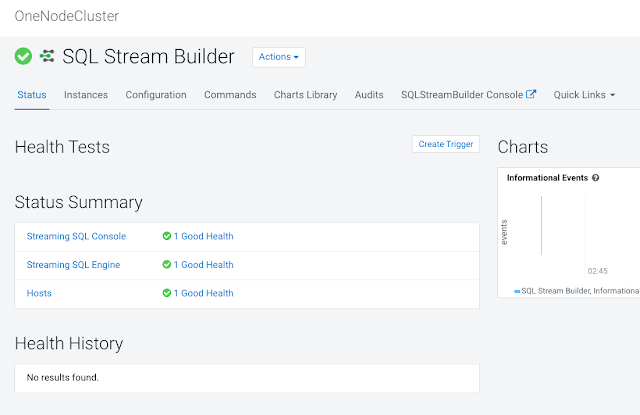
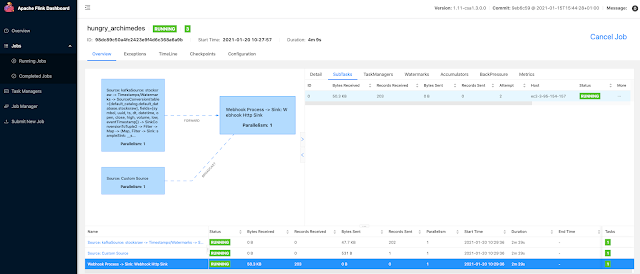
Example SQL Stream Builder Run
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

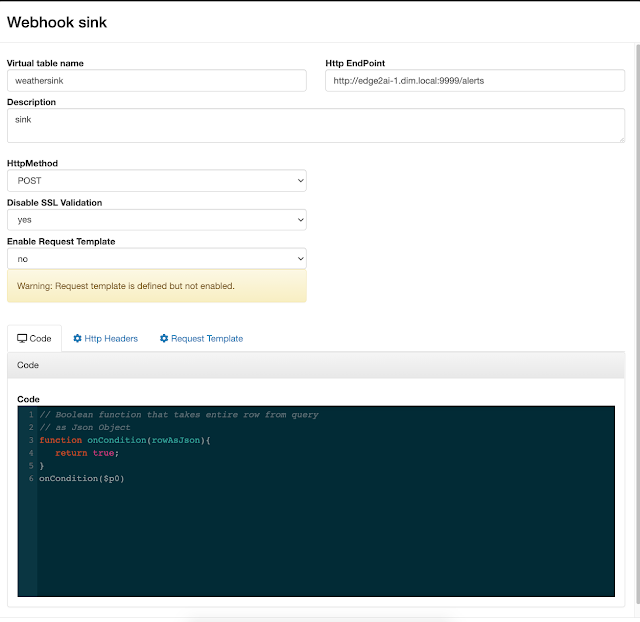
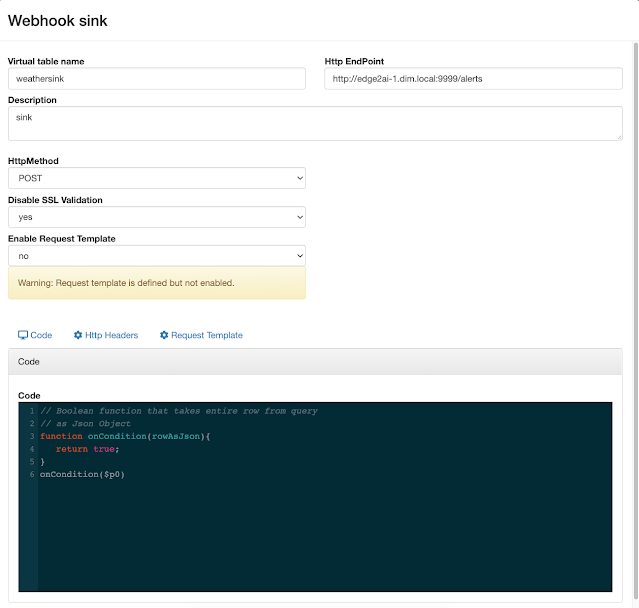
References:
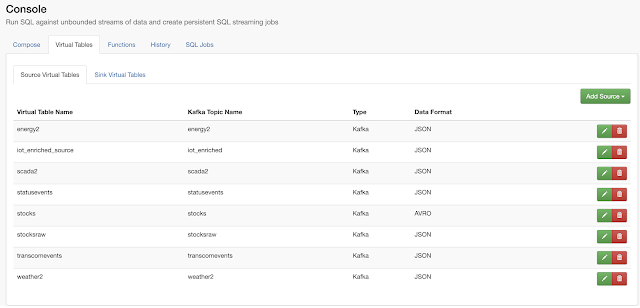
- https://docs.cloudera.com/csa/1.3.0/ssb-using-ssb/topics/csa-ssb-using-virtual-tables.html
- https://docs.cloudera.com/csa/1.3.0/ssb-overview/topics/csa-ssb-intro.html
- https://docs.cloudera.com/csa/1.3.0/ssb-overview/topics/csa-ssb-key-features.html
- https://docs.cloudera.com/csa/1.3.0/ssb-overview/topics/csa-ssb-architecture.html
- https://docs.cloudera.com/csa/1.3.0/ssb-quickstart/topics/csa-ssb-quickstart.html
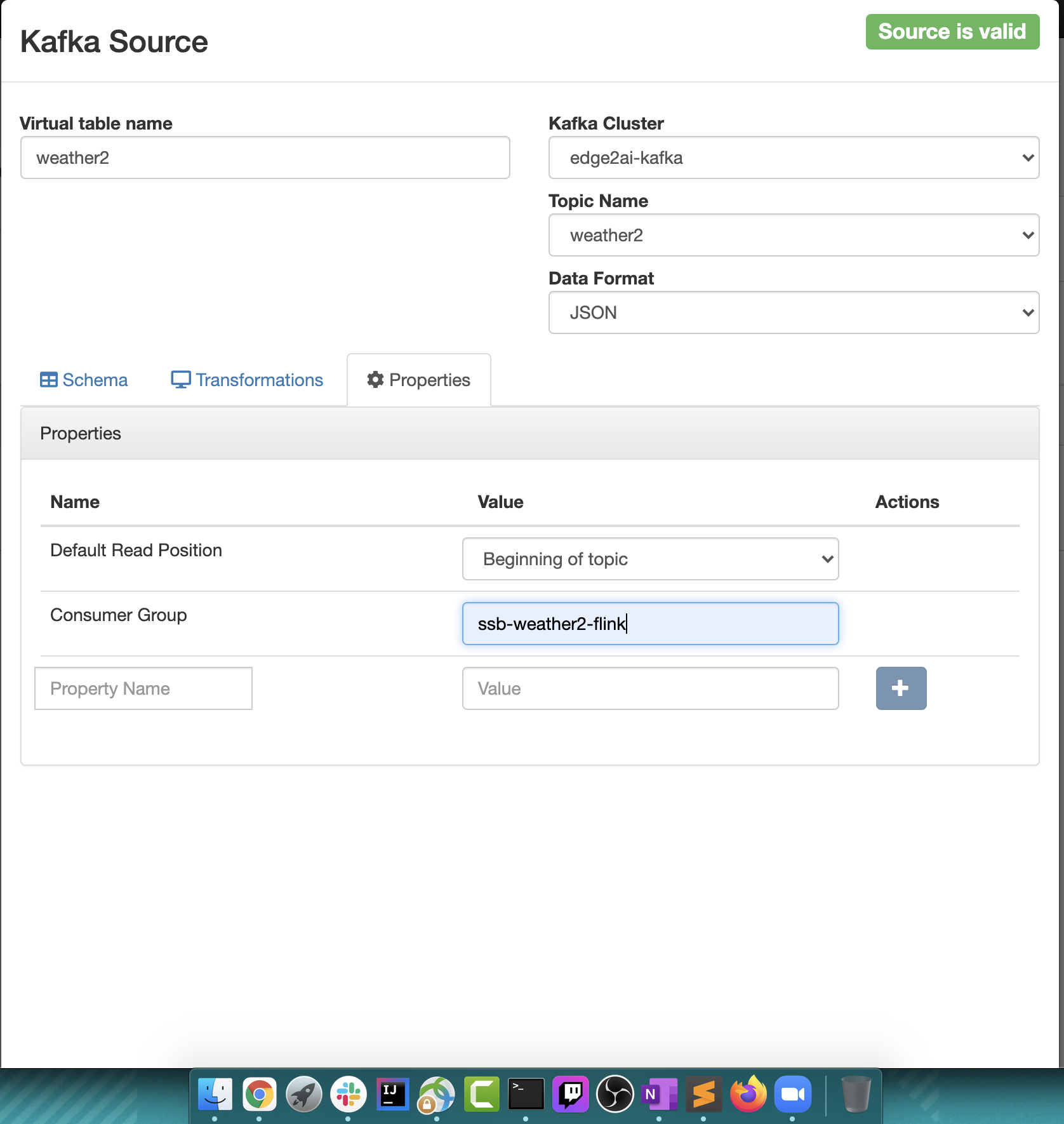
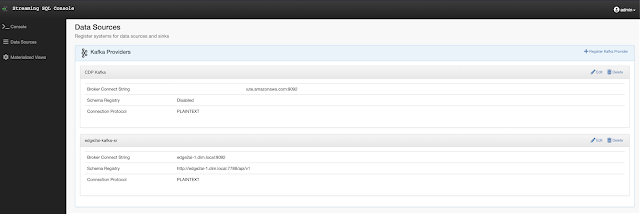
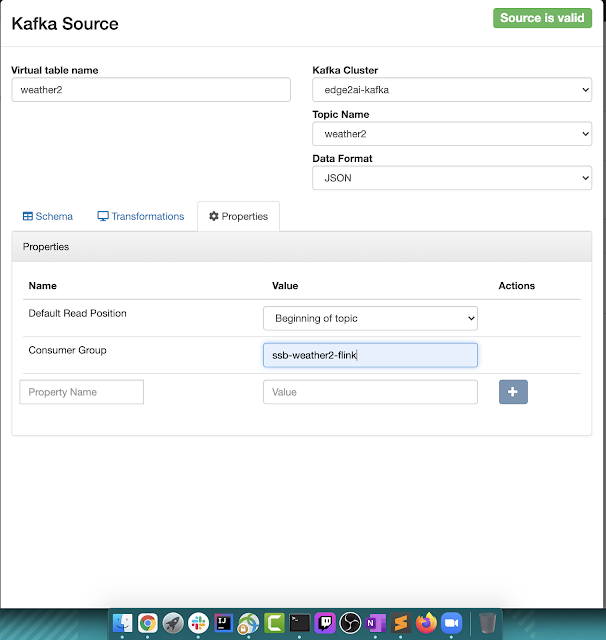
- https://docs.cloudera.com/csa/1.3.0/ssb-using-ssb/topics/csa-ssb-adding-kafka-data-source.html
- https://docs.cloudera.com/csa/1.3.0/ssb-using-ssb/topics/csa-ssb-using-virtual-tables.html
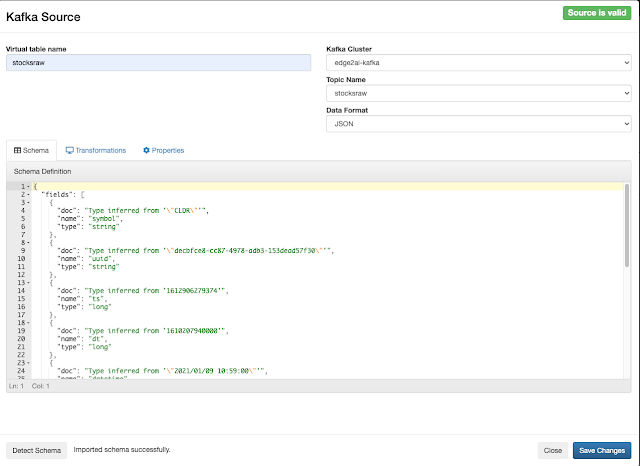
- https://docs.cloudera.com/csa/1.3.0/ssb-using-ssb/topics/csa-ssb-creating-virtual-kafka-source.html
- https://docs.cloudera.com/csa/1.3.0/ssb-using-ssb/topics/csa-ssb-creating-virtual-kafka-sink.html
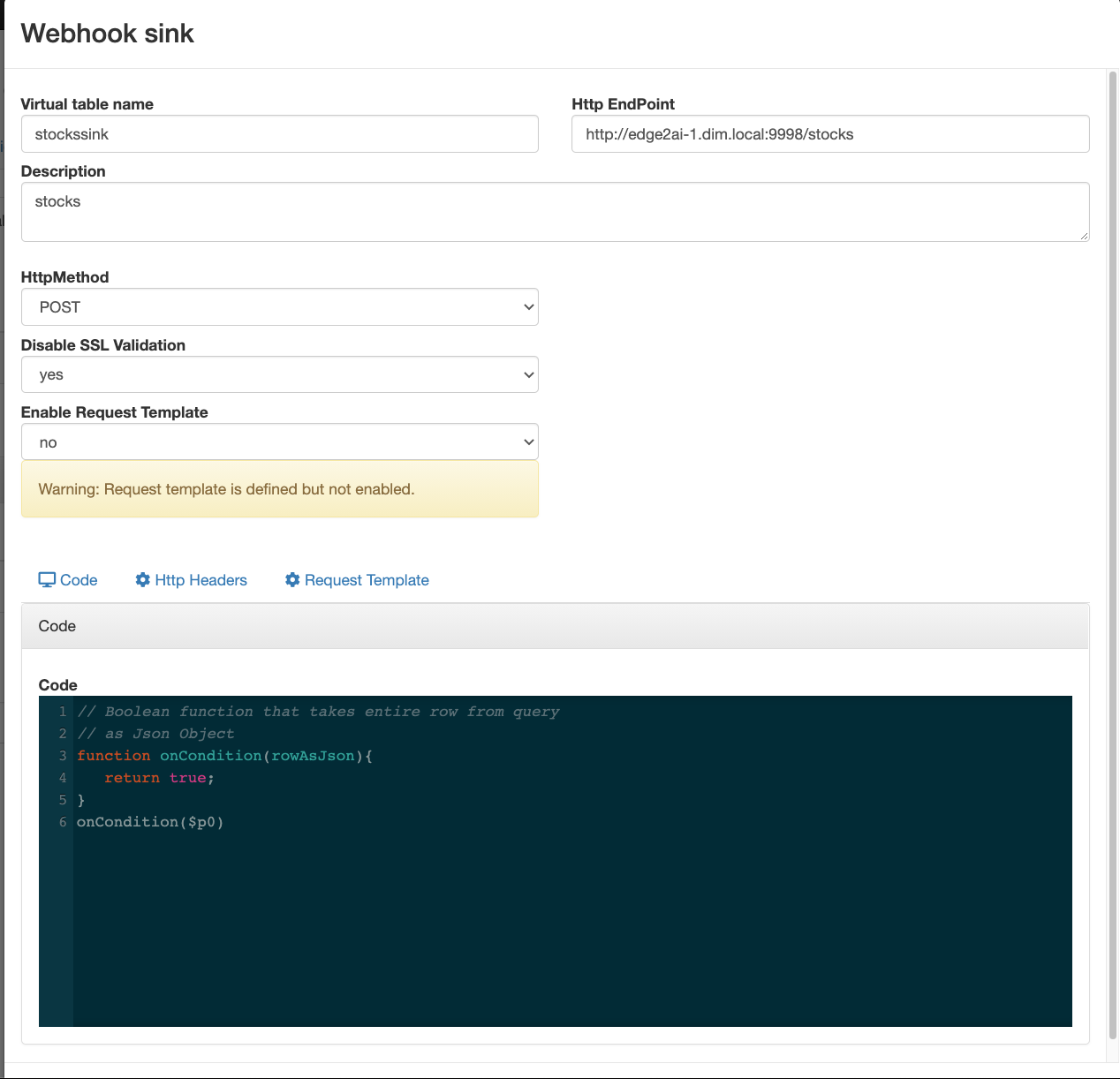
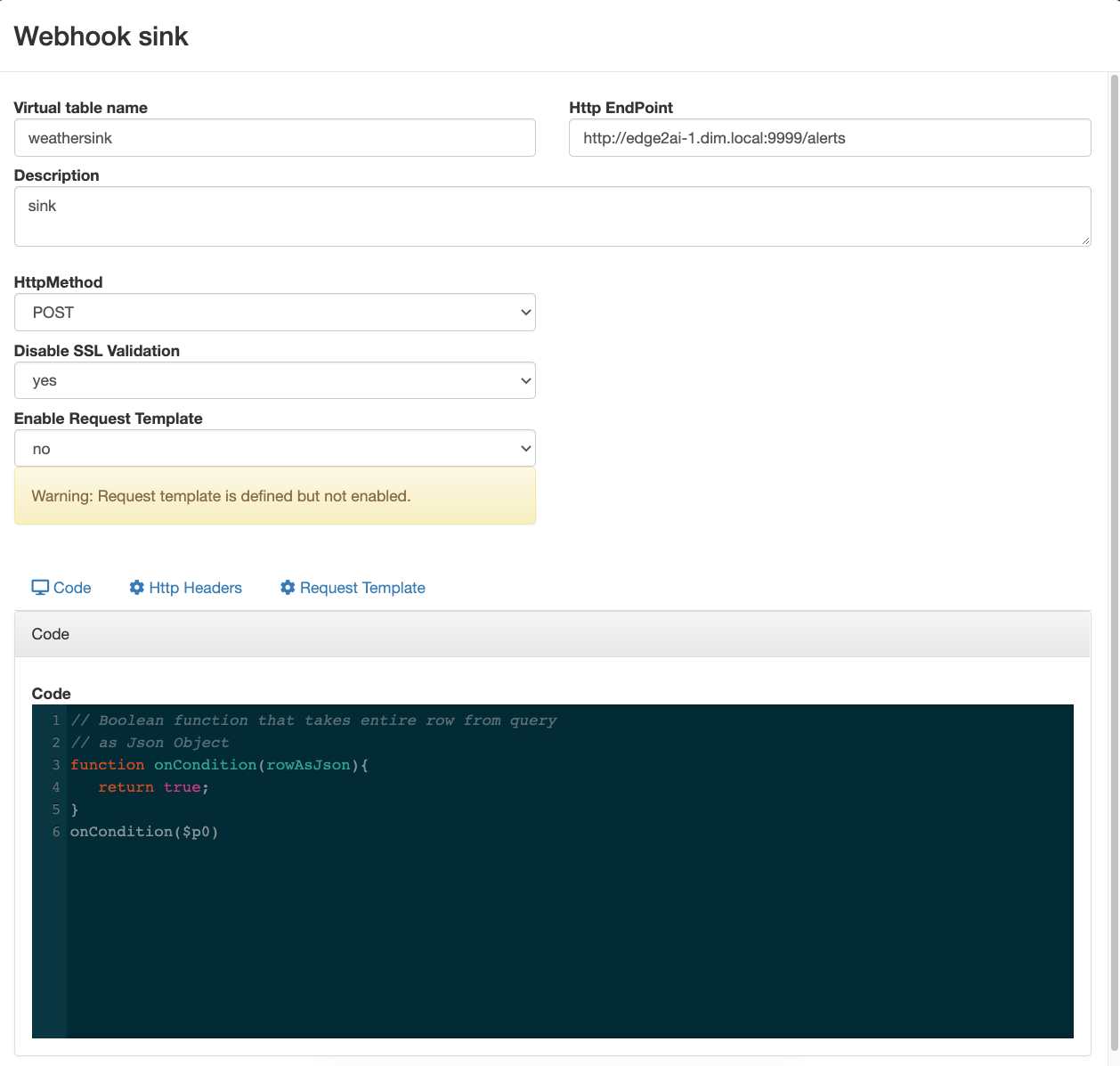
- https://docs.cloudera.com/csa/1.3.0/ssb-using-ssb/topics/csa-ssb-creating-virtual-webhook-sink.html
- https://docs.cloudera.com/csa/1.3.0/ssb-using-ssb/topics/csa-ssb-managing-time.html
- https://docs.cloudera.com/csa/1.3.0/ssb-job-lifecycle/topics/csa-ssb-running-job-process.html
- https://docs.cloudera.com/csa/1.3.0/ssb-job-lifecycle/topics/csa-ssb-job-management.html
- https://docs.cloudera.com/csa/1.3.0/ssb-job-lifecycle/topics/csa-ssb-sampling-data.html
- https://docs.cloudera.com/csa/1.3.0/ssb-job-lifecycle/topics/csa-ssb-advanced-job-management.html
- https://docs.cloudera.com/csa/1.3.0/ssb-using-mv/topics/csa-ssb-using-mvs.html
- https://www.cloudera.com/content/www/en-us/about/events/webinars/cloudera-sqlstream-builder.html
- https://www.cloudera.com/about/events/webinars/demo-jam-live-expands-nifi-kafka-flink.html
- https://www.cloudera.com/about/events/virtual-events/cloudera-emerging-technology-day.html
Published at DZone with permission of Tim Spann. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments