JWT Token Revocation: Centralized Control vs. Distributed Kafka Handling
In this article, we'll explore how different methods, such as centralized control and distributed Kafka handling, play a vital role in keeping your systems and data safe.
Join the DZone community and get the full member experience.
Join For FreeTokens are essential for secure digital access, but what if you need to revoke them? Despite our best efforts, there are times when tokens can be compromised. This may occur due to coding errors, accidental logging, zero-day vulnerabilities, and other factors. Token revocation is a critical aspect of modern security, ensuring that access remains in the right hands and unauthorized users are kept out. In this article, we'll explore how different methods, such as centralized control and distributed Kafka handling, play a vital role in keeping your systems and data safe.
Access/Refresh Tokens
I described more about using JWTs in this article. JWTs allow you to eliminate the use of centralized token storage and verify tokens in the middleware layer of each microservice.
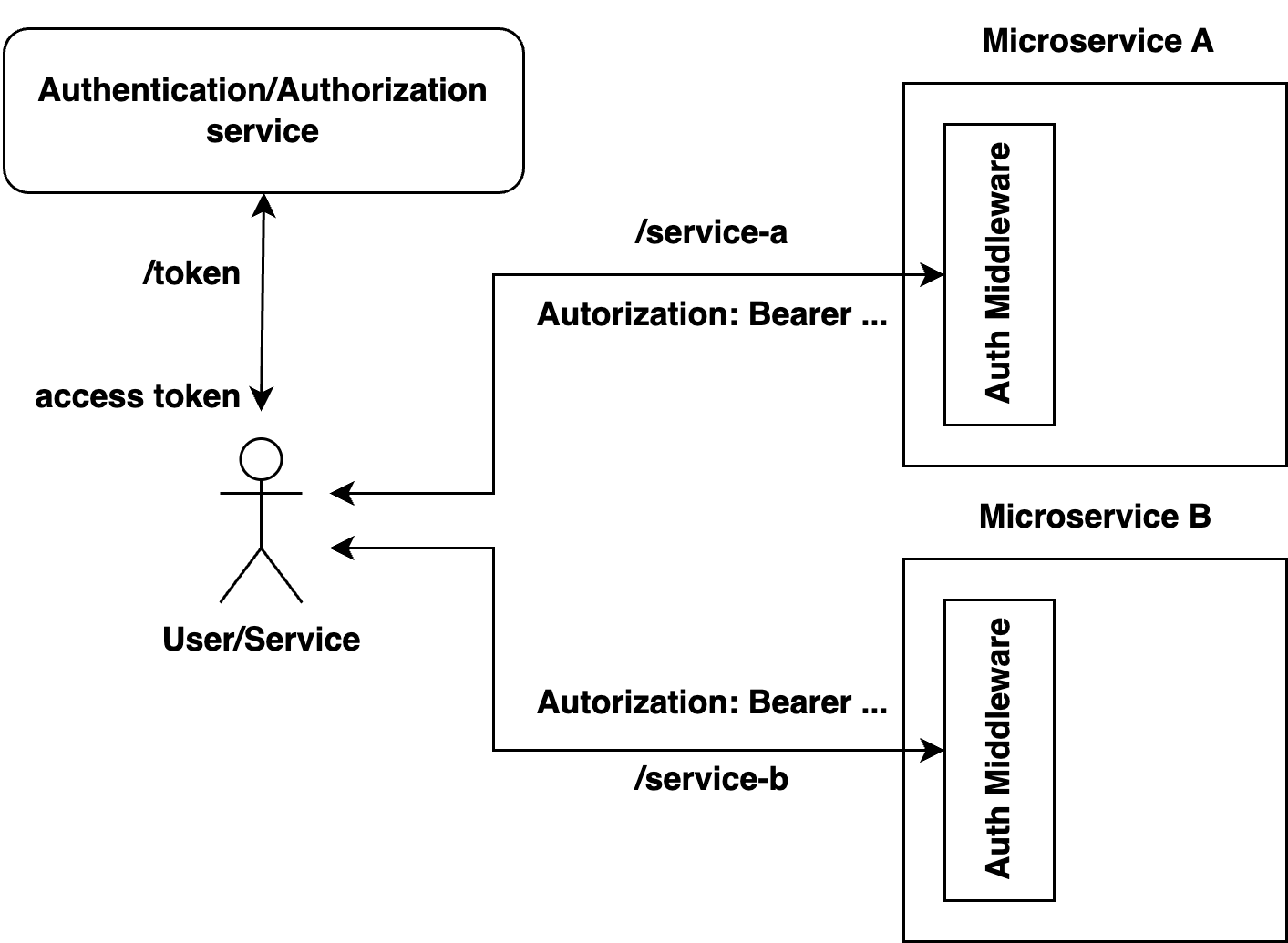
To mitigate the risks associated with token compromises, the lifetime of an Access Token is made equal to a small value of time (e.g., 15 minutes). In the worst case, after the token is leaked, it is valid for another 15 minutes, after which its exp will be less than the current time, and the token will be rejected by any microservice.
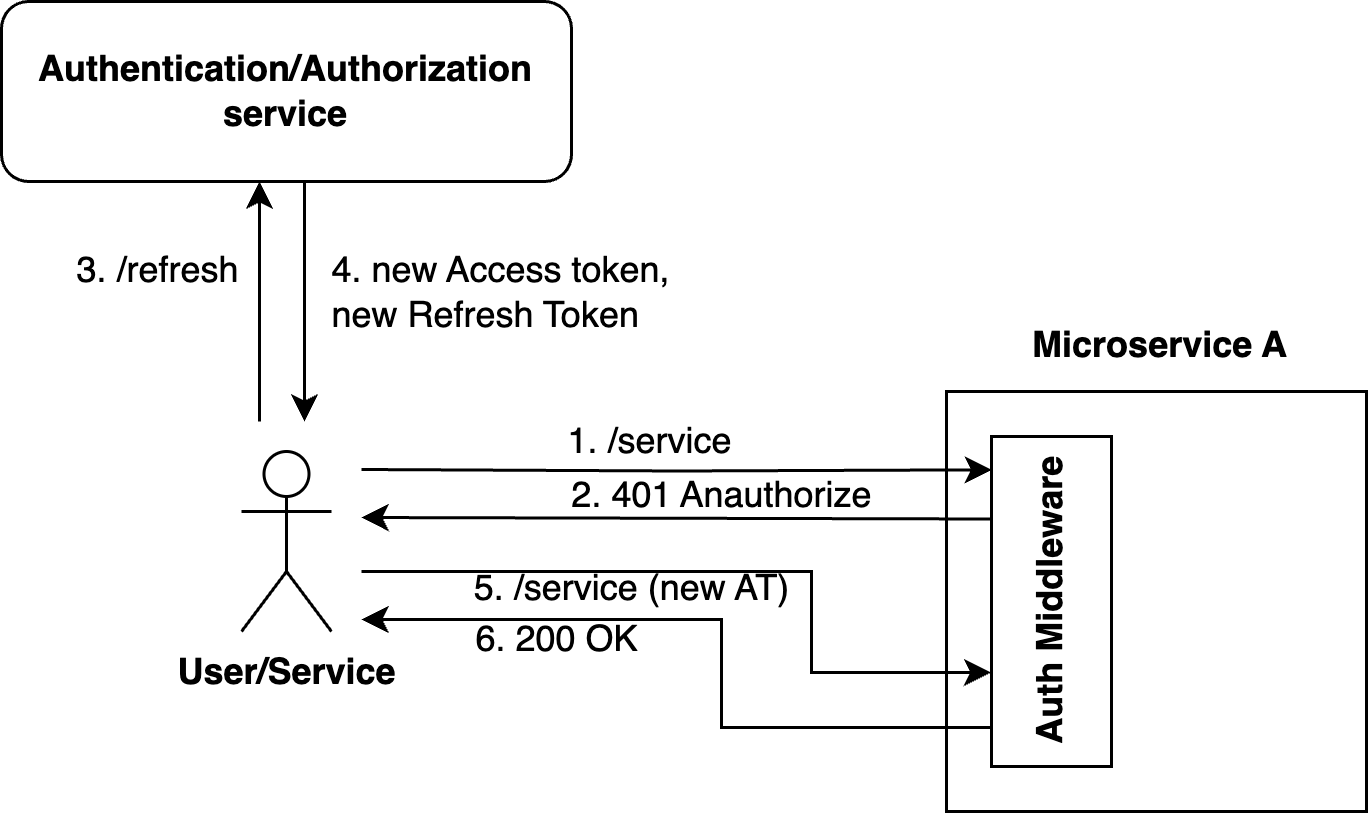
To prevent users from being logged out every 15 minutes, a Refresh Token is added to the Access Token. This way, the user receives an Access Token/Refresh Token pair after successful authentication. When the Access Token's lifetime expires and the user receives a 401 Unauthorized response, they should request the /refresh-token endpoint, passing the Refresh Token value as a parameter and receiving a new Access Token/Refresh Token pair in response. The previous Refresh Token becomes inactive. This process reduces risk and does not negatively impact user experience.
Revocation
But there are cases when it is necessary to revoke tokens instantly. This can happen in financial services or, for example, in a user's account when he wants to log out from all devices. Here, we can't do it without token revocation. But how to implement a mechanism for revoking JWTs, which are by nature decentralized and stored on the user's devices?
Centralized-Approach
The most obvious and easiest way is to organize a centralized storage. It will be a blacklist of tokens, and each auth middleware layer will, besides signature validation and verification of token claims, go to this centralized repository to check whether the token is in the blacklist. And if it is, reject it. The token revocation event itself is quite rare (compared to the number of authorization requests), so the blacklist will be small. Moreover, there is no point in storing tokens in the database forever since they have an exp claim, and after this value, they will no longer be valid. If a token in your system is issued with a lifetime of 30 minutes, then you can store revoked tokens in the database for 30 minutes.

Advantages
- Simplicity: This approach simplifies token revocation management compared to other solutions.
- Fine-grained control: You have fine-grained control over which tokens are revoked and when.
Considerations
- Single point of failure: The centralized token revocation service can become a single point of failure. You should implement redundancy or failover mechanisms to mitigate this risk.
- Network overhead: Microservices need to communicate with the central service, which can introduce network overhead. Consider the impact on latency and design accordingly.
- Security: Ensure that the central token revocation service is securely implemented and protected against unauthorized access.
This approach offers centralized control and simplicity in token revocation management, which can be beneficial for certain use cases, especially when fine-grained control over revocation is required. However, it does introduce some network communication overhead and requires careful consideration of security and redundancy.
Decentralized-Approach (Kafka-Based)
A more advanced approach, without a single point of failure, can be implemented with Kafka. Kafka is a distributed and reliable message log by nature. It permits multiple independent listeners and retention policy configurations to store only actual values. Consequently, a blacklist of revoked tokens can be stored in Kafka. When a token requires revocation, the corresponding service generates an event and adds it to Kafka. Middleware services include a Kafka listener that receives this event and stores it in memory. When authorizing a request, in addition to verifying the token's validity, there is no need to contact a centralized service. Revoked tokens are stored in memory, and locating the token in a suitable data structure is a quick process (if we use HashMap, it will be O(1)). It's unnecessary to store tokens in memory forever either, and they should be periodically deleted after their lifetime.
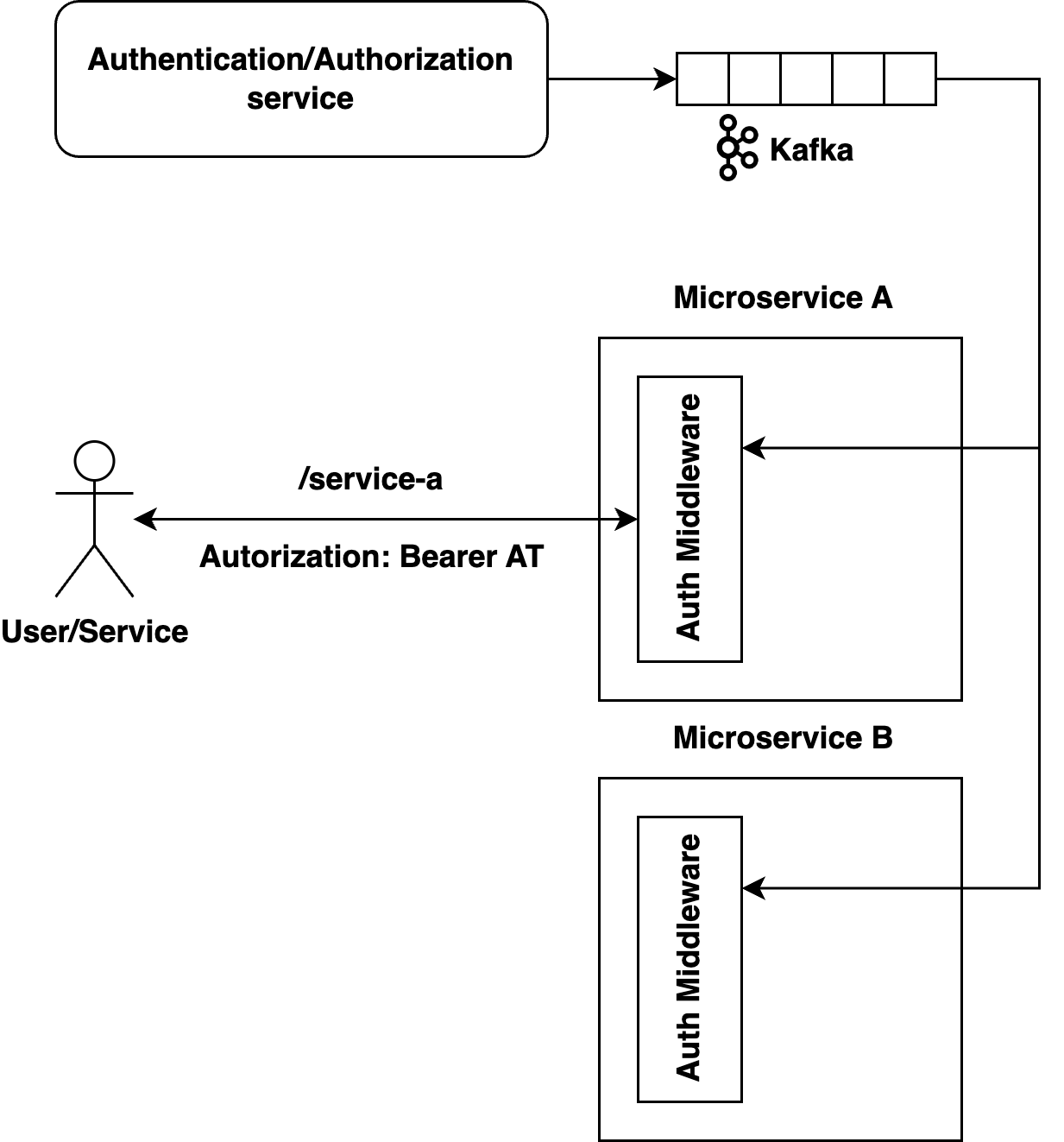
But what if our service restarts and memory is cleared? The Kafka listener allows you to read messages from the beginning. When the microservice is brought back up, it will once again pull all messages from Kafka and use the actual blacklist.
Advantages
- Decentralized: Using a distributed message broker like Kafka allows you to implement token revocation in a decentralized manner. Microservices can independently subscribe to the revocation messages without relying on a central authority.
- Scalability: Kafka is designed for high throughput and scalability. It can handle a large volume of messages, making it suitable for managing token revocations across microservices in a distributed system.
- Durability: Kafka retains messages for a configurable retention period. This ensures that revoked tokens are stored long enough to cover their validity period.
- Resilience: The approach allows microservices to handle token revocation even if they restart or experience temporary downtime. They can simply re-consume the Kafka messages upon recovery.
Considerations
- Complexity: Implementing token revocation with Kafka adds complexity to your system. You need to ensure that all microservices correctly handle Kafka topics, subscribe to revocation messages, and manage in-memory token revocation lists.
- Latency: There might be a slight latency between the time a token is revoked and the time when microservices consume and process the revocation message. During this window, a revoked token could still be accepted.
- Scalability challenges: As your system grows, managing a large number of revocation messages and in-memory lists across multiple microservices can become challenging. You might need to consider more advanced strategies for partitioning and managing Kafka topics.
The choice between the centralized token revocation approach and the Kafka-based approach depends on your specific use case, system complexity, and preferences. The centralized approach offers simplicity and fine-grained control but introduces network overhead and potential single points of failure. The Kafka-based approach provides decentralization, scalability, and resilience but is more complex to implement and maintain.
Conclusion
In a world where digital security is paramount, token revocation stands as a critical defense. Whether you prefer centralized control or the distributed handling of Kafka, the core message remains clear: Token revocation is a vital part of robust security. By effectively managing and revoking tokens, organizations can fortify their defenses, safeguard sensitive data, and ensure that access remains in the right hands. As we wrap up our discussion on token revocation, remember that proactive security measures are a must in today's digital landscape. So, embrace token revocation to protect what matters most in our interconnected world.
Opinions expressed by DZone contributors are their own.
Comments