Microservices and Kafka (Part One)
eBay classifieds microservices architecture blueprint.
Join the DZone community and get the full member experience.
Join For FreeApache Kafka is one of the most popular tools for microservice architectures. It’s an extremely powerful instrument in the microservices toolchain, which solves a variety of problems. At eBay Classifieds, we use Kafka in many places and we see commonalities that provide a blueprint for our architecture.
The Motors Vertical (or “MoVe”) from eBay Classifieds is a mobile-first marketplace for selling and buying cars in different markets. When we built the brand-new system for MoVe, we reused much of the existing knowledge from eBay Classifieds and implemented an architecture that would serve as a blueprint for classifieds microservice architecture with Kafka.
The initial problem to be solved with Kafka is how microservices should communicate with one another. As a classifieds marketplace connects buyers and sellers, the very first microservices communication example is how seller listings will become available and searchable for the potential buyers.
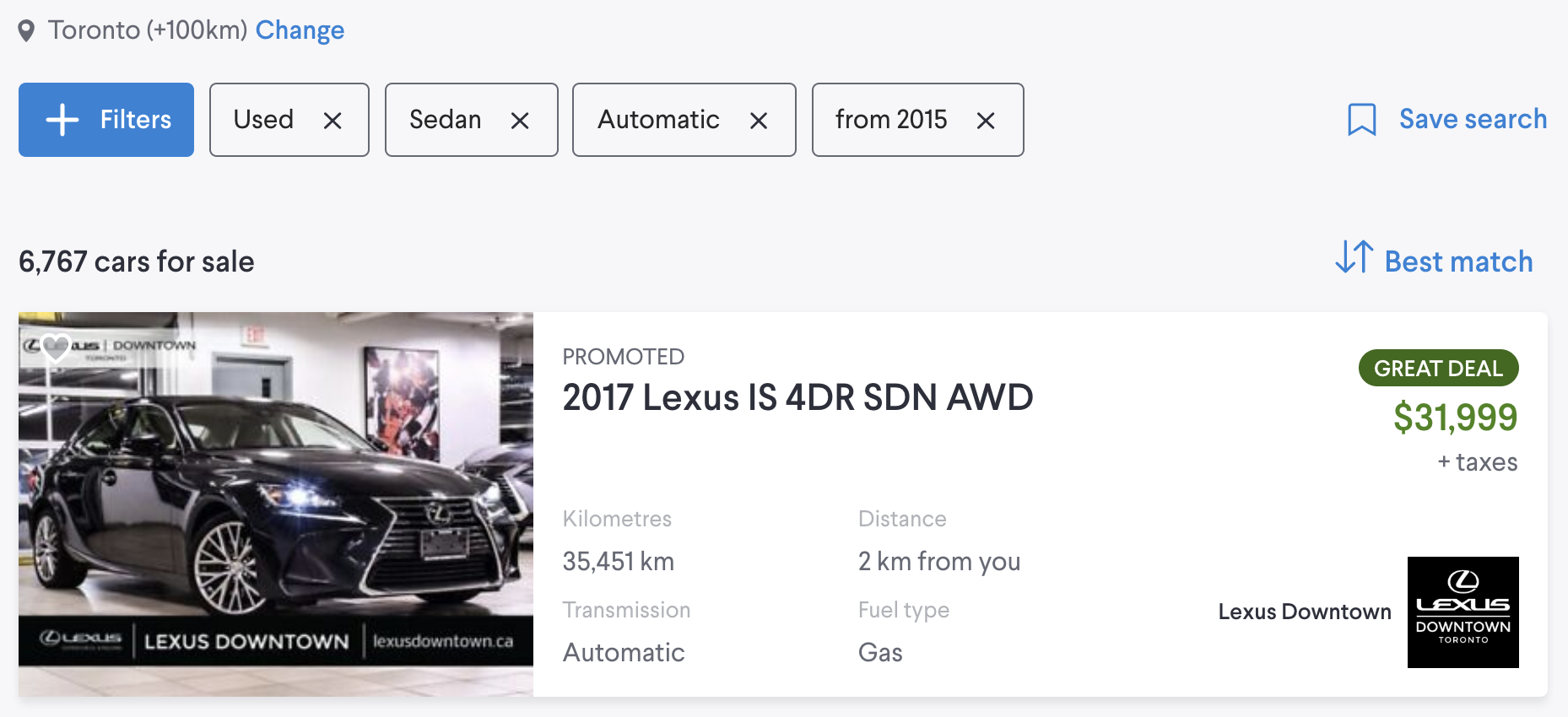
There are many ways to solve this, but in a Kafka-based architecture, we use a Kafka topic. The seller service responsible for handling seller use-cases would send listings to the listing service responsible for the buyer search experience.
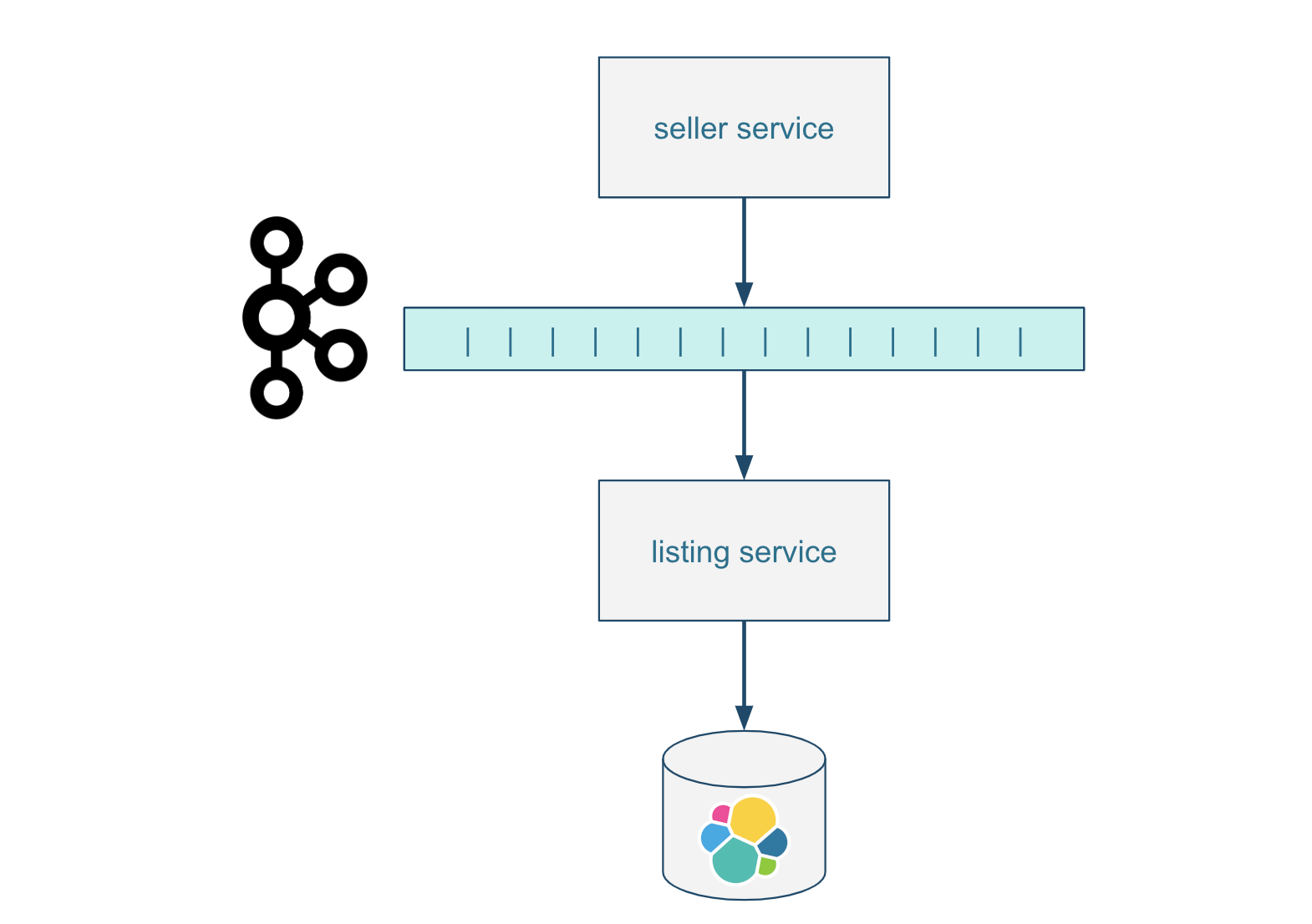
Relying on Kafka Topics for Storage
In this example, Kafka topics are the way services communicate with each other, but they offer more. Topics can be configured to always keep the latest message for each key. This is known as topic compaction. In our example, the listings topic always contains the latest state of each listing until it is deleted with a special tombstone message.
This way Kafka topics provide more than just communication between services. They are effectively a data storage mechanism that can be accessed and processed sequentially by one or more services. You can reap the benefits of an Event Sourcing architecture and reprocess events whenever needed.
For example, a listing service might want to reprocess events from a listings topic when the read model evolves to an extent that requires rebuilding the listing service datastore index or collection completely.
Relying on Kafka for System State
Real-life Kafka microservices are more complex. The real listing consists of many attributes in addition to those provided by sellers. For example, it might contain additional information on whether the listing should be promoted higher in search results as a paid feature. Another use-case is data enrichment by various services, such as a calculated price rating evaluation that ranks each deal compared to similar offers.
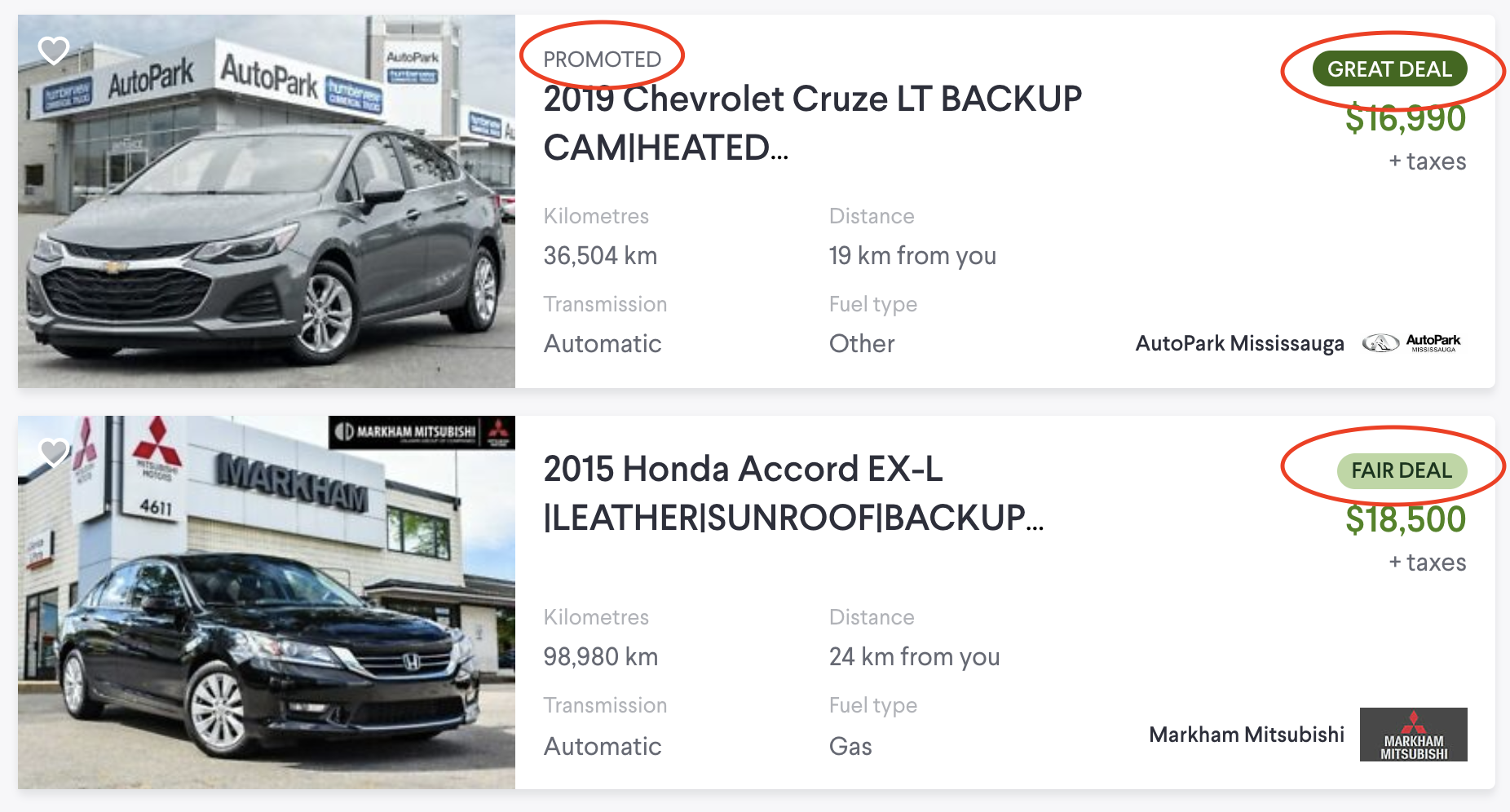
With these requirements, a microservice architecture might look like this:
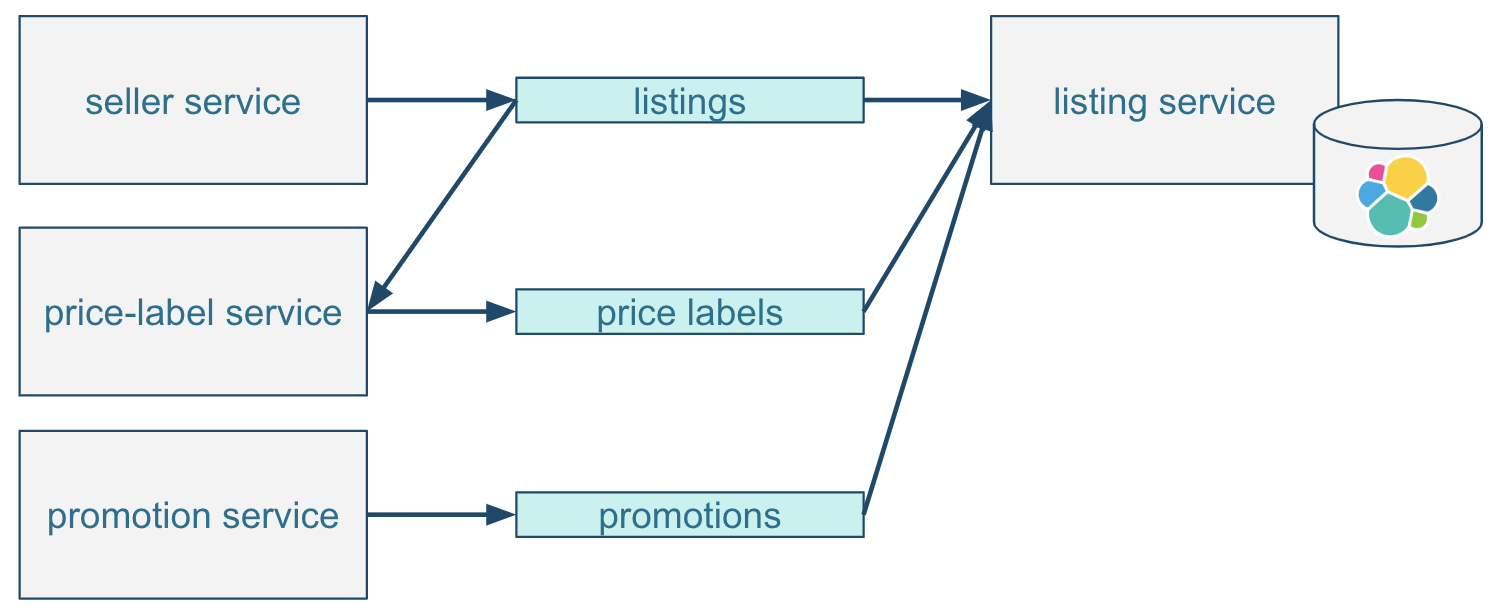
Additional price labels and promotions topics are similarly consumed by the listing service as listings. With Kafka’s support for multiple consumer groups, the price label service would also consume the listings topic to evaluate prices based on listing data.
Evolving the system further, if any other service is interested in data that is already distributed via Kafka topics, they can just consume the messages with a dedicated consumer group.
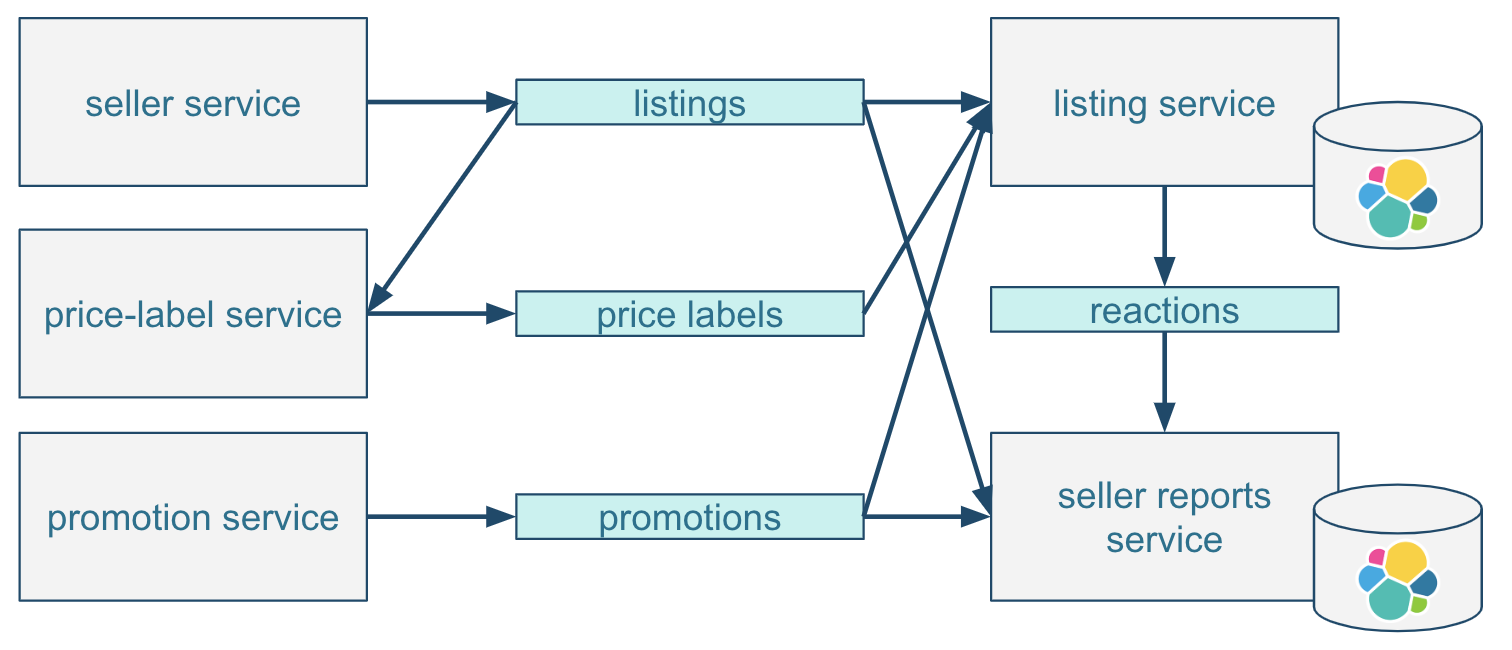
The example above includes a seller reports service, which consumes listings, promotions, and newly added reactions topics to give sellers an understanding of how their listings perform. In this example, listing and promotion data will be duplicated in both the listing service database and the seller reports service database. The source of truth remains Kafka topics.
Whenever data changes, both data views are updated independently. In this scenario, Kafka's topics can be treated as the “system state” and source of truth. If Kafka topics serve as the source of truth, the necessary durability guarantees need to be provided — such as data replication and backups. This is not something that Kafka offers out of the box (like a database) so it needs to be implemented separately.
Event-Driven Microservice Architecture Blueprint
The example above can be considered purely event-driven. There are no synchronous calls such as HTTP requests. All the communication goes through Kafka and messages in topics are domain events rather than just messages.
This approach can be generalized into a set of principles forming an architectural blueprint for building a microservices system.
- Favor event-first communication using Kafka topics and use synchronous logic via REST or other methods when appropriate.
- Use full-entity as the event body with Kafka topics compaction as opposed to sending partial updates or commands.
- Rely on Kafka topics as a durable source of truth.
- Build multiple read models for the same entity when required, and make sure the resulting eventual consistency aligns with business expectations.
- Design microservices to be able to reprocess compacted Kafka topics, rebuilding read models when required.
Finding Reasonable Boundaries for the Event-Driven Approach
Should we follow the blueprint to integrate systems and organizations with hundreds of engineers building hundreds of services?
Our advice for communicating asynchronously via Kafka also has its limitations. Sharing a Kafka cluster requires alignment on cluster usage and maintenance. Sharing a Kafka topic is not only about aligning on schema and data format. Did you know that Kafka Producer can specify the partition manually or a different partition implementation?
In addition to aligning the topics format, producer behavior, and replication set-up, you should also align on cluster upgrades, capacity and possible maintenance disruptions. In organizations where teams are not accustomed to sharing a common platform, that might be hard.
There are ways to integrate that require less alignment. RESTful HTTP APIs would be one example. A REST API mainly requires contract alignment and is better suited for integrating systems that are not controlled by the same organization. Sharing a Kafka cluster is less harmful than sharing a traditional database, but you may see some commonalities in the problem space it creates.
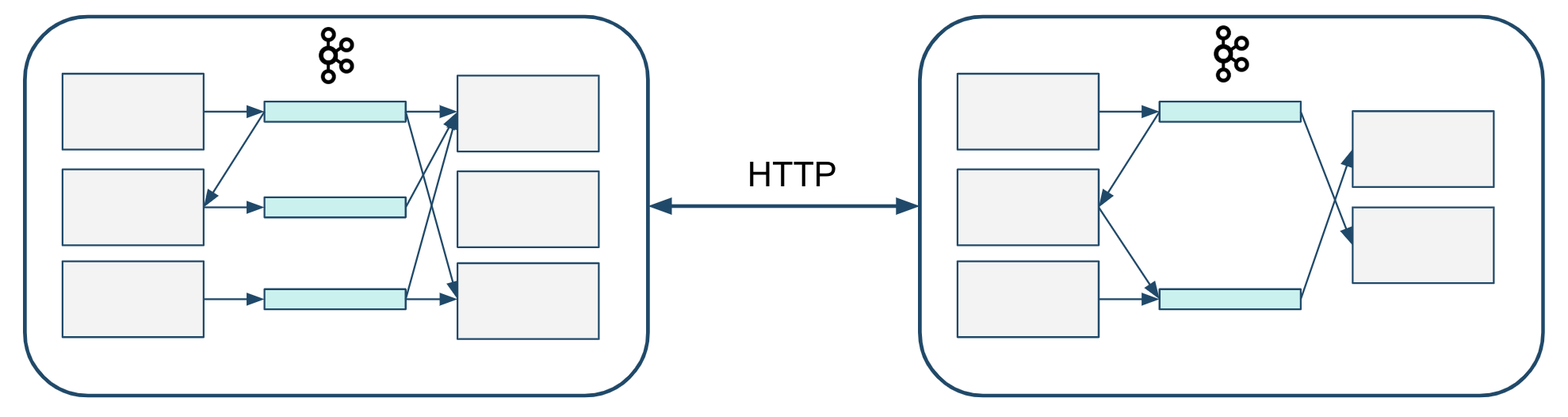
The lessons we learned and the balance we are trying to keep is to use a Kafka-based event-driven architecture in a single organization only. For integrating systems that are managed by different business units and locations, we prefer decoupling with HTTP APIs.
Further Reading
A Tutorial on Kafka With Spring Boot
A Kafka Tutorial for Everyone, no Matter Your Stage in Development
Published at DZone with permission of Grygoriy Gonchar. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments