Designing a Production-Grade Multi-Agent LLM Architecture for Structured Data Extraction
Find out how a multi-agent LLM system overcomes the unreliability of single-LLM extraction when processing large volumes of documents for structured data.
Join the DZone community and get the full member experience.
Join For FreeProblem statement:
Many enterprise systems rely on large volumes of documents that are similar in purpose but inconsistent in structure. For example, in the field of medicare insurance, different carriers, vendors, or partners publish documents describing comparable offerings, but each uses its own format, terminology, layouts, unstructured conditional clauses, etc.
Many of these documents also contain tables, but are of different structures, sometimes within the same page. Another problem to call out is year-over-year and location-to-location variation, such as by state, county, and ZIP code.
As a result, critical data is trapped in these documents, which require extensive manual review. Traditional rule-based parsers break with eventual formatting shifts and need extensive code deployments, tests, and releases. Regex-based approaches fail under real-world conditions and need constant maintenance. In fact, when scaling, even a single prompt (per document) LLM extraction fails and would work only for proof of concepts or demos.
This is where a multi-agent LLM architecture becomes necessary.
Why Single Agent LLM Extraction Fails
A single agent would probably work for 5 documents, but it won’t work for 5,000. Some of the common failures which I’ve observed:
- Hallucinated values for missing fields
- Context window limits causing incorrect outcomes
- No reliable confidence signal
- Automatic assumptions in outcomes from previous memory
In high-impact production environments, silent errors can be worse than explicit failures. With the probabilistic outcomes, there is also a need for deterministic guardrails.
The solution is not just refined prompt engineering, but it is profound architectural decomposition, a mix of core software engineering tightly coupled with AI engineering.
System Architecture Overview
The system decomposes responsibilities into independent agents.
PDF → Preprocessing → Extraction Agent → Validation Layer → Judge Agent → Structured Output
Design Principles
- Separation of concerns
- Strict schema contracts
- Deterministic QA before acceptance
- Confidence scoring and Judging
- Human in the loop feedback for low confidence judging
- Observability metrics
Each agent has a detailed and defined scope, thus increasing reliability
Deployment Context and Infrastructure
The architecture is deployed as a set of lightweight services rather than a single monolithic script. Each stage in the pipeline runs independently and communicates through structured JSON messages. This allows the system to scale horizontally when document volume increases.
In a production environment, the pipeline would run on:
- A containerized backend (Docker-based deployment)
- A queue-based processing system (For processing asynchronously)
- A storage layer for processing and versioning
- A structured output store — database
This setup allows multiple documents to be processed simultaneously without blocking the system. If the extraction agent fails on one document, it does not interrupt the processing of others.
Extraction Agent
The extraction agent’s sole responsibility is to convert document chunks into structured JSON that adheres to the predefined schema.
Key design decisions include:
- Low temperature
- Explicit JSON schema enforcement
- Chunk-level semantic segmentation
- Carrier/partner agnostic prompt design
Chunking is important here, as a fixed-length token system breaks logical sections. Instead, variable chunking via semantic segmentation improves accuracy. The final RAG-based system is designed to be dynamic, allowing the extractor to look at the top few chunks as needed.
class ExtractionAgent:
def __init__(self, llm_client, prompt_template, schema: dict):
self.llm = llm_client
self.prompts = prompt_template
self.schema = schema
def run(self, chunks: list[str]) -> dict:
prompt = self.prompts.build_extraction_prompt(chunks)
response = self.llm.generate(
prompt=prompt,
temperature=0.0,
response_schema=self.schema
)
return responseThe output contract is strict and is sent for further validation. No validation is performed by the Extraction Agent.
Validation Agent
We divided validation into two parts, a hybrid approach.
- Deterministic validation: This enforces JSON Schema integrity, required vs. optional fields, basic QA checks such as data types, range checks, NULLs, etc. All of these are to ensure structural correctness, which is most often tightly coupled with end-user UI.
- Contextual LLM validation: A second LLM pass compares the extracted output with the original documented text. Its role is primarily to detect mismatches between extracted values and the source. It would identify, flag, and correct hallucinated and missing entries.
class ValidationAgent:
def __init__(self, llm_client, prompt_template):
self.llm = llm_client
self.prompts = prompt_template
def validate(self, extracted: dict, source_chunks: list[str]) -> dict:
deterministic = self._deterministic_checks(extracted)
contextual_prompt = self.prompts.build_validation_prompt(
extracted,
source_chunks
)
contextual = self.llm.generate(
prompt=contextual_prompt,
temperature=0.0
)
return {
"deterministic": deterministic,
"contextual": contextual
}
def _deterministic_checks(self, extracted: dict) -> dict:
errors = []
if "plan_name" not in extracted:
errors.append("Missing required field: plan_name")
for item in extracted.get("benefits", []):
if isinstance(item.get("copay"), (int, float)) and item["copay"] < 0:
errors.append("Invalid negative copay detected")
return {
"valid": len(errors) == 0,
"errors": errors
}Judge Agent
Even after validation, the system needs a decision layer. Here comes the Judge Agent, which receives the extracted output, validation results, and findings, and produces a confidence score, classifies the error, and performs a final decision.
During judging, confidence thresholds are bucketed and calibrated against historical datasets that are already processed. This helps transform the output into outcomes that can be tracked and improved operationally.
An additional context here — it is important to build the extraction agent and validation agent with two different state-of-the-art LLMs.
The judging LLM would also be a different model from the ones used for Extraction and Validation.
class JudgeAgent:
def __init__(self, llm_client, prompt_template, threshold: float = 0.85):
self.llm = llm_client
self.prompts = prompt_template
self.threshold = threshold
def evaluate(self, validation_result: dict) -> dict:
prompt = self.prompts.build_judge_prompt(validation_result)
judgment = self.llm.generate(
prompt=prompt,
temperature=0.0
)
confidence = judgment.get("confidence_score", 0.0)
if confidence >= self.threshold:
status = "PASS"
elif confidence >= 0.6:
status = "REVIEW"
else:
status = "FAIL"
return {
"confidence": confidence,
"status": status,
"details": judgment
}
Prompt Engineering and Variability Handling
In a production-level GenAI system, prompt engineering must be treated like software development, with prompts version-controlled, reusable, and benchmarked against golden historical datasets. As document formats evolve, there can be a degradation in the accuracy of prompts unless they are continuously evaluated. Build a strong, generic base prompt and include custom prompts for specific carriers derived from historical datasets.
class PromptTemplate:
def __init__(self, version: str):
self.version = version
def build_extraction_prompt(self, chunks: list[str]) -> str:
return f"""
You are an expert structured data extraction system.
TASK:
Extract all relevant fields according to the JSON schema.
Do NOT infer missing values.
Preserve numeric fidelity.
Include conditional clauses exactly as written.
DOCUMENT CONTENT:
{self._format_chunks(chunks)}
Return ONLY valid JSON.
Prompt-Version: {self.version}
"""
def build_validation_prompt(self, extracted: dict, source: list[str]) -> str:
return f"""
Compare the extracted structured output with the source document.
Identify:
- Hallucinated values
- Missing fields
- Numeric mismatches
- Logical inconsistencies
Extracted:
{extracted}
Source:
{self._format_chunks(source)}
Return validation findings in structured JSON.
"""
def build_judge_prompt(self, validation_result: dict) -> str:
return f"""
Based on the validation findings, assign:
- Confidence score (0.0 - 1.0)
- Error category (none/minor/major)
- Final decision (PASS/REVIEW/FAIL)
Validation Result:
{validation_result}
Return structured JSON only.
"""
def _format_chunks(self, chunks: list[str]) -> str:
return "\n\n".join(chunks)Because document variability is unavoidable, architectures must assume entropy rather than optimizing for ideal inputs. Adaptive chunking, partner-aware prompt conditioning, and nested logic all play a profound role.
Plan Benefit Example: Inpatient Services
Input excerpt from plan document: A section of an insurance document stating: "For Inpatient Hospital Services, a 20% Coinsurance applies after the annual deductible of $500 is met. This Coinsurance is capped at a maximum of $5,000 out-of-pocket per calendar year."
Extraction Agent Output (Excerpt):
{ "deductible_in_network": 500,
"inpatient_coinsurance_rate": 0.20,
"inpatient_service_type": "Hospital Services",
"coinsurance_condition": "annual deductible of $500 is met",
"max_out_of_pocket_inpatient": 5000 }Validation Agent result:
- Deterministic check: PASS (All required fields present. inpatient_coinsurance_rate is a float between 0.0 and 1.0. max_out_of_pocket_inpatient is a positive integer).
- Contextual check: PASS (The LLM confirms the $5,000 cap is correctly associated with the inpatient coinsurance, and the conditional trigger for the coinsurance is accurately captured).
Judge Agent decision: Confidence: 0.95, Status: PASS.
Observability and cost in production:
Key metrics for the system include, but are not limited to:
- Extraction success rate
- Validation failure rate
- Average confidence score (over time)
- Token usage per document and document type
Monitoring the confidence distribution using any industry-standard open-source Python module is the secret sauce that helps indicate prompt drift/regression, completely new and unexpected document structures, and errors.
Human-in-the-loop feedback needs to be accounted for, and building a simple UI that can perform actions like ignore or fix goes a long way toward usability.
For a cost optimization strategy in production, some foundational practices must be implemented.
- Batch processing with token observability
- Single-pass LLM for consistently defined structures
- Parallelization (which is easily achievable with reusable prompts and LLM REST APIs)
Overall Architecture
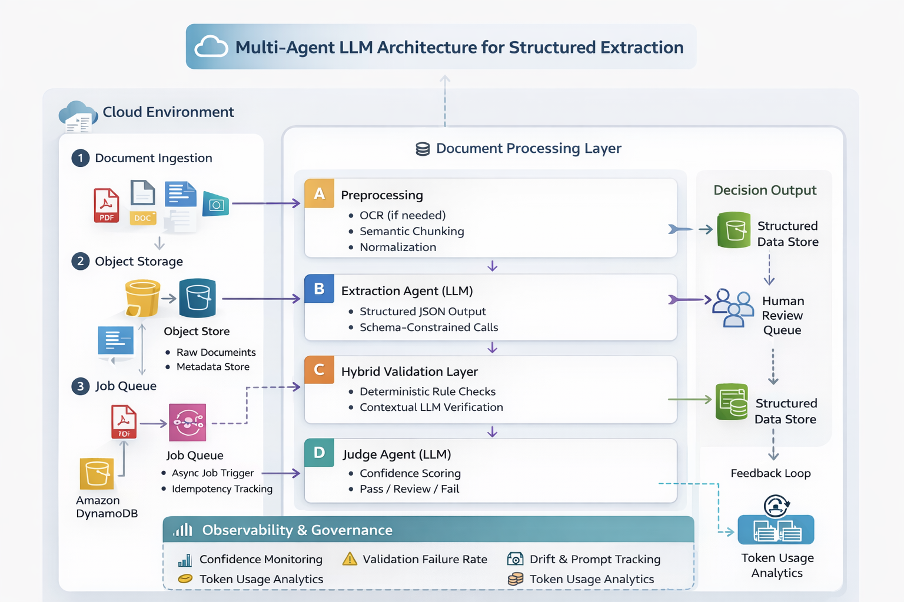
Conclusion
LLMs are powerful extraction tools, but without structure, they can lead to unstable or unexpected outcomes.
By decomposing responsibilities into extraction, validation, and judgment agents, and combining them with traditional approaches such as enforcing schema contracts, confidence scoring, etc., it becomes possible to transform ‘similar but also varying’ semi-structured documents from multiple inconsistent sources into reliable, structured data at scale.
The difference between a proof of concept and a production AI-based system is not the model but the architecture around it.
Opinions expressed by DZone contributors are their own.
Comments